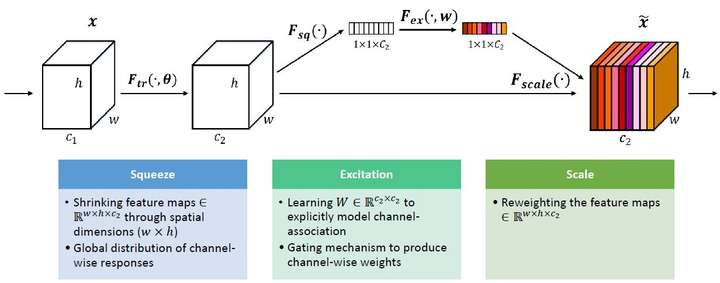
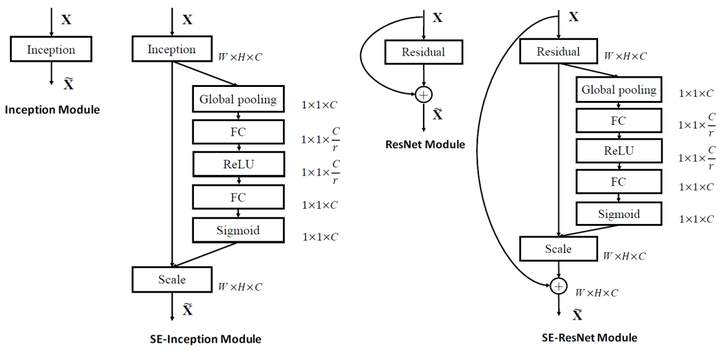
看senet block的代码,明白如何实现
def Squeeze_excitation_layer(self, input_x, out_dim, ratio, layer_name):
with tf.name_scope(layer_name) :
squeeze = Global_Average_Pooling(input_x)#对每个通道取全局最大化
excitation = Fully_connected(squeeze, units=out_dim / ratio, layer_name=layer_name+'_fully_connected1')
excitation = Relu(excitation)
#为什么用两个全卷基层, 而且为什么卷基层的unit不同?
excitation = Fully_connected(excitation, units=out_dim, layer_name=layer_name+'_fully_connected2')
excitation = Sigmoid(excitation)
excitation = tf.reshape(excitation, [-1,1,1,out_dim])
scale = input_x * excitation
return scale为什么用两个全卷基层, 而且为什么卷基层的unit不同?
(1) 用两个全连接层,因为一个全连接层无法同时应用relu和sigmoid两个非线性函数,但是两者又缺一不可。
(2) 为了减少参数,所以设置了r比率。(论文中取的是16)

作者在准确率和参数量之间取了一个折中,r = 16.
参考
(1)[DL-架构-ResNet系] 007 SENet https://zhuanlan.zhihu.com/p/29708106
(2)【深度学习从入门到放弃】Squeeze-and-Excitation Networks https://zhuanlan.zhihu.com/p/29812913