跟神犇Navi_Awson对斯坦纳树的正确性讨论了很久,最终由yy达成了基本共识(雾)
为了避免之后忘记,因此在此进行记录。
下面写的只是基本证明,有可能有部分不严谨的地方。但如果能给一个让大家信服的理由就最好了ww如果不想看不靠谱的证明,请去找其它博文学习斯坦纳树。他们写得比我好些_(:зゝ∠)_。
什么是斯坦纳树?
要求包含一些特定关键点的最小生成树。有点权版本和边权版本。
原本是NP问题,对于规模较小的数据可以使用状压dp解决。
这类问题的特点是关键点的数目很少,于是对关键点进行状压。
求解斯坦纳树的基本方法
状态定义:
\(dp[i][state]\)以i为根,目前包含关键点的状态是\(state\)
转移方程:
\(dp[i][state]=min(dp[i][sub1]+dp[i][sub2])\) 子集的交集应为空,并集应为state
\(dp[i][state]=min(dp[i][state],dp[j][state]+e[i][j])\)
显然,转移方程共两层。
最外层从小到大枚举状态state,第二层循环枚举点i,之后枚举第一层方程的转移(显然子集状态皆已遍历),之后再进行第二层方程的转移。由于第二层的状态转移顺序不明显,又具有三角形不等式的特征,所以可以利用SPFA进行转移。当dp[i][state]被更新之后,我们就可以从此点出发进行SPFA。
关于正确性的疑问
显然dp[i][sub1]和dp[i][sub2]分别对应着一种生成树方案。
由此我们需要证明几点:
dp[i][sub1]和dp[i][sub2]在可行的情况下能够得到dp[i][state]状态下的最优解。
无法通过dp[i][sub1]和dp[i][sub2]得到dp[i][state]状态下的最优解,我们可以通过第二层方程进行转移,通过这层转移可以得到dp[i][state]的最优解。
因此,我们必须假设一个前提:dp[i][sub1]和dp[i][sub2]皆为已知最优解。即保证dp[i][sub1]和dp[i][sub2]皆为最优解。
证明过程
前提:子状态保证为最优解
引理一:一般情况下,以i为根的最优生成树能分解成两个不相交的最优生成树,分别代表两个子状态,此时第一个方程转移正确。
引理二:以i为根的最优生成树,叶子节点皆为关键点。
引理三:特殊情况下,以i为根的最优生成树无法分解,当且仅当节点i的度数<2。
由引理二得到,所有的最优生成树,节点数若>=3,生成树必定存在一个某个点为根的情况,保证能够以一般状态求解。而以一般状态求解的节点能够通过第二个方程转移到整棵最优生成树的节点。
而若最优生成树的节点<=2,也就是只可能存在特殊情况,我们发现这种情况可以直接被方程所适用。
斯坦纳树的正确性得证。
如果已经看懂了,下面就不用再花时间观看了。可以直接跳到例题。
证明一:重复计算的问题?
我们发现,dp[i][sub1]和dp[i][sub2]既然表示两种不同的方案,那么两种方案的合并可能会出现被重复计算的边权。
事实上,我们假设已经得出了dp[i][state]状态下的最优解(假想的最优生成树)。那么假设他可以分解成两棵同根且边不相交的子树,每个子树都包含至少一个关键点,那么由于保证了dp[i][sub]为最优解,这两棵子树显然就对应着dp[i][sub1]和dp[i][sub2],则证明了dp[i][state]一定可以分解成一个dp[i][sub1]和dp[i][sub2]使其不会重复计算。
也就是说,只要不是极为特殊的情况,第一个方程足以应付(保证dp[i][sub]为最优解)
然而事实上,确实是存在一种情况,无法分解成两棵这样的子树。它一定保证两个状态合并边会重复计算。

我们假设关键点为0,2,3,此时我们需要计算\(dp[0][111(二进制表示)]\),他只能从\(dp[0][101]\)和\(dp[0][110]\)转移而来。我们会发现,这样子的转移,(0,1)这条边一定会被计算多遍。
于是第二个方程便登场了。
证明二:一定存在的关键转移点
我们假设一个存在的关键转移点j,他能够分解成两棵这样的完美子树。于是我们可以得到dp[j][state]的最优解。
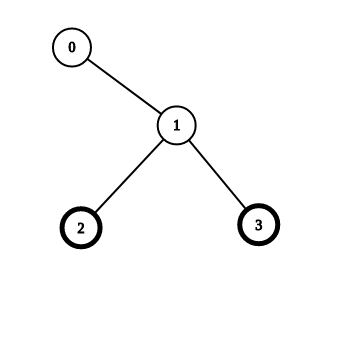
对于这样的一幅图,点1则是这样的一个关键转移点,而点0则是这样的一个特殊点。所以我们可以由方程2将点1的状态转移到点0。
这也意味着,只要这样的关键转移点存在于假想的最优生成树上,那么在这棵假想的最优生成树上的所有点的最优解都能够通过方程2被转移到。
也就是说,我们只需证明这样的关键转移点存在就行了。
在什么情况下,某个点会是一个无法通过方程1得到最优解的特殊点?
如果把这个点当成一个根,将其不包含关键点的子树忽略。如果这个点的度数为一,那么他一定是一个特殊点。如果大于1,则其绝对不是特殊点,而是一个关键转移点。
则只要假想的最优生成树上,点数>2,那么这个关键转移点就一定存在。
如果假想的最优生成树上,点数=2,那么就可以对其进行证明——因为这两个点一定都是关键点。
即完全可以通过第一个方程和第二个方程得到某个状态的最优解。
我们一定能求出初始状态的最优解,保证了证明的前提,又保证每次都能求得某个状态的最优解。
于是这就基本证明了斯坦纳树的正确性。
补充
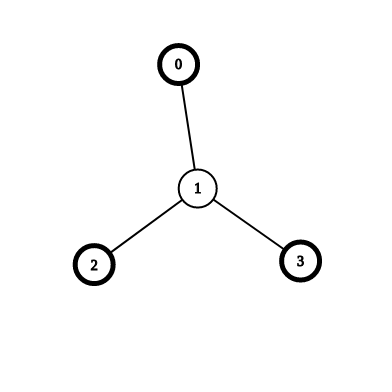
对于这幅图可能需要重新说明:\(dp[0][111]\)可以由\(dp[1][011]\)转移得到。
例题 - Luogu4294 BZOJ2595 [WC2008]游览计划
本题只有BZOJ有SPJ。
本题将边转化成了点来处理。于是我们可以直接把dp方程稍改。
由于要求得具体的方案,我们需要记录当前的状态是由哪些状态转移过来的。以及这些状态一个都不能漏。之后直接dfs就可以求得方案了。
Code
// Code by ajcxsu
// Problem: Wc2008 Travel
#include<bits/stdc++.h>
#define INF (0x3f3f3f3f)
using namespace std;
const int N=11,M=11,K=11;
int ma[N][M],st[N][M],p,U;
int dp[N][M][1<<K];
int n,m;
struct Node {
int x,y;
Node(int x=0,int y=0):x(x), y(y) {}
bool val() { return x>=1 && x<=n && y>=1 && y<=m; }
} ;
struct Pre {
int x,y,sta;
Pre(int x=-1,int y=0,int sta=0):x(x), y(y), sta(sta) {}
} pre[N][M][1<<K];
queue<Node> qu;
bool upd(int x,int y,int ns,int i,int j,int sta,int w) {
if(dp[x][y][ns]>w) return dp[x][y][ns]=w, pre[x][y][ns]=Pre(i,j,sta), true;
return false;
}
int mv[]={0,1,0,-1,0};
void SPFA(int sta) {
while(!qu.empty()) {
Node na=qu.front();
qu.pop();
for(int i=1;i<=4;i++) {
Node ta(na.x+mv[i-1], na.y+mv[i]);
if(ta.val() && upd(ta.x, ta.y, sta|st[ta.x][ta.y], na.x, na.y, sta, dp[na.x][na.y][sta]+ma[ta.x][ta.y])) {
if((sta|st[ta.x][ta.y])==sta) qu.push(Node(ta.x, ta.y));
}
}
}
}
bool vis[N][N];
void dfs(int x,int y,int sta) {
if(pre[x][y][sta].x==-1) return;
vis[x][y]=1;
Pre p=pre[x][y][sta];
dfs(p.x,p.y,p.sta);
if(p.x==x && p.y==y) dfs(p.x, p.y, sta-p.sta);
}
void putout() {
for(int i=1;i<=n;i++) {
for(int j=1;j<=m;j++)
if(!ma[i][j]) cout<<'x';
else if(vis[i][j]) cout<<'o';
else cout<<'_';
cout<<endl;
}
}
int main() {
ios::sync_with_stdio(false);
memset(dp,0x3f,sizeof(dp));
cin>>n>>m;
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++) {
cin>>ma[i][j];
if(!ma[i][j]) st[i][j]=1<<p, p++, dp[i][j][st[i][j]]=0;
}
U=(1<<p)-1;
for(int sta=1;sta<=U;sta++) {
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++) {
for(int sub=(sta-1)&sta; sub; sub=(sub-1)&sta)
upd(i,j,sta,i,j,sub,dp[i][j][sub]+dp[i][j][sta-sub]-ma[i][j]);
if(dp[i][j][sta]!=INF)
qu.push(Node(i,j)), SPFA(sta);
}
}
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
if(!ma[i][j]) {
cout<<dp[i][j][U]<<endl;
dfs(i,j,U);
putout();
exit(0);
}
return 0;
}