1、Storm流式处理:
Storm vs. mapreduce
Storm:面向实时
缺点:吞吐能力差
优点:时效性好,毫秒级别,增量式处理
Mapreduce:面向批量
缺点:时效性差
优点:吞吐能力强,适合批处理
2、Storm:没有持久化功能——》快
可靠性:保证消息处理
本地模式
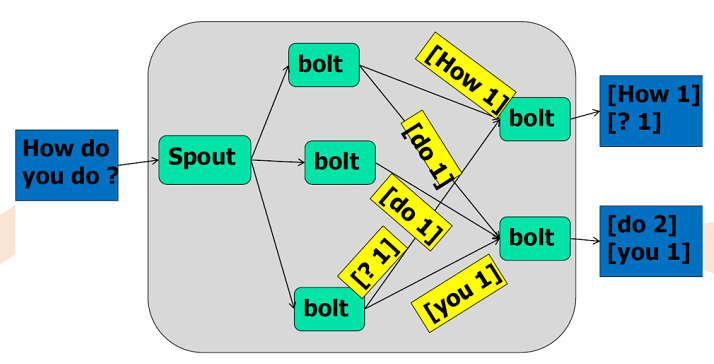
原语:spout和bolt
3、Storm基本概念:

1)Stream:数据流
2)Tuple:最基本的数据单元
3)Topology:网络拓扑
Grouping:Shuffle/Fields
4)Spout:消息生产者
可以对接很多类型的数据流
收集消息处理的ack、fail
5)Bolt:消息处理逻辑
过滤、访问外部服务、数据格式化、聚合、汇总。。。
可以发送多条流
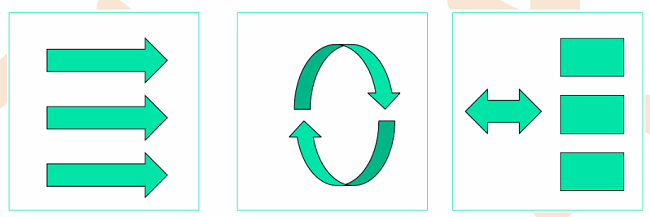
4、常见模式:
(1)流式
(2)持续计算——机器学习迭代
(3)分布式RPC——独立服务
5、架构:
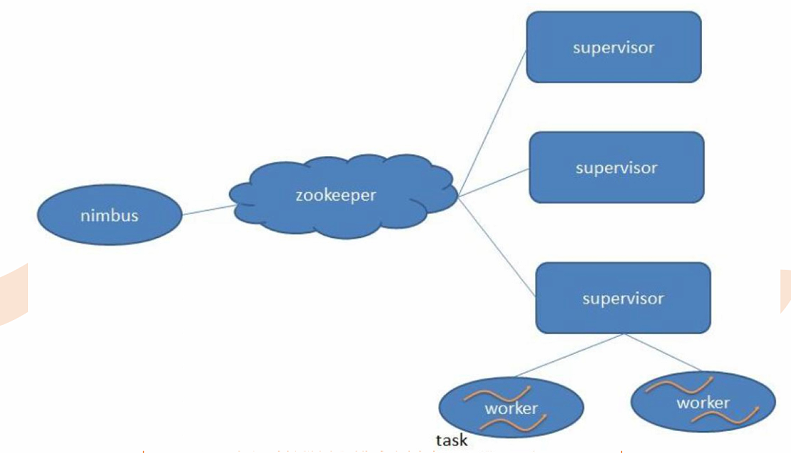
主:Nimbus:分配工作
如果挂掉:重启之后,像什么事情没有发生一样——无状态(快速失败fail-fast)
意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
从:Supervisor:监控工作
快速失败fail-fast,监控Worker工作
Worker:工作进程
Task:线程
spout和bolt的线程都是task
executor进程,里面维护很多task,每次只会执行一个task
Zookeeper协调管理




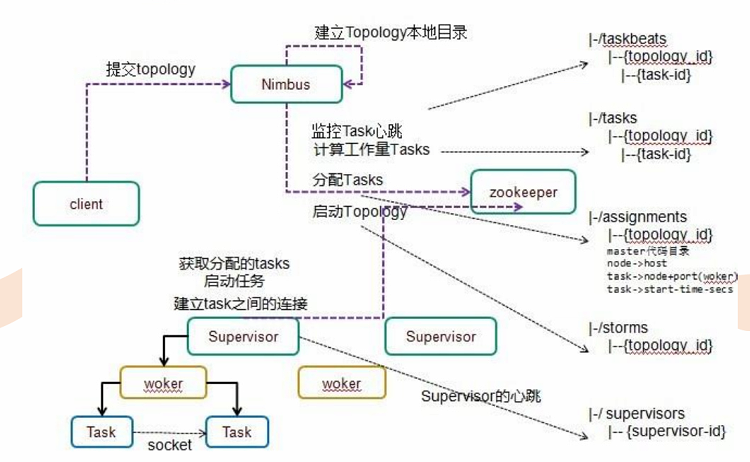
6、容错:
架构容错

数据容错:
(1)timeout
(2)ack机制:本质是一个特殊的task