数据集(猫与狗的图片集)没有被包装在Keras里,要自行下载:https://www.kaggle.com/c/dogs-vs-cats/data 原始数据集包含25,000张狗和猫的图像(每个类别12,500个),大小为543MB(压缩后)。Keras己经内建好的预训练模型来进行图像分类, 包括:VGG16,VGG19,ResNet50,InceptionV3,InceptionResNetV2,Xception,MobileNet。实例化一个VGG16模型:
from keras.applications import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False, # 在这里告诉 keras我们只需要卷积基底的权重模型资讯
input_shape=(150, 150, 3)) # 宣告我们要处理的图像大小与颜色通道数
我们向构造函数传递了三个参数:
1.weights, 指定从哪个权重检查点初始化模型
2.include_top, 指定模型最后是否包含密集连接分类器。默认情况下,这个密集连接分类器对应于ImageNet的1000个类别。因为我们打算使用自己的分类器(只有两个类别:cat和dog),所以不用包含。
3.input_shape, 输入到网络中的图像张量(可选参数),如果不传入这个参数,那么网络可以处理任意形状的输入
以下是VGG16“卷积基底conv_base”架构细节:
conv_base.summary() # 打印一下模型资讯

最后这个特征图形状为(4, 4, 512),这个特征上面添加一个密集连接分类器。
0.不使用数据增强的快速特征提取(计算代价低)
运行ImageDataGenerator实例,将图像及其标签提取为Numpy数组,调用conv_base模型的predict方法从这些图像的中提取特征。
#特征提取
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = 'data/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255) # 产生一个"图像资料产生器"物件
batch_size = 20 # 设定每次产生的图像的数据批量
# 提取图像特征
def extract_features(directory, sample_count): # 影像的目录, 要处理的图像数
features = np.zeros(shape=(sample_count, 4, 4, 512)) # 根据VGG16(卷积基底)的最后一层的轮出张量规格
labels = np.zeros(shape=(sample_count)) # 要处理的图像数
# 产生一个"图像资料产生器"实例(资料是在档案目录中), 每呼叫它一次, 它会吐出特定批次数的图像资料
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150), # 设定图像的高(height)与宽(width)
batch_size=batch_size, # 设定每次产生的图像的数据批量
class_mode='binary') # 因为我们的目标资料集只有两类(cat & dog)
# 让我们把训练资料集所有的图像都跑过一次
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch) # 透过“卷积基底”来淬取图像特征
features[i * batch_size : (i + 1) * batch_size] = features_batch # 把特征先存放起来
labels[i * batch_size : (i + 1) * batch_size] = labels_batch #把标签先存放起来
i += 1
if i * batch_size >= sample_count:
# Note that since generators yield data indefinitely in a loop,
# we must `break` after every image has been seen once.
break
print('extract_features complete!')
return features, labels
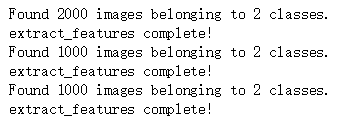
train_features, train_labels = extract_features(train_dir, 2000) # 训练资料的图像特征淬取
validation_features, validation_labels = extract_features(validation_dir, 1000) # 验证资料的图像特征淬取
test_features, test_labels = extract_features(test_dir, 1000) # 测试资料的图像特征淬取
提取的特征当前是(样本数,4,4,512)的形状。我们将它们喂给一个密集连接(densely-connected)的分类器,所以首先我们必须把它们压扁(flatten)成(样本数, 8192):
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
下面定义一个密集连接分类器,并在刚刚保存好的数据和标签上训练分类器:
from keras import models
from keras import layers
from keras import optimizers
# 产生一个新的密集连接层来做为分类器
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid')) # 因为我的资料集只有两类(cat & dog)
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
# 把预处理的卷积基底所提取的特征做为input来进行训练
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))

训练速度快,只需要处理两个Dense层。看一下训练过程中的损失和精度曲线:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

从图中可以看出,验证精度达到了约90%,比之前从一开始就训练小型模型效果要好很多,但是从图中也可以看出,虽然dropout比率比较大,但模型从一开始就出现了过拟合。这是因为本方法没有使用数据增强,而数据增强对防止小型图片数据集过拟合非常重要。
1.使用数据增强的特征提取(计算代价高)
这种方法速度更慢,计算代价更高,但是可以在训练期间使用数据增强。这种方法是:扩展conv_base模型,然后在输入数据上端到端的运行模型。(这种方法计算代价很高,必须在GPU上运行),承接我们之前定义的网络模型:移花+接木
from keras import models
from keras import layers
model = models.Sequential() # 产生一个新的网络模型结构
model.add(conv_base) # 把预训练的卷积基底叠上去
model.add(layers.Flatten()) # 打平
model.add(layers.Dense(256, activation='relu')) # 叠上新的密集连接层来做为分类器
model.add(layers.Dense(1, activation='sigmoid')) # 因为我的资料集只有两类(cat & dog)
model.summary()

VGG16的“卷积基底”有14,714,688个参数,非常大。上面添加的分类器有200万个参数。
在编译和训练模型之前,需要冻结卷积基。冻结一个或多个层是指在训练过程中保持其权重不变。如果不这么做,那么卷积基之前学到的表示将会在训练过程中被修改。因为其上添加的Dense是随机初始化的,所以非常大的权重更新会在网络中进行传播,对之前学到的表示造成很大破坏。
在Keras中,冻结网络的方法是将其trainable属性设置为False:
# 看一下“冻结前”有多少可以被训练的权重
print('This is the number of trainable weights '
'before freezing the conv base:', len(model.trainable_weights))
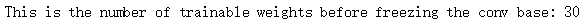
# “冻结”卷积基底
conv_base.trainable = False
# 再看一下“冻结后”有多少可以被训练的权重
print('This is the number of trainable weights '
'after freezing the conv base:', len(model.trainable_weights))
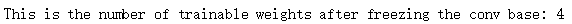
如此设置之后,只有添加的两个Dense层的权重才会被训练,总共有4个权重张量,每层2个(主权重矩阵和偏置向量),注意的是,如果想修改权重属性trainable,那么应该修改好属性之后再编译模型。
下面,我们可以训练模型了,并使用数据增强的办法:
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# 请注意: 验证测试用的资料不要进行资料的增强
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 图像资料的目录
train_dir,
# 设定图像的高(height)与宽(width)
target_size=(150, 150),
batch_size=20,
# 因为我们的目标资料集只有两类(cat & dog)
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=2)

model.save('cats_and_dogs_small_3.h5') # 把模型储存到档案
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

验证精度到了将近96%,而且减少了过拟合(在训练集上好,验证测试集上差)
2.微调模型
以上0和1都属于特征提取,下面使用模型微调进一步提高模型性能,步骤如下:
(1)在已经训练好的基网络(base network)上添加自定义网络
(2)冻结基网络
(3)训练所添加的部分
(4)解冻基网络的一些层
(5)联合训练解冻的这些层和添加的部分
在做特征提取的时候已经完成了前三个步骤。我们继续第四个步骤,先解冻conv_base,然后冻结其中的部分层。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
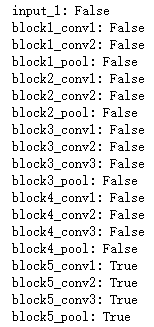
回顾这些层,我们将微调最后三个卷积层,直到block4_pool之前所有层都应该被冻结,后面三层来进行训练。
为什么不调整更多层? 为什么不调整整个“卷积基底”? 我们可以,但是我们需要考虑:
1.“卷积基底”较前面的神经层所学习到的特征表示更加通用(generic),更具有可重复使用的特征,而较高层次的特征表示则聚焦独特的特征。微调这些聚焦独特的特征的神经层则更为有用。
2.我们训练的参数越多,我们越有可能的过拟合(overfitting)。VGG16的“卷积基底”具有1千5百万的参数,因此尝试在小数据集上进行训练是有风险的。
conv_base.trainable = True # 解冻 "卷积基底"
# 所有层直到block4_pool都应该被冻结,而 block5_conv1,block5_conv2, block5_conv3 及 block5_pool则被解冻
layers_frozen = ['block5_conv1','block5_conv2', 'block5_conv3', 'block5_pool']
for layer in conv_base.layers:
if layer.name in layers_frozen:
layer.trainable = True
else:
layer.trainable = False
# 把每一层是否可以被"trainable"的flat打印出来
for layer in conv_base.layers:
print("{}: {}".format(layer.name, layer.trainable))
现在可以微调网络了,我们将使用学习率非常小的RMSProp优化器来实现。之所以让学习率很小,是因为对于微调网络的三层表示,我们希望其变化范围不要太大,太大的权重可能会破坏这些表示。
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5), # 使用小的learn rate
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)

model.save('cats_and_dogs_small_4.h5')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

这些曲线看起来包含噪音。为了让图像更具有可读性,可以让每个损失和精度替换为指数移动平均,从而让曲线变得更加平滑,下面用一个简单实用函数来实现:
def smooth_curve(points, factor=0.8):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
plt.plot(epochs,
smooth_curve(acc), 'bo', label='Smoothed training acc')
plt.plot(epochs,
smooth_curve(val_acc), 'b', label='Smoothed validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs,
smooth_curve(loss), 'bo', label='Smoothed training loss')
plt.plot(epochs,
smooth_curve(val_loss), 'b', label='Smoothed validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

通过指数移动平均,验证曲线变得更清楚了。精度提高了1%,约从96%提高到了97%。
在测试数据上最终评估这个模型:
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)
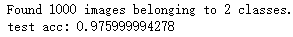
得到了差不多97%的测试精度,在关于这个数据集的原始Kaggle竞赛中,这个结果是最佳结果之一。我们只是用了一小部分训练数据(约10%)就得到了这个结果。训练20000个样本和训练2000个样本还是有很大差别的。