生成模型的框架
让我们从两维开始玩生成模型游戏。 我选择了一条规则,用于生成图1-4中的X点集。我们称这个规则为pdata。 您面临的挑战是在空间中选择不同的数据点x =(x1,x2),使它看起来是由同一规则生成的。
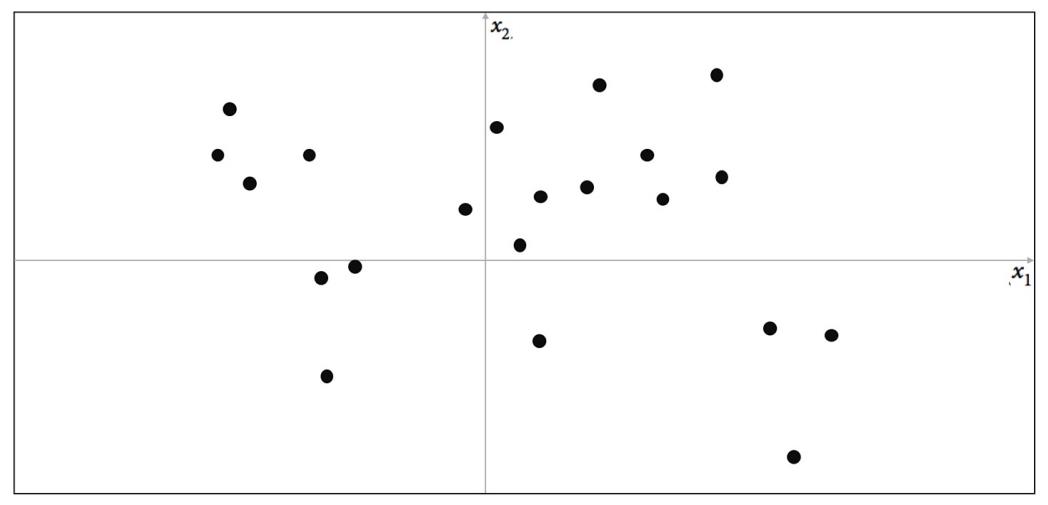
图1-4 由一个未知规则pdata生成的一组二维点
你在哪里选择呢? 呢可能使用你对现有数据点的了解来构建心理模型pmodel,该模型可能更容易找到空间中的位置。 在这方面,pmodel是pdata的估计值。 也许你认为pmodel应该如图1-5所示 - 一个可以找到点的矩形框,以及一个没有机会找到任何点的框外区域。 要生成新观测,您可以在框中随机选择一个点,或者更正式地从分布pmodel中选择一个样本。 恭喜你,你刚刚设计了你的第一个生成模型
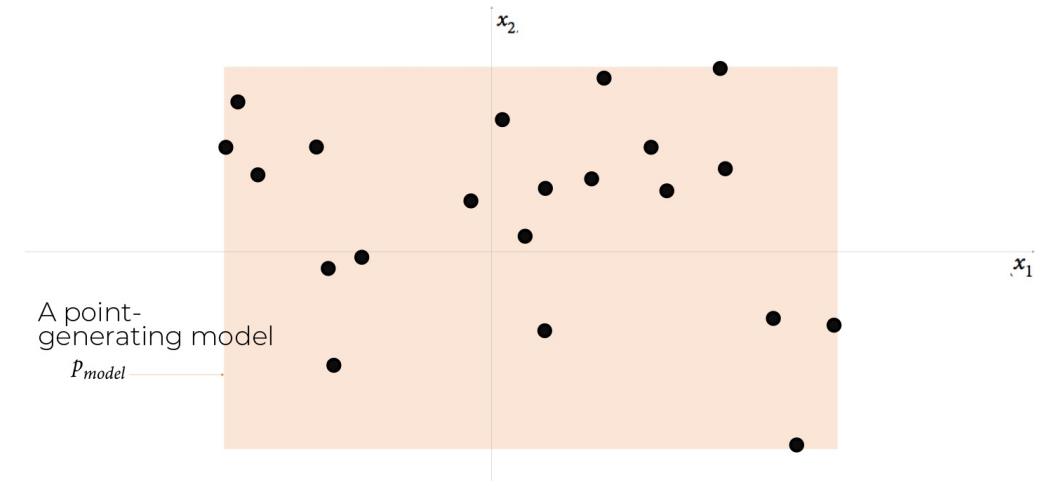
图1-5 橙色框pmodel是对真实数据生成分布pdata的估计
虽然这不是最复杂的例子,但我们可以用它来了解生成建模试图实现的目标。 以下框架阐述了我们的动机。
生成建模框架
1 我们有一个观测X的数据集。
2 我们假设观察结果是根据一些未知的分布pdata产生的。
3 生成模型pmodel试图模仿pdata。 如果我们实现这一目标,我们可以从pmodel进行采样,以生成看似从pdata中提取的观测值。
4 我们对pmodel印象深刻,如果:
规则1:它可以生成看似从pdata中提取的示例。
规则2:它可以生成与X中的观测结果恰当不同的示例。换句话说,模型不应该简单地复制它已经看到的事物。
现在让我们揭示真正的数据生成分布pdata,并看看框架如何应用于这个例子。
正如我们从图1-6中看到的那样,数据生成规则只是在世界陆地上的均匀分布,而不是在海中找到一个点。
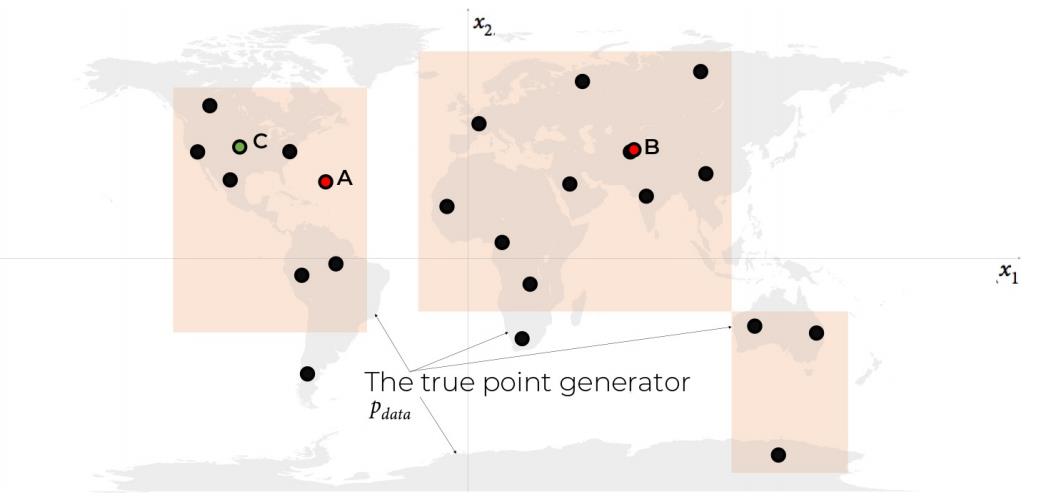
图1-6 橙色框pmodel是对真实数据生成分布pdata(灰色区域)的估计
显然,我们的模型pmodel是对pdata的过度简化。 点A,B和C显示由pmodel生成的三个观测结果,取得了不同程度的成功:
点A打破了生成建模框架的规则1 - 它似乎不是由pdata生成的,因为它位于海。
B点非常接近数据集中的一个点,我们不应该对它们留下深刻的印象,即我们的模型可以生成这样一个点。如果模型生成的所有示例都是这样的,那么它将破坏生成建模框架的规则2。
点C可以被认为是成功的,因为它可以由pdata生成并且与原始数据集中的任何点适当地不同。
生成建模领域多种多样,问题定义可以采用多种形式。 但是,在大多数情况下,生成建模框架捕获了我们应该如何广泛地考虑解决问题。
现在让我们构建我们生成模型的第一个非常重要的例子。