一、keras的backend设置
有两种方式:
1.修改JSON配置文件
修改~/.keras/keras.json文件内容为:
{ "iamge_dim_ordering":"tf", "epsilon":1e-07, "floatx":"float32", "backend":"tensorflow" }
官方文档解释:
-
iamge_data_format:字符串,"channels_last"或"channels_first",该选项指定了Keras将要使用的维度顺序,可通过keras.backend.image_data_format()来获取当前的维度顺序。对2D数据来说,"channels_last"假定维度顺序为(rows,cols,channels)而"channels_first"假定维度顺序为(channels, rows, cols)。对3D数据而言,"channels_last"假定(conv_dim1, conv_dim2, conv_dim3, channels),"channels_first"则是(channels, conv_dim1, conv_dim2, conv_dim3) -
epsilon:浮点数,防止除0错误的小数字 floatx:字符串,"float16","float32","float64"之一,为浮点数精度backend:字符串,所使用的后端,为"tensorflow"或"theano"
2.修改python环境变量中的 KERAS_BACKEND参数值
import os os.environ["KERAS_BACKEND"]="tensorflow"
在这种情况下,效果只是临时的,但可以总是写在代码的最前面,同样可以达到目的。
二、使用keras实现线性回归
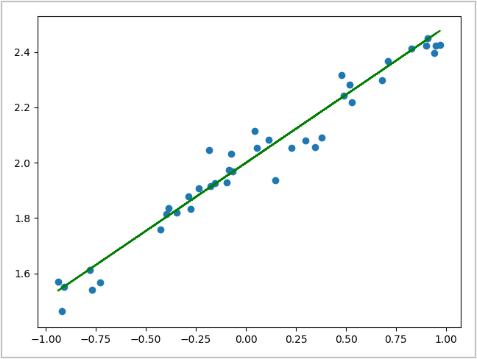
import numpy as np import matplotlib.pyplot as plt # 按顺序建立的model结构 from keras.models import Sequential # Dense是全连接层 from keras.layers import Dense # seed给定一个种子,利用同一个种子生成的随机数每次都相同 np.random.seed(1337) # 从-1到1生成200个均间距数 X = np.linspace(-1, 1, 200) # 打乱数据 np.random.shuffle(X) # 生成Y,并添加随机噪声 Y = 0.5 * X + 2 + np.random.normal(0, 0.05, (200,)) # 画散点图 plt.scatter(X, Y) plt.show() # XY的前160个数据作为训练数据,后40个数据作为测试数据 X_train, Y_train = X[:160], Y[:160] X_test, Y_test = X[160:], Y[160:] # 开始使用Keras创建网络结构 model = Sequential() # 添加一个全连接层,该层的输入维度是1,输出维度也是1。 model.add(Dense(output_dim=1, input_dim=1)) # 设置选择的损失函数,还有优化器 model.compile(loss='mse', optimizer='sgd') # 开始训练 print("Training ----------") for step in range(301): # 每次迭代都使用全部的训练集 cost = model.train_on_batch(X_train, Y_train) if step % 50 == 0: print("Train cost:", cost) # 开始测试 print("Testing -----------") cost = model.evaluate(X_test, Y_test, batch_size=40) print("Test cost:", cost) W, b = model.layers[0].get_weights() print("Weights=", W, "\nBiases=", b) # 画出在测试集上的拟合情况 Y_predict = model.predict(X_test) # 画出测试集的散点图 plt.scatter(X_test, Y_test) # 画出预测值对应的直线,颜色为红色 plt.plot(X_test, Y_predict, color='g') plt.show()
三、使用keras给mnist分类
# 解决报错GPU运行报错的问题 # 这里导入tf,用来修改tf后端的配置 import tensorflow as tf from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto() # 将显存容量调到只会使用30% config.gpu_options.per_process_gpu_memory_fraction = 0.3 # 使用设置好的配置 set_session(tf.Session(config=config)) import numpy as np np.random.seed(1337) from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential # 导入全连接层和激活函数 from keras.layers import Dense, Activation # 导入优化器RMSprop from keras.optimizers import RMSprop (X_train, y_train), (X_test, y_test) = mnist.load_data() print(X_train.shape[0]) print(X_test.shape[0]) # 将数据由原本的shape-(60000,28,28)变为(60000,784),然后将数据缩放到0-1之间 X_train = X_train.reshape(X_train.shape[0], -1) / 255 X_test = X_test.reshape(X_test.shape[0], -1) / 255 # 将标签数据变换为onehot模式,原本是用10进制数来表示的 y_train = np_utils.to_categorical(y_train) print(y_test) y_test = np_utils.to_categorical(y_test) print(y_test) # 可以在model中将各层放在一个列表中 model = Sequential([ # 第一个全连接层,输入784,输出32 Dense(output_dim=32, input_dim=784), Activation('relu'), # 不设置input_dim,会默认使用上一层的output_dim Dense(10), Activation('softmax'), ]) # 这样也可以 # model = Sequential() # model.add(Dense(32,input_dim=784)) # model.add(Activation('relu')) # model.add(Dense(10)) # model.add(Activation('softmax')) # 自己定义RMSprop rmsprop = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0) # 开始创建网络,使用我们自己定义的rmsprop,如果想使用默认的RMSprop也可是使用 # optimizer = 'rmsprop'来指定。 model.compile(optimizer=rmsprop, # 使用交叉熵损失函数 loss='categorical_crossentropy', # 指定在过程中需要额外计算的东西 metrics=['accuracy'] ) # 开始训练 print('Training ----------') # 使用fit来进行训练,epochs指训练几轮,一轮就是train的全部数据,这里是60000 # 这里一个epochs可以训练60000/32=1875轮,epochs=2,则一共训练3750轮 # batch_size=32指每训练一轮用多少数据,这个在显存能放得下的情况下,越大越好 model.fit(X_train, y_train, epochs=1, batch_size=32) # 开始测试 print('\nTesting ----------') loss, accuracy = model.evaluate(X_test, y_test) print('test loss:', loss) print('test accuracy:', accuracy)
注意前面GPU报错的处理办法。