朴素贝叶斯基础
基本概念:
条件概率:指事件 A 在另外一个事件 B 已经发生条件下的概率
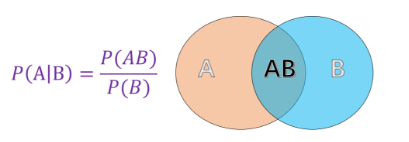
贝叶斯定理:P(AB)=P(A∣B)∗P(B)--->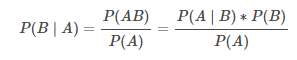
先验概率:先验概率(Prior Probability)指的是根据以往经验和分析得到的概率。例如以上公式中的 P(A),P(B)P(A),P(B),又例如:X 表示投一枚质地均匀的硬币,正面朝上的概率,显然在我们根据以往的经验下,我们会认为 X的概率 P(X)=0.5P(X)=0.5 。其中 P(X)=0.5P(X)=0.5 就是先验概率。
后验概率:后验概率(Posterior Probability)是事件发生后求的反向条件概率;即基于先验概率通过贝叶斯公式求得的反向条件概率。例如公式中的 P(B∣A) 就是通过先验概率 P(A)和P(B)P(B)得到的后验概率,其通俗的讲就是「执果寻因」中的「因」。
朴素贝叶斯:

朴素贝叶斯中的「朴素」,即条件独立,表示其假设预测的各个属性都是相互独立的,每个属性独立地对分类结果产生影响,对于预测数据,求解在该预测数据的属性出现时各个类别的出现概率,将概率值大的类别作为预测数据的类别
算法实现:

"""生成示例数据
"""
import pandas as pd
def create_data():
data = {"x": ['r', 'g', 'r', 'b', 'g', 'g', 'r', 'r', 'b', 'g', 'g', 'r', 'b', 'b', 'g'],
"y": ['m', 's', 'l', 's', 'm', 's', 'm', 's', 'm', 'l', 'l', 's', 'm', 'm', 'l'],
"labels": ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B']}
data = pd.DataFrame(data, columns=["labels", "x", "y"])
return data
data = create_data()
data
参数估计
根据朴素贝叶斯的原理,最终分类的决策因素是比较 P(类别1∣特征),P(类别2∣特征),…,P(类别m∣特征) 各个概率的大小,根据贝叶斯公式得知每一个概率计算的分母 P(特征)P(特征) 都是相同的,只需要比较分子 P(类别)和 P(特征∣类别)乘积的大小。
那么如何得到 P(类别),以及 P(特征∣类别)呢?在概率论中,可以应用极大似然估计法以及贝叶斯估计法来估计相应的概率。
极大似然估计
设甲箱中有99个白球,1个黑球;乙箱中有1个白球.99个黑球。现随机取出一箱,再从抽取的一箱中随机取出一球,结果是黑球,这一黑球从乙箱抽取的概率比从甲箱抽取的概率大得多,这时我们自然更多地相信这个黑球是取自乙箱的。一般说来,事件A发生的概率与某一未知参数 ![]() 有关,
有关, ![]() 取值不同,则事件A发生的概率
取值不同,则事件A发生的概率 ![]() 也不同,当我们在一次试验中事件A发生了,则认为此时的
也不同,当我们在一次试验中事件A发生了,则认为此时的![]() 值应是t的一切可能取值中使
值应是t的一切可能取值中使 ![]() 达到最大的那一个,极大似然估计法就是要选取这样的t值作为参数t的估计值,使所选取的样本在被选的总体中出现的可能性为最大
达到最大的那一个,极大似然估计法就是要选取这样的t值作为参数t的估计值,使所选取的样本在被选的总体中出现的可能性为最大
目的就是利用已知样本结果,反推最有可能造成这个结果的参数值。
极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:「模型已定,参数未知」。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
