概述
设计数据库和创建表的最终目的就是为了使用数据。与数据库一起工作是 SQL 数据操作语言的工作(DML)。DML 的核心是 SELECT 命令,它也是查询数据库的唯一命令。本文结构如下:
- SELECT 命令通用形式
- FROM 关键字介绍
- WHERE 关键字介绍
- ORDER BY 关键字介绍
- LIMIT & OFFSET 关键字介绍
- GROUP BY & HAVING 关键字介绍
- DISTINCT 关键字介绍
准备工作:
在正文中,我们会以如下表格 Products 为例,表格如下所示:
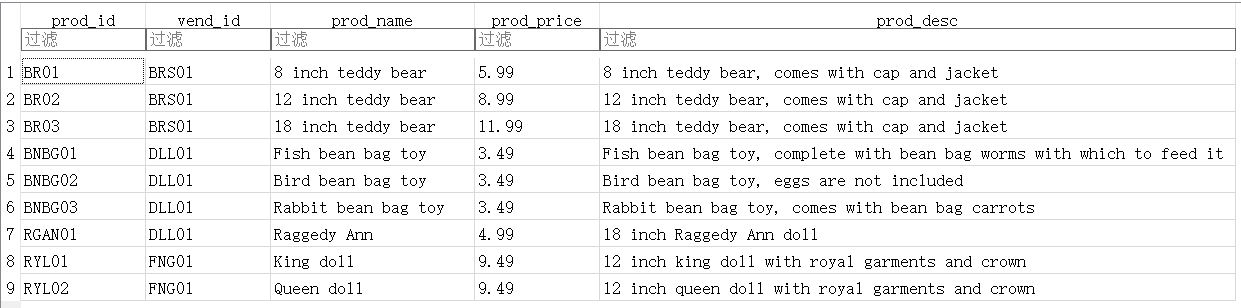
可以看到,Products 表里面有9行数据。通过 .schema 命令查看这张表的组成:
sqlite> .schema Products
CREATE TABLE Products
(
prod_id char(10) NOT NULL ,
vend_id char(10) NOT NULL ,
prod_name char(255) NOT NULL ,
prod_price decimal(8,2) NOT NULL ,
prod_desc text NULL ,
PRIMARY KEY (prod_id) ,
FOREIGN KEY (vend_id) REFERENCES Vendors (vend_id)
);
在知道这张表的组成和数据之后,接下来我们来学习 SELECT 命令。
SELECT 命令
SELECT 命令的通用形式如下:
SELECT [DISTINCT] heading
FROM tables
WHERE predicate
GROUP BY columns
HAVING predicate
ORDER BY columns
LIMIT offset,count;
其中大写的八月份为 SELECT 命令中的关键字,这是 SELECT 命令最完整的表现形式,但并非每个部分都是必须的。最为常见的 SELECT 子句如下所示:
SELECT heading FROM tables WHERE predicate;
我们接下来通过拆解的方式来分析上述的 SELECT 命令。
1. FROM
FROM 关键字指出从哪个表中检索数据,如果含有多个表,那么表和表之间用逗号隔开,多个表之间会组合成一种单一关系。例子如下所示:
输入:
SELECT prod_id, prod_name, prod_price FROM Products;
输出:
prod_id prod_name prod_price
---------- ----------------- ----------
BR01 8 inch teddy bear 5.99
BR02 12 inch teddy bea 8.99
BR03 18 inch teddy bea 11.99
BNBG01 Fish bean bag toy 3.49
BNBG02 Bird bean bag toy 3.49
BNBG03 Rabbit bean bag t 3.49
RGAN01 Raggedy Ann 4.99
RYL01 King doll 9.49
RYL02 Queen doll 9.49
2. WHERE
WHERE 关键字用于过滤数据,WHERE 的参数是逻辑预测,最简单的预测是断言,如下所示:
输入:
SELECT prod_name, prod_price
FROM Products
WHERE prod_price = 3.49;
输出:
prod_name prod_price
----------------- ----------
Fish bean bag toy 3.49
Bird bean bag toy 3.49
Rabbit bean bag t 3.49
这条 SELECT 命令就只把 prod_price 为 3.49 的行打印了出来。除了断言之外,还可以使用操作符来进行过滤,SQLite 支持的操作符位于文末。接下来用几个例子展示使用操作符过滤:
不匹配检查
输入:
SELECT vend_id, prod_name
FROM Products
WHERE vend_id <> 'DLL01';
输出:
vend_id prod_name
---------- -----------------
BRS01 8 inch teddy bear
BRS01 12 inch teddy bea
BRS01 18 inch teddy bea
FNG01 King doll
FNG01 Queen doll
可以看到输出结果过滤掉了 vend_id 为 DLL01 的行。
范围检查
输入:
SELECT prod_name, prod_price
FROM Products
WHERE prod_price BETWEEN 5 AND 10;
输出:
prod_name prod_price
----------------- ----------
8 inch teddy bear 5.99
12 inch teddy bea 8.99
King doll 9.49
Queen doll 9.49
这里我们过滤出了 prod_price 在 5~10 之间的数据(包括5和10),用到了 BETWEEN 和 AND 关键字。
多个 AND 或 OR 的操作
WHERE 是允许多个任意数目的 AND 或 OR 操作符的,但是在使用时要特别留意 AND 操作符的优先级高于 OR,否则的话极易产生错误。例如我们要在 Products 表中过滤出 vend_id 为 DLL01 或 BRS01 中值 prod_price 大于等于 10 的行,如果我们输入如下:
SELECT vend_id, prod_price
FROM Products
WHERE vend_id= 'DLL01' OR vend_id= 'BRS01'
AND prod_price >= 10;
输出:
vend_id prod_price
---------- ----------
BRS01 11.99
DLL01 3.49
DLL01 3.49
DLL01 3.49
DLL01 4.99
可以看到输出里面有 prod_price 小于 10 的行,所以这个输出不是我们预想的输出,造成这个的主要原因就是 AND 的优先级高于 OR。所以正确的输入应该是:
SELECT vend_id, prod_price
FROM Products
WHERE (vend_id= 'DLL01' OR vend_id= 'BRS01')
AND prod_price >= 10;
输出:
vend_id prod_price
---------- ----------
BRS01 11.99
通过加括号,此时的输出即为我们想要的结果了。
IN 操作符
IN 操作符用来指定条件范围,范围中的每个条件都可以进行匹配。IN 取一组由逗号分隔、括在圆括号内的合法值。
输入:
SELECT prod_name, prod_price
FROM Products
WHERE vend_id IN('DLL01', 'BRS01');
输出:
prod_name prod_price
----------------- ----------
8 inch teddy bear 5.99
12 inch teddy bea 8.99
18 inch teddy bea 11.99
Fish bean bag toy 3.49
Bird bean bag toy 3.49
Rabbit bean bag t 3.49
Raggedy Ann 4.99
LIKE 操作符
输入:
SELECT prod_name, prod_price
FROM Products
WHERE prod_name LIKE '%inch%';
输出:
prod_name prod_price
----------------- ----------
8 inch teddy bear 5.99
12 inch teddy bea 8.99
18 inch teddy bea 11.99
LIKE 相似匹配,百分号(%)表示匹配 0~任意个任意字符,即贪婪匹配;除此之外还有下划线(_)表示匹配任意一个字符。通过它我们能和方便地过滤出匹配子字符串的内容。需要注意的是 LIKE 匹配是大小写不敏感的,也就是说 '%inch%' 与 '%INCH%' 得到的匹配结果是一样的。
GLOB 操作符
输入:
SELECT prod_name, prod_price
FROM Products
WHERE prod_name GLOB '1*';
输出:
prod_name prod_price
------------------ ----------
12 inch teddy bear 8.99
18 inch teddy bear 11.99
GLOB 与 LIKE 的作用很相似,关键不同点是它使用有些像 UNIX/Linux 的文件名替换语法。也就是说它是使用 *或_来进行匹配的,并且 GLOB 匹配是区分大小写的。需要注意的是 LIKE 和 GLOB 都只能匹配字符串,其他类型的值是无法进行匹配的!
3. ORDER BY
ORDER BY 关键字用于对检索出来的数据进行排序,如下例子所示:
输入:
SELECT prod_name
FROM Products;
输出:
prod_name
-----------------
8 inch teddy bear
12 inch teddy bea
18 inch teddy bea
Fish bean bag toy
Bird bean bag toy
Rabbit bean bag t
Raggedy Ann
King doll
Queen doll
可以看到,这个输出看起来是无序的,它一般是按照数据最初添加到表中的顺序显示的。如果我们需要对输出进行排序,我们可以添加 ORDER BY 关键字,如下所示:
输入:
SELECT prod_name
FROM Products
ORDER BY prod_name;
输出:
prod_name
------------------
12 inch teddy bear
18 inch teddy bear
8 inch teddy bear
Bird bean bag toy
Fish bean bag toy
King doll
Queen doll
Rabbit bean bag to
Raggedy Ann
输出结果默认是按照升序进行排列,如果要按照降序进行排列,可以在后面再加上 DESC 关键字,例如上面的例子按降序进行排序就可以写成:
SELECT prod_name
FROM Products
ORDER BY prod_name DESC;
如果需要按多个字段进行排序,例如在 Products 中先按 prod_price 进行排序,再按照 prod_name 进行排序,可以写成如下输入:
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY prod_price, prod_name;
输出:
prod_id prod_price prod_name
---------- ---------- -----------------
BNBG02 3.49 Bird bean bag toy
BNBG01 3.49 Fish bean bag toy
BNBG03 3.49 Rabbit bean bag t
RGAN01 4.99 Raggedy Ann
BR01 5.99 8 inch teddy bear
BR02 8.99 12 inch teddy bea
RYL01 9.49 King doll
RYL02 9.49 Queen doll
BR03 11.99 18 inch teddy bea
而 SQL 还支持按字段的相对位置进行排序,所以上面的 SQL 语句还可以写成:
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY 2,3;
2 和 3 分布指代的就是 prod_price 和 prod_name 了。
4. LIMIT & OFFSET
LIMIT 和 OFFSET 关键字用于限定结果集的大小和范围。LIMIT 用于指定返回记录的最大数量,OFFSET 指定偏移的记录量。例子如下:
输入:
SELECT prod_name, prod_price
FROM Products
ORDER BY prod_price, prod_name
LIMIT 5 OFFSET 0;
输出:
prod_name prod_price
----------------- ----------
Bird bean bag toy 3.49
Fish bean bag toy 3.49
Rabbit bean bag t 3.49
Raggedy Ann 4.99
8 inch teddy bear 5.99
其中当 OFFSET 为 0 时,OFFSET 0 可以省去。可以看到现在显示的数据就是排序后的前5条数据,要查看后面的数据,直接将偏移量+5即可,如下所示:
SELECT prod_name, prod_price
FROM Products
ORDER BY prod_price, prod_name
LIMIT 5 OFFSET 5;
输出:
prod_name prod_price
------------------ ----------
12 inch teddy bear 8.99
King doll 9.49
Queen doll 9.49
18 inch teddy bear 11.99
而当 LIMIT 和 OFFSET 一起使用的时候,可以用逗号代替 OFFSET 关键字,上面的例子可以写成:
SELECT prod_name, prod_price
FROM Products
ORDER BY prod_price, prod_name
LIMIT 5, 5;
其中第一个数字代表的是偏移量,第二个数字代表的是结果集的大小。
5. GROUP BY & HAVING
GROUP BY 和 HAVING 关键字用于对数据进行分组。在学习分组之前我们先来了解一个函数 count。这个函数用于确定表中行的数目,例如下面的命令返回的是 Products 表中的行数:
SELECT COUNT(*)
FROM Products;
输出:
COUNT(*)
----------
9
说明 Products 中有 9 行数据。在大致了解这个函数的功能之后,我们继续回到本小节的主题中。首先说明一下分组的意义在哪?
首先假设一个场景,在 Products 表中,vend_id 的值表示产品供应商,假如我们此时要返回供应商 DLL01 提供的产品数目,可以轻易地写出以下命令:
SELECT COUNT(*)
FROM Products
WHERE vend_id='DLL01';
但是如果现在要返回每个供应商提供的产品数目,或者要返回提供2个以上产品的供应商,这时候按照之前的方式我们似乎无法做到,此时我们就需要用到分组了。
问题一:返回每个供应商提供的产品数目,我们可以这么做:
输入:
SELECT vend_id, COUNT(*)
FROM Products
GROUP BY vend_id;
输出:
vend_id COUNT(*)
---------- ----------
BRS01 3
DLL01 4
FNG01 2
可以看到,在使用了 GROUP BY 之后,会指示 DBMS 按 vend_id 进行排序并分组数据。这就会对每个 vend_id 而不是整个表进行产品数量的计算。从输出结果可以看出供应商BRS01有3个产品,DLL01有4个产品,FNG01有2个产品。
问题二:返回提供2个以上产品的供应商。
前面使用的 GROUP BY 使得我们对 vend_id 也就是供应商进行了分组,那么如何对这些供应商进行过滤呢?这是就要用到 HAVING 关键字了,我们可以使用如下命令:
SELECT vend_id
FROM Products
GROUP BY vend_id
HAVING COUNT(*) > 2;
输出:
vend_id
----------
BRS01
DLL01
可以看到成功过滤出了提供产品数量大于2的供应商名称。
HAVING 和 WHERE 的用法非常相似。几乎WHERE所有的技术和选项都适用于HAVING。它们之间最关键的区别在于HAVING过滤的是分组而WHERE过滤的是行。
在问题二中,我们可以得知WHERE在这里是不起作用的,因为过滤的是分组,所以我们使用的是HAVING。
另外,当WHERE和HAVING同时使用的时候,还有一点需要特别注意:
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。所以WHERE排除的行不包括在分组中。
关于这点我们看到下面的问题三。
问题三:列出具有两个以上产品且其价格大于等于4的供应商:
SELECT vend_id, COUNT(*)
FROM Products
WHERE prod_price >= 4
GROUP BY vend_id
HAVING COUNT(*) > 2;
输出:
vend_id COUNT(*)
---------- ----------
BRS01 3
从结果可以看出分组之前的行数首先被WHERE子语句进行过滤,再对过滤后的行进行分组,然后再过滤出符合HAVING条件的vend_id。
6. DISTINCT
最后我们来说说 DISTINCT 关键字。这个关键字用于去掉重复。当声明此关键字时,如果 SELECT 出的结果存在重复,那么它会过滤掉其中重复的行。例子如下:
输入:
SELECT DISTINCT vend_id
FROM Products;
输出:
vend_id
----------
BRS01
DLL01
FNG01
由输出可以看出,过滤掉了vend_id 中重复和行,使原来的9行变成了3行。
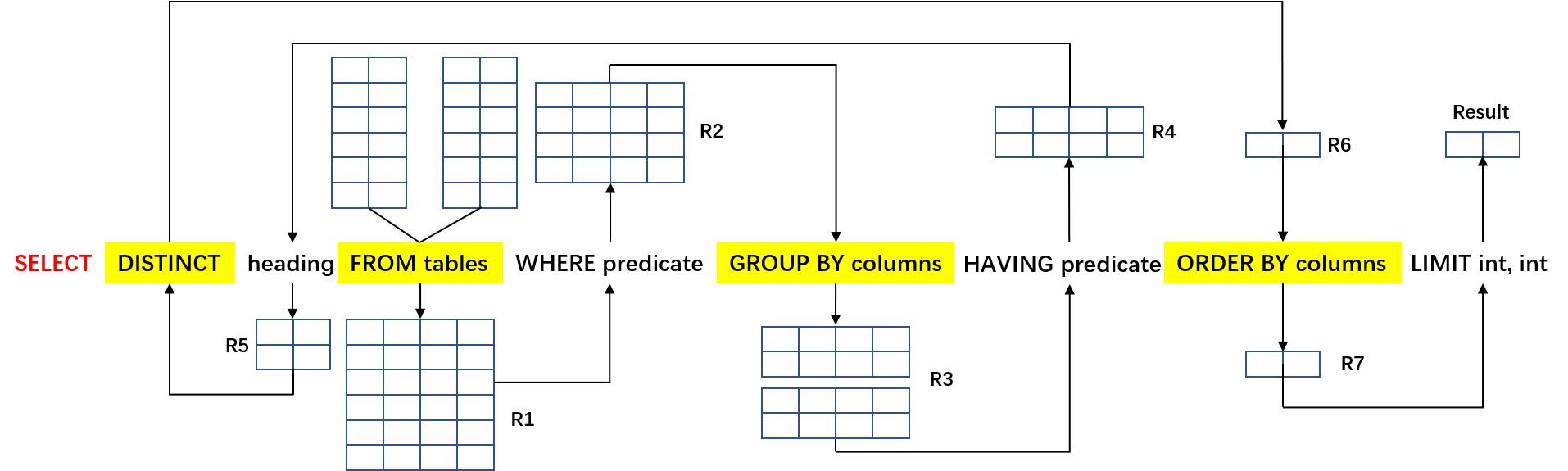
至此,关于 SELECT 命令中出现的关键字就介绍完了。最后附上一张 SQLite 中 SELECT 的处理过程图作为上面的总结:
最后附上 WHERE 关键字中所可能用到的操作符:
| 操作符 | 类型 | 作用 |
|---|---|---|
| || | String | 连接 |
| * | Arithmetic | 乘 |
| / | Arithmetic | 除 |
| % | Arithmetic | 余 |
| + | Arithmetic | 加 |
| - | Arithmetic | 减 |
| << | Bitwise | 左移 |
| >> | Bitwise | 右移 |
| & | Logical | 与 |
| | | Logical | 或 |
| < | Relational | 小于 |
| <= | Relational | 小于等于 |
| > | Relational | 大于 |
| >= | Relational | 大于等于 |
| = | Relational | 等于 |
| == | Relational | 等于 |
| <> | Relational | 不等于 |
| != | Relational | 不等于 |
| IN | Logical | In |
| AND | Logical | 与 |
| OR | Logical | 或 |
| IS | Logical Equal | 等于 |
| LIKE | Relational St | 字符串匹配 |
| GLOB | Relational Fi | 文件名匹配 |
参考
《SQLite权威指南》
- 第3章 sqlite中的sql
《SQL必知必会》
- 第2课 检索数据
- 第3课 排序检索数据
- 第4课 过滤数据
- 第5课 高级过滤数据
- 第6课 用通配符进行过滤
- 第10课 分组数据
文章中的图、表格等均源自《SQLite权威指南》,例子全部来源于《SQL必知必会》,转载请注明出处!
希望这篇文章对你有所帮助~