目录
3.Unresolved Logic Plan 逻辑执行计划生成
4. Analyzed Logical Plan 逻辑执行计划生成
5.Optimized Logic Plan 逻辑执行计划生成
前文
Spark SQL以及Dataset体系在Spark中具有越来越重要的作用,基于RDD的体系正在被弱化,使用Dataset或者SQL编写的代码,甚至可以经过稍微修改之后迁移到Structure Streaming中进行执行。而且语法解析、语义解析和执行在很多地方也会被用到,比如规则引擎的解析和执行就可以基于语句来实现。

闲暇时间阅读了SparkSQL的一些书籍和资料,笔记如下。
正文
1.概述
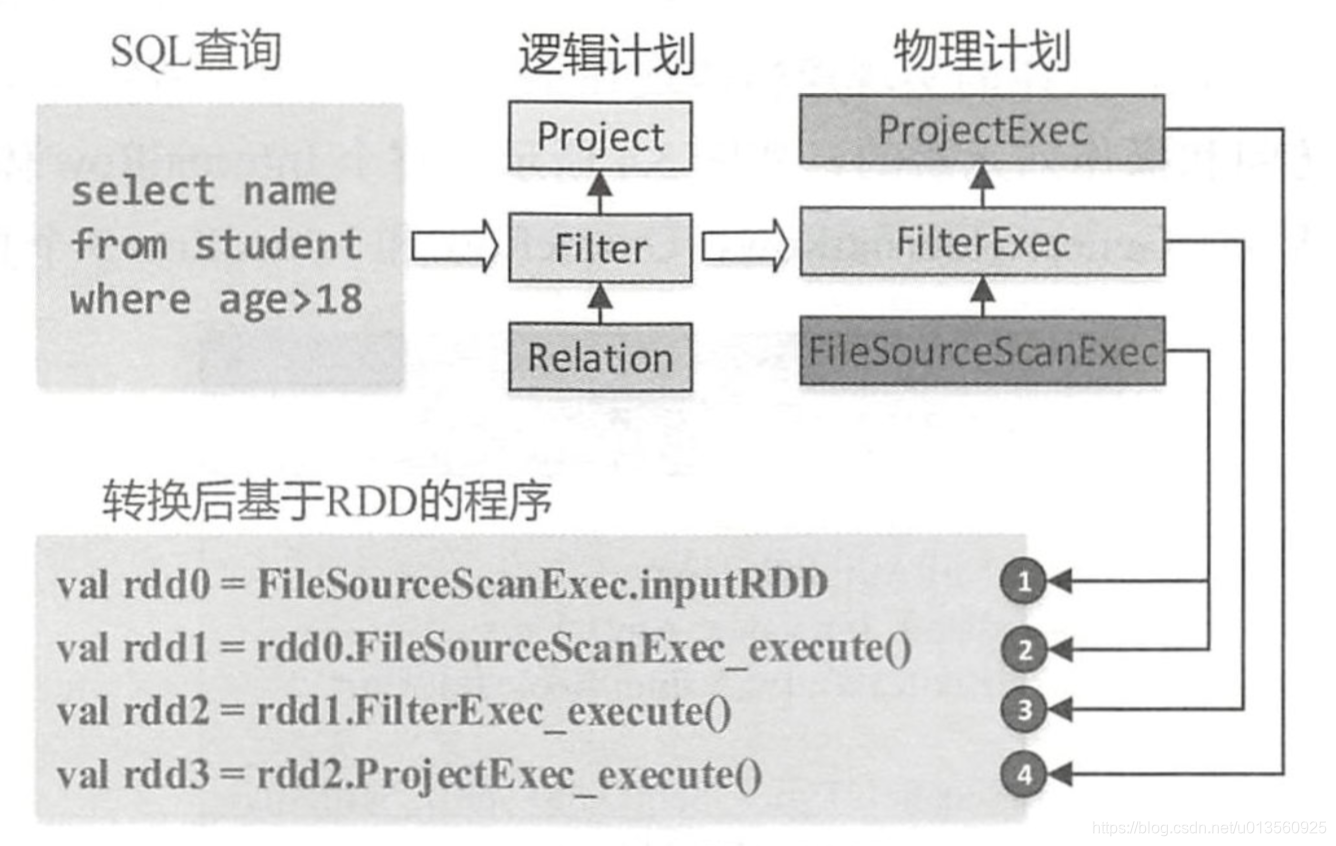
用户编写的SQL是无法直接被底层计算框架执行的,必须要经过几个转换阶段,转变成框架能够识别的代码或者类对象,在Spark中,一般需要经过以下几个步骤,分为逻辑执行计划部分和物理执行计划部分。
SQL Query,需要经过词法和语法解析,由字符串转换为,树形的抽象语法树, 通过遍历抽象语法树生成未解析的逻辑语法树(unresolved logic plan),对应SQL解析后的一种树形结构,本身不包含任务数据信息,需要经过一次遍历之后,转换成成包含解析后的逻辑算子树(Analyzed LogicPlan),本身携带了各种信息,最后经过优化后得到最终的逻辑语法树(Optimized LogicPlan)。

不管解析被划分为几步,在Spark 执行环境中,都要转化成RDD的调用代码,才能被spark core所执行,示意图如下:
2. 抽象语法树生成
一般的从SQL语句语句转换成抽象的树状结构,需要经过词法分析和语法分析两个过程,实现较为繁琐,但是随着编译理论的成熟,开发人员可以借助各种各样的生成器,来实现词法分析和语法解析。
spark中使用的框架为Anylr 4,通过脚本文件进行SQL 关键字和语法的定义,然后通过框架来实现词法分析和语法分析,详情可见Antlr 百科,通过编译解析Antlr的脚本定义文件,我们可以获得如下几个重要的文件:
a.****Lexer 词法解析器
b.****Parser 语法解析器
c. ****BaseVisitor 访问遍历文件
我们需要做的,就是在 ****BaseVisitor 文件中,编写我们的访问处理逻辑,比如:遇到max、min和add关键字的时候,应该如何做。Spark 生成的****BaseVisitor类的全名为:SqlBaseBaseVisitor ,AstBuilder 继承自SqlBaseBaseVisitor,实现了遍历抽象语法树,生成逻辑执行计划的逻辑,SparkSqlAstBuilder则添加了一些DDL的操作,具体继承关系如下:

举例:
sql 语句:select name from student where age >18;
生成抽象语法树:

3.Unresolved Logic Plan 逻辑执行计划生成
当我们获得上一节得到的抽象语法树之后,就可以使用SparkSqlAstBuilder(继承自SqlBasebaseVisitor 访问者模式)进行遍历了,调用的方法为visitSingleStatement方法,该方法的代码如下,因为singleStatement为根节点,无任何逻辑代码,所以直接递归遍历子节点即可:

直到遍历到关键Context节点的时候,比如QuerySpecificationContext的时候,需要按照顺序遍历三个分支,生成逻辑执行计划,其访问方法为visitQuerySpecification,源码如下:

from其实是返回一个relation,代表from的表信息,withQuerySpecification会携带relation表信息,继续向下进行遍历解析,解析顺序如下所示:
(1) 解析from分支,对应val from = —— 段代码,创建UnresollvedRelation
(2)withQuerySpecification()方法的调用,解析where中的过滤条件expresstion,创建Filter 逻辑执行计划
(3) 解析select * 部分,对最后的输出,进行列的裁剪,创建Project 逻辑执行计划
(4) 构建完整化逻辑执行计划

最后解析完毕的逻辑执行计划可视化如下:

4. Analyzed Logical Plan 逻辑执行计划生成
该过程的执行,实际上是从unresolved logic plan到analyzed logical plan的转化过程,通过在遍历的过程中,应用各种rule对其进行转化,驱动应用rules的类为RuleExecutor,其包含了一组Seq[Batch],每一个Batch中包含了一组Rule和strstegy,一个是转换规则,一个是规则应用次数,结构如下:

RuleExecutor的驱动方法为execute()方法,其实现逻辑如下,Batch遍历一遍,但是每条rule会被执行多次(这是缩减的代码,全量代码可以查看RuleExecutor.scala这个类):

所以本阶段最重要的就是定义转换规则Rules,目前 spark 2.1 Rules定义了6个Batch,共有34条内置规则Rules,包含表的解析,列的解析和数值类型转换等。
从之前得到的unresolved logic plan转化到analyzed logic plan需要经历如下步骤:
a.解析unresolvedRelation 通过catalog获取表的列信息,并为student 添加别名别点
b.解析Filter 节点,解析age列信息(添加age列在数据表的的列位置信息),转换18的数据类型
c.解析Project节点,添加name列信息(添加列name在数据表中的列信息)
解析后的logic plan如下所示:

5.Optimized Logic Plan 逻辑执行计划生成
逻辑计划优化器(Optimizer) 实现原理同Analyzed 继承自RuleExecutor,通过应用Seq(Batch) 优化规则,实现逻辑树的优化过程,总共2个Batch和4个Spark特有的优化规则,例如:别名消除、算子列裁剪下推和算子组合等。
因为SQL语句简单,所以在本步骤,只应用了别名消除规则,如下:

6.SparkPlan 物理执行计划的生成
物理计划是直接能够进行执行的方法,也就是SparkPlan类,其中该类包含了几个比较重要的方法:
a.doExecute 物理计划执行调用的方法
b.requirdChildDistrbution 约束子节点的数据分布(分区)情况是否符合要求
c.outputPartitionng 按照规定的数据分布进行输出
物理计划的生成方式跟之前的方式类似,包含一个驱动类和转换策略,驱动类为SparkPlanner,驱动方法为plan(),传入一个SparkPlan,应用驱动类内部的Seq[Strategy],策略会对SparkPlan进行匹配,向物理执行计划进行转换,

转换之后的物理执行计划如图所示,之后经过一些准备操作之后,便可以提交执行了:
