一、需要明确数据库中相关的概念
-
实体:现实世界中客观存在并可以被区别的事物,比如“一个学生”、“一本书”、“一门课”等等。
值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,比如说“老师与学校的关系”。 -
属性:教科书上解释为:“实体所具有的某一特性”,由此可见,属性一开始是个逻辑概念,比如说,“性别”是“人”的一个属性。在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
-
元组:表中的一行就是一个元组。
-
分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系型数据库了。
-
码(键):表中可以唯一确定一个元组的某个属性(或者属性组),
如果这样的码有不止一个,那么它们都被称作候选码(候选键),
我们从候选码中挑选一个出来,它就叫主码(主键)。 -
全码:如果一个码包含了所有的属性,这个码就是全码。
-
主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
-
非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
-
外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
二、依赖
- 依赖:在数据表中,属性(属性组)X确定的情况下,可以完全确定属性Y,就可以说属性Y是依赖于属性(属性组)X的,记作X→Y;
- 完全依赖:完全依赖是针对属性组来说的,当一组属性X能确定Y的时候就可以说Y完全依赖于X;
- 部份依赖:一组属性X中的其中一个或几个属性能确定Y就说Y部份依赖于X;
- 函数传递依赖:设X,Y是关系R中互不相同的属性集合,存在X→Y(Y!→X),Y→Z,则称Z传递函数依赖于X;
三、范式
- 第一范式(1NF)
特点:每一列要保持原子特征
列是基本数据项,不能进行拆分,否则设计成一对多的关系;
因为不满足第一范式,就不能称之为关系型数据库;
例1:
学生表(学号、姓名、性别、年龄、地址)
地址1:陕西省西安市****大学
地址2:陕西省显示 ** 区 ** 路 ****大学
地址信息包含省市区可以拆分
拆分改造后:
学生表(学号、姓名、性别、年龄、地址ID)
地址表(地址ID、省、市、区)
例2:
下表就是不符合第一范式所规定的原子性的,不符合关系型数据库的基本要求的话,在关系型数据库中这个表的操作就不成功;
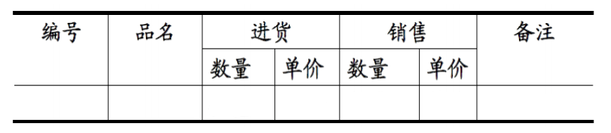
将上面的数据表重新设计成下表:

- 第二范式(2NF)
特点:属性必须依赖于主键(针对联合主键 来消除部分依赖)(当一个第一范式的候选键只有一个属性的时候,它就是第二范式)
在1NF的基础上,非主属性完全依赖于主键,如果不是依赖主键,应该拆分成新的主体,拆分成一对多的关系;
举例:
学生选课表(学生ID、学生姓名、学生性别、可而成名称、课程成绩)
主键(学生ID、课程名称)
有这样的依赖关系:
学生姓名 → 学生ID → 部分依赖
学生性别 → 学生ID → 部分依赖
课程成绩 → (学生ID、课程名称) →完全依赖
拆分改造后:
学生表(学生ID、学生姓名、学生性别) 主键:学生ID
成绩表(课程ID、课程名、学生ID、成绩) 主键:课程ID
键(课程ID、学生ID)
- 第三范式(3NF)
特点:在2NF的基础上,属性不依赖于其他非主属性(消除依赖传递)
举例:
学生表(学生ID、学生姓名、学生性别、学院名称、学院电话)
主键:学生ID
依赖关系:
- 学生姓名 → 学生ID
- 学生ID → 学生ID
- 学院名称 → 学生ID
- 学院电话 → 学生ID → 查询学院→ 查询学院电话
拆分改造后:
- 学生表(学生ID、学生姓名、学生性别、学院ID)
主键:学生ID - 学院表(学院ID、学院名称、学院电话)
主键:学院ID
- BC范式(BCNF)
特点:主属性不能对候选键存在部分函数依赖或者传递函数依赖
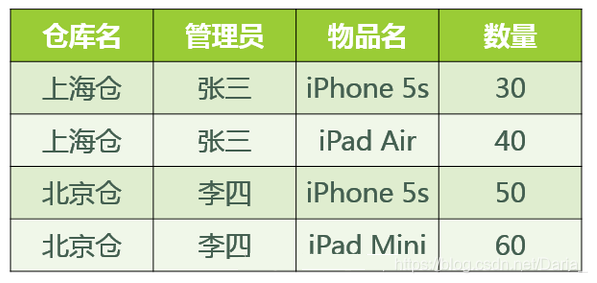
这张表不存在部分函数依赖于传递函数依赖,属于第三范式。
主属性:仓库名、管理员、物品名
非主属性:数量
表中的依赖关系:
- 仓库名→管理员
- 管理员→仓库名
- 物品名→数量
存在的问题:
- 先新增加一个仓库,但尚未存放任何物品,不可以为该仓库指派管理员,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。
- 某仓库被清空后,该仓库的信息也被清空。
- 当需要更换仓库管理员,该仓库存放了多少物品,就要修改多少条信息。
在这个问题中就是存在了主属性对于候选码的部分依赖,也就是仓库名对于管理员和物品名的部分依赖。
修改为
仓库(仓库名,管理员)
库存(仓库名、物品数、数量)
- 第四范式(4NF)
消除表中的多值依赖
设R是一个关系模型,D是R上的多值依赖集合。如果D中存在凡多值依赖X→Y时,X必是R的超键,那么称R是第四范式的模式。
例如,职工表(职工编号,职工孩子姓名,职工选修课程)
在这个表中,同一个职工可能会有多个职工孩子姓名,同样,同一个职工也可能会有多个职工选修课程,即这里存在着多值事实,不符合第四范式。如果要符合第四范式,只需要将上表分为两个表,使它们只有一个多值事实,例如
职工表一(职工编号,职工孩子姓名)
职工表二(职工编号,职工选修课程)
两个表都只有一个多值事实,所以符合第四范式。
总结:
- 范式之间的关系:
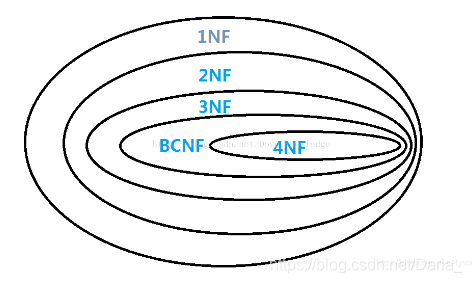
- 通过范式学习:应用范式越高,表越多、会带来的问题
- 查询时需要连接多个表,增加了查询的复杂性;
- 查询时需要连接多个表,降低了数据库查询的性能(效率);
所以范式并不是越高越好,一般满足3NF即可
四、范式的作用和优点
作用:
数据库范式是进数据库设计时字段、库表划分的依据;
优点:
- 减少数据冗余(最主要的好处、其他好处因此而附带);
- 消除异常(插入异常、更新异常、删除异常);
- 让数据组织的更加和谐。