版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
版权声明:署名,允许他人基于本文进行创作,且必须基于与原先许可协议相同的许可协议分发本文 (Creative Commons)
目录
一:springboot整合lucenne
在springboot中整合lucenne实现搜索。实则分为俩个步骤:第一步,读取数据在内存或者硬盘中建立索引。第二步,对索引
文件实现搜索并返回结果。
第一步:建立索引
相对而言这一步是相当消耗时间,计算过将10万条数据进行建立索引需要20几秒,这里建议使用一个异步线程或者定时任务
等等。
第二部:索引查询
通过多种query组合进行不同方式的查询
二:整合代码
1.实现简单的查询
(1)config配置:统一配置,配置索引位置索引操作以及流的各种操作
package com.lucene.lucene.config;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
* lucene的配置
* @author monxz
*
*/
public class LuceneConfig {
//索引库地址
public static String dir="D:/lucene";
//中文分词器
public static Analyzer analyzer =new IKAnalyzer(false); //最细粒度分词
//lunece版本号
public static Version version=Version.LUCENE_47;
// 写对象
private static IndexWriter writer = null;
public static void readList(List<Document> list) throws Exception{
list.forEach(o->{
try {
write(o);
} catch (Exception e) {
e.printStackTrace();
}
});
coloseWriter(writer);
}
/**
* 查询
* @param key 要查的属性
* @param value 要查的类似的值
* @throws IOException
* @throws ParseException
*/
public static List<Document> exQuery(Query query) throws Exception {
List<Document> res=new ArrayList<Document>();
//读取document文件
IndexReader reader=null;
reader = getIndexReader();
IndexSearcher search =new IndexSearcher(reader);
TopDocs topDocs = search.search(query, 10);
System.out.println("result:"+topDocs.totalHits);
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc scoreDoc:scoreDocs){
//根据文档对象ID取得文档对象
Document doc=search.doc(scoreDoc.doc);
res.add(doc);
}
coloseReader(reader);
return res;
}
//========================流操作==========
/**
* 获取IndexWriter 同一时间 ,只能打开一个 IndexWriter,独占写锁 。内建线程安全机制
* @return
* @throws Exception
*/
public static IndexWriter getIndexWriter() throws Exception {
FSDirectory fs = FSDirectory.open(new File(dir));
// 判断资源是否占用
if (writer == null || !writer.isLocked(fs)) {
synchronized (LuceneConfig.class) {
if (writer == null || !writer.isLocked(fs)) {
// 创建writer对象
writer = new IndexWriter(fs,
new IndexWriterConfig(version, analyzer));
}
}
}
return writer;
}
/**
* 关掉流
* @param reader
*/
private static void coloseReader(IndexReader reader) {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获取到IndexReader 任意多个IndexReaders可同时打开,可以跨JVM。
* @return
* @throws Exception
*/
public static IndexReader getIndexReader() throws Exception {
// 创建IdnexWriter
FSDirectory fs = FSDirectory.open(new File(dir));
// 获取到读
return IndexReader.open(fs);
}
/**
* 关闭独流
* @param writer
*/
private static void coloseWriter(IndexWriter writer) {
try {
if (writer != null) {
writer.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
//========索引操作===============
/**
* 删除所有的索引
*/
public static void deleteAll() throws Exception{
IndexWriter writer = null;
// 获取IndexWriter
writer = getIndexWriter();
// 删除所有的数据
writer.deleteAll();
int cnt = writer.numDocs();
System.out.println("索引条数\t" + cnt);
// 提交事物
writer.commit();
coloseWriter(writer);
}
/**
* 创建索引
* @param doc
* @throws Exception
*/
public static void write(Document doc) throws Exception{
IndexWriter iwriter = null;
iwriter=getIndexWriter();
iwriter.addDocument(doc);
//提交事务
iwriter.commit();
}
/**
* 跟新索引
* @param key
* @param value
* @param doc
* @throws Exception
*/
public static void updateIndex(String key ,String value,Document doc) throws Exception {
IndexWriter iwriter=getIndexWriter();
iwriter.updateDocument(new Term(key,value), doc);
}
}
(2)匹配各种查询
package com.lucene.lucene.util;
import java.util.List;
import javax.print.Doc;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.queryparser.classic.QueryParser.Operator;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.WildcardQuery;
import com.lucene.lucene.config.LuceneConfig;
/**
* 全属性检索,全文检索
* @author monxz
*
*
*/
public class luceneUtil {
public static void write(List<Document> doclist) throws Exception {
LuceneConfig.readList(doclist);
}
/**
* 精确查询单条件
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> accurateQuery(String key,String value) throws Exception {
TermQuery tq=new TermQuery(new Term(key,value));
return LuceneConfig.exQuery(tq);
}
/**
* 前缀查询单条件
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> preQuery(String key,String value) throws Exception {
PrefixQuery pq=new PrefixQuery(new Term(key,value));
return LuceneConfig.exQuery(pq);
}
/**
* 通配符查询单条件
* 例如:key:"email" value:"*@qq.com" 查询为qq邮箱的用户
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> willQuery(String key,String value) throws Exception {
WildcardQuery wq=new WildcardQuery(new Term(key,value));
return LuceneConfig.exQuery(wq);
}
/**
* 多数据查询,比如查询一个内容中的同时存在的多个条件单条件
* 例如:{"name","a,b",1} 查询 axb等类型的姓名
* {"name","a,b,c",2} 查询axxbxxc等的姓名
* 注意step的长度永远比value。split(",")小1位
* @param key
* @param value
* @param step
* @return
* @throws Exception
* @throws LuceneException
*/
public static List<Document> paraseQuery(String key,String value,int step) throws Exception {
PhraseQuery pq = new PhraseQuery();
pq.setSlop(step);
for(String s:value.split(",")) {
pq.add(new Term(key,s));
}
return LuceneConfig.exQuery(pq);
}
/**
* 模糊查询单条件
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> likeQuery(String key,String value) throws Exception {
FuzzyQuery fq=new FuzzyQuery(new Term(key, value));
return LuceneConfig.exQuery(fq);
}
/**
* 范围查询单条件
* @param key
* @param value范围 如"1,3"标识1~3
* @param needBegin 需要第一个数据
* @param needEnd 需要第二个数据
* @return
* @throws Exception
*/
public static List<Document> rangeQuery(String key,String value,boolean needBegin,boolean needEnd) throws Exception {
Query query=NumericRangeQuery.newIntRange(key, Integer.parseInt(value.split(",")[0]), Integer.parseInt(value.split(",")[0]),
needBegin, needEnd);
return LuceneConfig.exQuery(query);
}
private static QueryParser getQueryParser(){
QueryParser parser =new QueryParser(LuceneConfig.version,"content", LuceneConfig.analyzer);
return parser;
}
/**
* 通用方法的
* @param value
* @return
* @throws Exception
*/
public static List<Document> commonQuery(String value) throws Exception{
QueryParser parser = getQueryParser();
parser.setAllowLeadingWildcard(true);
Query query = parser.parse(value);
return LuceneConfig.exQuery(query);
}
}(3)模拟数据以及测试
package com.lucene.lucene;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.queryparser.classic.ParseException;
import com.lucene.lucene.util.luceneUtil;
public class test {
/**
* 模拟从数据库中拉取的数据
* @return
*/
public static List<Document> createDoc() {
String[] str= {"a","b","c","d","e","f","g","h","i","j","k"};
//模拟从数据库中拉取的数据01
List<Map<String, Object>> query4MysqlList=new ArrayList<Map<String,Object>>();
for(int i=0;i<10;i++) {
Map<String, Object> map=new HashMap<String, Object>();
map.put("foodid", "foodid"+str[i]);
map.put("foodname", "foodname"+str[i]);
map.put("price", "price"+str[i]);
map.put("imagepath", "imagepath"+str[i]);
query4MysqlList.add(map);
}
//模拟从数据库中拉取的数据02
for(int i=0;i<5;i++) {
Map<String, Object> map=new HashMap<String, Object>();
map.put("email", i+"@qq.com");
query4MysqlList.add(map);
}
//模拟从数据库中拉取的数据03
for(int i=0;i<5;i++) {
Map<String, Object> map=new HashMap<String, Object>();
map.put("email", i+"@163.com");
query4MysqlList.add(map);
}
//模拟从数据库中拉取的数据04
Map<String, Object> map=new HashMap<String, Object>();
map.put("email", "i love you");
query4MysqlList.add(map);
//模拟从数据库中拉取的数据05
for(int i=0;i<5;i++) {
Map<String, Object> map1=new HashMap<String, Object>();
map1.put("name", "网三"+i);
query4MysqlList.add(map1);
}
//模拟从数据库中拉取的数据06
for(int i=0;i<20;i++) {
Map<String, Object> map1=new HashMap<String, Object>();
map1.put("age", i);
query4MysqlList.add(map1);
}
//将数据写入document
List<Document> list=new ArrayList<Document>();
query4MysqlList.forEach(o->{
Document doc=new Document();
// doc.add(new TextField("foodname", o.get("foodname").toString(), Field.Store.YES));
o.keySet().forEach(key->{
doc.add(new TextField(key, o.get(key).toString(),Field.Store.YES));
});
list.add(doc);
});
return list;
}
public static void main(String[] args) throws Exception {
// List<Document> list=createDoc();
// luceneUtil.write(list);
//精确
// List<Document> list1= luceneUtil.accurateQuery("foodname","foodnamea");
// List<Document> list1= luceneUtil.commonQuery("foodname:foodnamea");
//前缀查找
// List<Document> list1= luceneUtil.preQuery("foodname","food");
// List<Document> list1= luceneUtil.commonQuery("foodname:food*");
// list1.forEach(o->{
// System.out.println("===============");
// System.out.println(o.get("foodname"));
// System.out.println(o.get("foodid"));
//
// });
//通配符查找qq邮箱
// List<Document> list2= luceneUtil.willQuery("email","*@*");
// List<Document> list2= luceneUtil.commonQuery("email:*@*");
//多数据间隔,注意这是对于一个短语中间间隔单词的使用
// List<Document> list2= luceneUtil.paraseQuery("email","i,you",1);
// List<Document> list2= luceneUtil.commonQuery("\"i you\"~1"); ---多数据使用有问题,版本问题
//模糊查询
// List<Document> list2= luceneUtil.likeQuery("email", "com");
// List<Document> list2= luceneUtil.commonQuery("email:com~");
//===============================多条件==================
// list2.forEach(o->{
// System.out.println("===============");
// System.out.println(o.get("email"));
//
// });
}
}
2.实现分页以及排序
(1)修改配置文件
package com.lucene.lucene.config;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
* lucene的配置
* @author monxz
*
*/
public class LuceneConfig {
//索引库地址
public static String dir="D:/lucene";
//中文分词器
public static Analyzer analyzer =new IKAnalyzer(false); //最细粒度分词
//lunece版本号
public static Version version=Version.LUCENE_47;
// 写对象
private static IndexWriter writer = null;
//当前数据所在集合的位置
protected static int pageNum=1;
//当前数据每一页显示的数据
protected static int pageSize=10;
//排序
public static Sort sort=new Sort();
/**
* 批量读取document,并创建索引
* @param list
* @throws Exception
*/
public static void readList(List<Document> list) throws Exception{
list.forEach(o->{
try {
write(o);
} catch (Exception e) {
e.printStackTrace();
}
});
coloseWriter(writer);
}
/**
* 查询
* @param key 要查的属性
* @param value 要查的类似的值
* @throws IOException
* @throws ParseException
*/
public static List<Document> exQuery(Query query) throws Exception {
List<Document> res=new ArrayList<Document>();
//读取document文件
IndexReader reader=null;
reader = getIndexReader();
IndexSearcher search =new IndexSearcher(reader);
//添加排序
TopDocs topDocs =null;
if(sort.getSort() != null && sort.getSort().length !=0) {
topDocs = search.search(query, pageNum * pageSize,sort);
}else {
topDocs = search.search(query, pageNum * pageSize);
}
System.out.println("querySql:"+query);
System.out.println("totalNum:"+topDocs.totalHits);
//取出所有的锁具
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
List<ScoreDoc> resList=new ArrayList<ScoreDoc>();
//对数据进行分页处理
for(int i=0; i<scoreDocs.length;i++) {
if(pageNum == 1 ) {
resList=Arrays.asList(scoreDocs);
break;
}
if(scoreDocs.length > (pageNum -1)*pageSize && i> ((pageNum -1)*pageSize-1) ) {
resList.add(scoreDocs[i]);
}
}
//实现查询
for (ScoreDoc scoreDoc:resList){
Document doc=search.doc(scoreDoc.doc);
res.add(doc);
}
coloseReader(reader);
return res;
}
//========================流操作==========
/**
* 获取IndexWriter 同一时间 ,只能打开一个 IndexWriter,独占写锁 。内建线程安全机制
* @return
* @throws Exception
*/
public static IndexWriter getIndexWriter() throws Exception {
FSDirectory fs = FSDirectory.open(new File(dir));
// 判断资源是否占用
if (writer == null || !writer.isLocked(fs)) {
synchronized (LuceneConfig.class) {
if (writer == null || !writer.isLocked(fs)) {
// 创建writer对象
writer = new IndexWriter(fs,
new IndexWriterConfig(version, analyzer));
}
}
}
return writer;
}
/**
* 关掉流
* @param reader
*/
private static void coloseReader(IndexReader reader) {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获取到IndexReader 任意多个IndexReaders可同时打开,可以跨JVM。
* @return
* @throws Exception
*/
public static IndexReader getIndexReader() throws Exception {
// 创建IdnexWriter
FSDirectory fs = FSDirectory.open(new File(dir));
// 获取到读
return IndexReader.open(fs);
}
/**
* 关闭独流
* @param writer
*/
private static void coloseWriter(IndexWriter writer) {
try {
if (writer != null) {
writer.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
//========索引操作===============
/**
* 删除所有的索引
*/
public static void deleteAll() throws Exception{
IndexWriter writer = null;
// 获取IndexWriter
writer = getIndexWriter();
// 删除所有的数据
writer.deleteAll();
int cnt = writer.numDocs();
System.out.println("索引条数\t" + cnt);
// 提交事物
writer.commit();
coloseWriter(writer);
}
/**
* 创建索引
* @param doc
* @throws Exception
*/
public static void write(Document doc) throws Exception{
IndexWriter iwriter = null;
iwriter=getIndexWriter();
iwriter.addDocument(doc);
//提交事务
iwriter.commit();
}
/**
* 跟新索引
* @param key
* @param value
* @param doc
* @throws Exception
*/
public static void updateIndex(String key ,String value,Document doc) throws Exception {
IndexWriter iwriter=getIndexWriter();
iwriter.updateDocument(new Term(key,value), doc);
}
}
(2)查询方式
package com.lucene.lucene.util;
import java.util.ArrayList;
import java.util.List;
import javax.print.Doc;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.queryparser.classic.QueryParser.Operator;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.FuzzyQuery;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.PhraseQuery;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.Sort;
import org.apache.lucene.search.SortField;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.WildcardQuery;
import org.apache.lucene.search.BooleanClause.Occur;
import com.lucene.lucene.config.LuceneConfig;
import com.mysql.fabric.xmlrpc.base.Array;
/**
* 全属性检索,全文检索
* @author monxz
*
*
*/
public class luceneUtil extends LuceneConfig{
/**
* 分页
* @param pageNum
* @param pageSize
* @param sorts1
*/
public static void setPageData(int pageNum1,int pageSize1,String[] sorts1) {
pageNum =pageNum1 == 0? 1:pageNum1;
pageSize=pageSize1;
List<SortField> list=new ArrayList<SortField>();
SortField[] strs= {};
if(sorts1 !=null && sorts1.length !=0) {
for(int i=0;i<sorts1.length;i++) {
SortField sf=new SortField(sorts1[i].split(":")[0],SortField.Type.DOUBLE,sorts1[i].split(":")[1].trim().equals("0"));
list.add(sf);
}
strs=new SortField[list.size()-1];
}
sort.setSort(list.toArray(strs));
}
// /**
// * 设置排序
// */
// private static void setSort() {
// Sort sort=new Sort();
// List<SortField> list=new ArrayList<SortField>();
// if(sorts !=null && sorts.length !=0) {
// for(int i=0;i<sorts.length;i++) {
// SortField sf=new SortField(sorts[i].split(":")[0],SortField.Type.DOUBLE,sorts[i].split(":")[1].trim().equals("0"));
// list.add(sf);
// }
// }
// SortField[] strs=new SortField[list.size()-1];
// sort.setSort(list.toArray(strs));
// }
/**
* 写document入索引文件
* @param doclist
* @throws Exception
*/
public static void write(List<Document> doclist) throws Exception {
LuceneConfig.readList(doclist);
}
/**
* 精确查询单条件
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> accurateQuery(String key,String value) throws Exception {
TermQuery tq=new TermQuery(new Term(key,value));
return LuceneConfig.exQuery(tq);
}
/**
* 前缀查询单条件
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> preQuery(String key,String value) throws Exception {
PrefixQuery pq=new PrefixQuery(new Term(key,value));
return LuceneConfig.exQuery(pq);
}
/**
* 通配符查询单条件
* 例如:key:"email" value:"*@qq.com" 查询为qq邮箱的用户
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> willQuery(String key,String value) throws Exception {
WildcardQuery wq=new WildcardQuery(new Term(key,value));
return LuceneConfig.exQuery(wq);
}
/**
* 多数据查询,比如查询一个内容中的同时存在的多个条件单条件
* 例如:{"name","a,b",1} 查询 axb等类型的姓名
* {"name","a,b,c",2} 查询axxbxxc等的姓名
* 注意step的长度永远比value。split(",")小1位
* @param key
* @param value
* @param step
* @return
* @throws Exception
* @throws LuceneException
*/
public static List<Document> paraseQuery(String key,String value,int step) throws Exception {
PhraseQuery pq = new PhraseQuery();
pq.setSlop(step);
for(String s:value.split(",")) {
pq.add(new Term(key,s));
}
return LuceneConfig.exQuery(pq);
}
/**
* 模糊查询单条件
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> likeQuery(String key,String value) throws Exception {
FuzzyQuery fq=new FuzzyQuery(new Term(key, value));
return LuceneConfig.exQuery(fq);
}
/**
* 范围查询单条件
* @param key
* @param value范围 如"1,3"标识1~3
* @param needBegin 需要第一个数据
* @param needEnd 需要第二个数据
* @return
* @throws Exception
*/
public static List<Document> rangeQuery(String key,String value,boolean needBegin,boolean needEnd) throws Exception {
Query query=NumericRangeQuery.newIntRange(key, Integer.parseInt(value.split(",")[0]), Integer.parseInt(value.split(",")[0]),
needBegin, needEnd);
return LuceneConfig.exQuery(query);
}
//======================通用方法查询QueryParser==============
/**
* 通用方法QueryParser的配置
* @return
*/
private static QueryParser getQueryParser(){
QueryParser parser =new QueryParser(LuceneConfig.version,"content", LuceneConfig.analyzer);
parser.setAllowLeadingWildcard(true);
return parser;
}
/**
* 通用方法的
* @param value
* @return
* @throws Exception
*/
public static List<Document> commonQuery(String value) throws Exception{
QueryParser parser = getQueryParser();
parser.setAllowLeadingWildcard(true);
Query query = parser.parse(value);
return LuceneConfig.exQuery(query);
}
//====================多条件查询BooleanQuery
/**
* 多域多条件查询 (用or连接条件)
* @param key
* @param value
* @return
* @throws Exception
*/
public static List<Document> orQuery(String[] bdss) throws Exception{
BooleanQuery query = new BooleanQuery();
for(String s:bdss){
query.add(getQueryParser().parse(s),Occur.SHOULD);
}
return LuceneConfig.exQuery(query);
}
/**
* 多域多条件查询(多条件用and来来连接)
* andQuery:(这里用一句话描述这个方法的作用). <br/>
* TODO(这里描述这个方法适用条件 – 可选).<br/>
* @param bdss
* @return
* @throws Exception
* @author monxz
* @time:2019年7月4日下午10:03:34
* @since JDK 1.8
*/
public static List<Document> andQuery(String[] bdss) throws Exception{
BooleanQuery query = new BooleanQuery();
for(String s:bdss){
query.add(getQueryParser().parse(s),Occur.MUST);
}
return LuceneConfig.exQuery(query);
}
}(3)数据测试
package com.lucene.lucene;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.queryparser.classic.ParseException;
import com.lucene.lucene.config.LuceneConfig;
import com.lucene.lucene.util.luceneUtil;
public class test {
/**
* 模拟从数据库中拉取的数据
* @return
*/
public static List<Document> createDoc() {
String[] str= {"a","b","c","d","e","f","g","h","i","j","k"};
//模拟从数据库中拉取的数据01
List<Map<String, Object>> query4MysqlList=new ArrayList<Map<String,Object>>();
for(int i=0;i<100;i++) {
Map<String, Object> map=new HashMap<String, Object>();
map.put("foodid", i);
map.put("foodname", "foodname"+i);
map.put("price", "price"+i);
map.put("imagepath", "imagepath"+i);
query4MysqlList.add(map);
}
//模拟从数据库中拉取的数据02
// for(int i=0;i<5;i++) {
// Map<String, Object> map=new HashMap<String, Object>();
// map.put("email", i+"@qq.com");
// query4MysqlList.add(map);
// }
//模拟从数据库中拉取的数据03
// for(int i=0;i<5;i++) {
// Map<String, Object> map=new HashMap<String, Object>();
// map.put("email", i+"@163.com");
// query4MysqlList.add(map);
// }
//
//模拟从数据库中拉取的数据04
// Map<String, Object> map=new HashMap<String, Object>();
// map.put("email", "i love you");
// query4MysqlList.add(map);
//模拟从数据库中拉取的数据05
// for(int i=0;i<5;i++) {
// Map<String, Object> map1=new HashMap<String, Object>();
// map1.put("name", "网三"+i);
// query4MysqlList.add(map1);
// }
//模拟从数据库中拉取的数据06
// for(int i=0;i<20;i++) {
// Map<String, Object> map1=new HashMap<String, Object>();
// map1.put("age", i);
// query4MysqlList.add(map1);
// }
//
//将数据写入document
List<Document> list=new ArrayList<Document>();
query4MysqlList.forEach(o->{
Document doc=new Document();
o.keySet().forEach(key->{
doc.add(new TextField(key, o.get(key).toString(),Field.Store.YES));
});
list.add(doc);
});
return list;
}
public static void main(String[] args) throws Exception {
// List<Document> list=createDoc();
// luceneUtil.write(list);
//精确
// List<Document> list1= luceneUtil.accurateQuery("foodname","foodnamea");
// List<Document> list1= luceneUtil.commonQuery("foodname:foodnamea");
//前缀查找
// List<Document> list1= luceneUtil.preQuery("foodname","food");
// List<Document> list1= luceneUtil.commonQuery("foodname:food*");
//
// list1.stream().forEach(o->{
// System.out.println("===============");
// System.out.println(list1.size());
// System.out.println(o.get("foodname"));
// System.out.println(o.get("foodid"));
//
// });
//通配符查找qq邮箱
// List<Document> list2= luceneUtil.willQuery("email","*@*");
// List<Document> list2= luceneUtil.commonQuery("email:*@163.com");
//多数据间隔,注意这是对于一个短语中间间隔单词的使用
// List<Document> list2= luceneUtil.paraseQuery("email","i,you",1);
// List<Document> list2= luceneUtil.commonQuery("\"i you\"~1"); ---多数据使用有问题,版本问题
//模糊查询
// List<Document> list2= luceneUtil.likeQuery("email", "com");
// List<Document> list2= luceneUtil.commonQuery("email:com~");
//===============================多条件==================
//
// list2.forEach(o->{
// System.out.println("===============");
// System.out.println(o.get("email"));
//
// });
//====================多条件查询
// String[] ss={"foodname:food~","foodname:*1"};
// List<Document> list2= luceneUtil.orQuery(ss);
// list2.forEach(o->{
// System.out.println("===============");
// System.out.println(o.get("foodname"));
//
// });
//============分页查询
String[] sorts= {"foodid:1"};
luceneUtil.setPageData(5, 5, sorts); //设置分页
List<Document> list1= luceneUtil.preQuery("foodname","food");
list1.stream().forEach(o->{
System.out.println("===============");
System.out.println("本页总数"+list1.size());
System.out.println(o.get("foodname"));
System.out.println(o.get("foodid"));
});
}
}
说明:lucene自身没有任何分页排序方式,我们需要对命中数据进行处理
ps: (1).实现多条件查询
方法一: 使用BooleanQuery来连接条件 其中Occur.Must 相当于 && Occur.Should 相当于 || Occur.Must_Not 相当于 !
说明:形如String[] ss={"foodname:food~","foodname:*a"};
List<Document> list2= luceneUtil.orQuery(ss);
查询:foodname以food开头的,foodname以a结尾的,其中2个条件以or相连
方法二:MultiFieldQueryParser进行多条件,多方法查询
(2)实现分页查询
方案一:search.search(query, numIndex+pagesize)方法中添加查询,好像网络上都是这种方法来取的
方案二:ScoreDoc[] scoreDocs=topDocs.scoreDocs这里采用了foreach来通过pageNum和pageSize来取。事实上Document
doc=search.doc(scoreDoc.doc)之前lucene的数组都是轻量级的,不需要担心资源问题。
方案三:二次查询topDocs.totalHits这个获取出所有数据的条数
我们采取的方案为:
(1)取出pageNum * pageSize条数据
(2)机取出符合改业请求的数据
(3)实现排序查询
例如:String[] sorts= {"foodid:1"}; 1:代表降序,0代表升序
三:测试工具
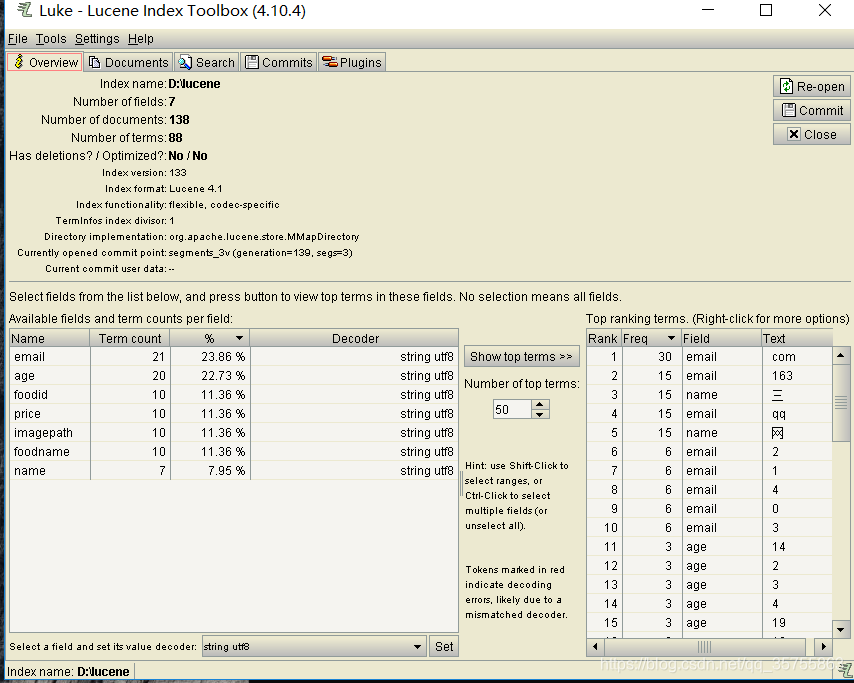
1.使用luke查看索引文件中的数据内容
https://github.com/DmitryKey/luke/releases下载完成,解压运行luke.sh或者运行jar