 版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
目录
Python 要求字符串必须使用引号括起来,使用单引号也行,使用双引号也行一一只要两边的引号能配对即可。
1. 字符串和转义字符
字符串的内容几乎可以包含任何字莉, 英文字符也行,中文字符也行。

字符串既可用单引号括起来,也可用双引号括起来,远没有任何区别。
如果字符串内容本身包含了单引号或双引号,此时就需要进行特殊处理。
- 使用不同的引号将字符串括起来。
- 对引号进行转义。Python 允许使用反斜线( \ )将字符串中的特殊字符进行转义。假如字符串既包含单引号,又包含双引号,此时必须使用转义字符。
str1 = 'Charlie'
str2 = "疯狂软件教育"
print(str1)
print(type(str1))
print(str2)
# 使用不同的引号
#str3 = 'I'm a coder'
str3 = "I'm a coder"
str4 = '"Spring is here, let us jam!", said woodchuck.'
# 转义字符
str5 = '"we are scared, Let\'s hide in the shade", says the bird'
print(str5)2. 拼接字符串
如果直接将两个字符串紧挨着写在一起, Python 就会自动拼接它们
上面这种写法只是书写字符串的一种特殊方法, 并不能真正用于拼接字符串。Python 使用力加号( + )作为字符串的拼接运算符 。

3. repr 和字符串
将字符串与数值进行拼接, 而Python 不允许直接拼接数值和字符串, 程序必须先将数值转换成字符串。
为了将数值转换成字符串, 可以使用str()或repr() 函数.
s1 = "这本书的价格是:"
p = 99.8
# 字符串直接拼接数值,程序报错
#print(s1 + p)
# 使用str()将数值转换成字符串
print(s1 + str(p))
# 使用repr()将数值转换成字符串
print(s1 + repr(p))
st = "I will play my fife"
print(st)
print(repr(st)) str()和 repr()函数都可以将数值转换成字符串,其中str 本身是Python 内置的类型( 和int 、float一样〉,而repr()则只是一个函数。此外, repr 还有一个功能, 它会以Python 表达式的形式来表示值.
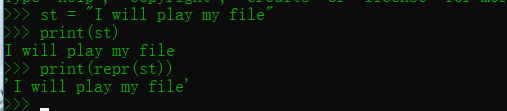
上面代码中st 本身就是一个字符串, 但程序依然使用了repr()对字符串进行转换。
通过上面的输出结果可以看出, 如果直接使用print()函数输出字符串, 将只能看到字符串的内容, 没有引号; 但如果先使用repr() 函数对字符串进行处理, 然后再使用print()执行输出,将可以看到带引号的字符串一一这就是字符串的Python 的表达式形式。
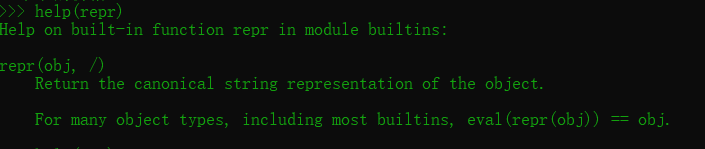
repr() 函数将对象转化为供解释器读取的形式。返回一个对象的 string 格式。

4. 使用input 和raw_input 获取用户输入
input() 函数用于向用户生成一条提示,然后获取用户输入的内容。由于input() 函数总会将用户输入的内容放入字符串中,因此用户可以输入任何内容, input()函数总是返回一个字符串。
msg = input("请输入你的值:")
print(type(msg))
print(msg)运行过程可以看出,无论输入哪种内容,始终可以看到input()函数返回字符串,程序总会将用户输入的内容转换成字符串。

5. 长字符串
前面介绍Python 多行注释时提到使用三个引号(单引号、双引号都行)来包含多行注释内容,其实这是长字符串写法,只是由于在长字符串中可以放置任何内容,包括放置单引号、双引号都可以,如果所定义的长字符串没有赋值给任何变量,那么这个字符串就相当于被解释器忽略了,也就相当于注释掉了。
实际上,使用三个引号括起来的长字符串完全可以赋值给变量
当程序中有大段文本内容要定义成字符串时,优先推荐使用长字符串形式,因为这种形式非常强大,可以让字符串中包含任何内容,既可包含单引号,也可包含双引号。
此外, Python 还允许使用转义字符(\) 对换行符进行转义,转义之后的换行符不会“中断”字符串。
s = '''"Let's go fishing", said Mary.
"OK, Let's go", said her brother.
they walked to a lake'''
print(s)
print(type(s))
s2 = 'The quick brown fox \
jumps over the lazy dog'
print(s2)
num = 20 + 3 / 4 + \
2 * 3
print(num)需要说明的是, Python 不是格式自由的语言,因此Python 程序的换行、缩进都有其规定的语法。所以, Python的表达式不允许随便换行。如果程序需要对Python 表达式换行,同样需要使用转义字符( \)进行转义.
6. 原始字符串
原始字符串以“r”开头, 原始宇符串不会把反斜线 ( \ )当成特殊字符.
如果原始字符串中包含引号,程序同样需要对引号进行转义(否则Python 同样无法对字符串的引号精确配对),但此时用于转义的反斜线会变成字符串的一部分。
由于原始字符串中的反斜线会对引号进行转义,因此原始字符串的结尾处不能是反斜线一一否则字符串结尾处的引号就被转义了,这样就导致字符串不能正确结束。
如果确实要在原始字符串的结尾处包含反斜线怎么办呢?一种方式是不要使用原始字符串,而是改为使用长字符串写法( 三引号字符串〉; 另一种方式就是将反斜线单独写。
s1 = r'G:\publish\codes\02\2.4'
print(s1)
# 原始字符串包含的引号,同样需要转义
s2 = r'"Let\'s go", said Charlie'
print(s2)
s3 = r'Good Morning' '\\'
print(s3)
7. 字节串( bytes)
Python 3 新增了bytes 类型,用于代表字节串( 这是作者生造的一个词, 与字符串对应)。宇符串(str)由多个字符组成, 以字符为单位进行操作; 字节串( bytes )由多个字节组成,以字节为单位进行操作。
bytes 和str 除操作的数据单元不同之外,它们支持的所有方法都基本相同, bytes 也是不可变序列。
bytes 对象只负责以宇节(二进制格式)序列来记录数据,至于这些数据到底表示什么内容,完全由程序决定。如果采用合适的字符集, 字符串可以转换成字节串;反过来,字节串也可以恢复成对应的字符串。
由于bytes 保存的就是原始的字节( 二进制格式)数据,因此bytes 对象可用于在网络上传输数据,也可用于存储各种二进制格式的文件, 比如图片、音乐等文件。
如果希望将一个字符串转换成bytes 对象, 有如下三种方式。
- 如果字符串内容都是ASCII 字符,则可以通过直接在字符串之前添加b 来构建字节串值。
- 调用bytes()函数(其实是bytes 的构造方法)将字符串按指定字符集转换成字节串,如果不指定字符集,默认使用UTF - 8 字符集。
- 调用字符串本身的encode()方法将字符串按指定宇符集转换成字节串,如果不指定字符集,默认使用UTF- 8 字符集。
# 创建一个空的bytes
b1 = bytes()
# 创建一个空的bytes值
b2 = b''
# 通过b前缀指定hello是bytes类型的值
b3 = b'hello'
print(b3)
print(b3[0])
print(b3[2:4])
# 调用bytes方法将字符串转成bytes对象
b4 = bytes('我爱Python编程',encoding='utf-8')
print(b4)
# 利用字符串的encode()方法编码成bytes,默认使用utf-8字符集
b5 = "学习Python很有趣".encode('utf-8')
print(b5)
# 将bytes对象解码成字符串,默认使用utf-8进行解码。
st = b5.decode('utf-8')
print(st) # 学习Python很有趣
在字节串中每个数据单元都是字节,也就是8 位,其中每4 位(相当于4 位二进制数,最小值为0 , 最大值为15 )可以用一个十六进制数来表示,因此每字节需要两个|-六进制数表示.
如果程序获得了bytes 对象,也可调用b ytes 对象的decode()方法将其解码成字符串。
字符集的概念:计算机底层并不能保存字符,但程序总是需要保存各种字符的, 那该怎么办呢?计算机“科学家”就想了一个办法:为每个字符编号,当程序要保存字符时,实际上保存的是该字符的编号; 当程序读取字符时,读取的其实也是编号,接下来要去查“编号一字符对应表”( 简称码表)才能得到实际的字符。因此,所谓的字符集,就是所有字符的编号组成的总和。
早期美国人给英文字符、数字、标点符号等字符进行了编号,他们认为所有字符加起来顶多100 多个, 只要1 字节( 8 位,支持256 个字符编号)即可为所有字符编号一一这就是ASCII字符集。后来, 亚洲国家纷纷为本国文字进行编号一一一即制订本国的字符集,但这些宇利集并不兼容。于是美国人又为世界上所有书面语言的宇符进行了统一编号,这次他们用了两个字节(16 位,支持65536 个字符编号),这就是Unicode 字符集。实际使用的UTF-8, UTF-1 6 等其实都属于Unicode字符集。
由于不同人对字符的编号完全可以很随意,比如同一个“ 爱”字,我可以为其编号为99 , 你可以为其编号为199 , 所以同一个编号在不同字符集中代表的字符完全有可能是不同的。因此,对于同一个字符串,如果采用不同的字街集来生成bytes 对象, 就会得到不同的bytes 对象。