MHA / MGR / ProxySQL
基于复制高可用
复制模型变革
建议选择:GTID+ROW,auto_position
基于keepalived实现主从故障切换
问题处理:需要自己实现健康检查脚本/脑裂处理/故障切换后原节点怎么加入进来
特别备注:在云环境中该结构不能搭建
基于MHA的高可用
描述:
MHA基于SSH信息做操作,无agent
主从故障,会基于从库选举处理一个提升为主库,原来的主库变成故障的从库(有补日志的逻辑)
切换也可以对外提供VIP,也可以基于名字服务类
MHA通常结合Proxy模型使用,利用Proxy做从库的读的负载
基于DNS或接入服务的高可用
接入服务:
zookeeper
ectd
DNS (bind-dlz)
consul
基于DRBD模型的高可用
描述:
基于网络块复制的 [raid1] 结构
写入受限于网络IO
Stand By 机器不能对外提供服务
数据文件损坏,两台机器同时损坏
MySQL NDB CLuster
描述:
官方主推的一个结构
提供NoSQL访问接口可以省去SQL Node
DataNode 受限于48个节点,整体高性能数据都在内存
Percona XtraDB Cluster
基于Proxy模型的高可用
描述
连接池功能
透明读写分离
从库负载均衡
SQL审计
透明拆分
后面操作透明
业界优秀的Proxy推荐
ProxySQL
https://github.com/sysown/proxysql
MyCAT -> DBLE
https://github.com/MyCATApache/Mycat-Server
Cetus
https://github.com/cetus-tools/cetus
shareding-shpare (京东金融开源)
MySQL 5.7 Group Replication
描述
强同步模型
支持single-master/muti-master模型
share nothing结构,任何节点没有共享数据
基于多源复制高可用
描述
需要MySQL5.7以上版本
基于GTID
单节点写入,任何节点都可以写入
任何节点都可以读取
切换实现需要自己实现
基于多源复制高可用的优势
模拟GR的实现
运维方式改变毕竟少
发生故障修复简单
自主实现MySQL高可用
基于Raft实现高可用
基于共享存储的高可用方案
要求:
基于MySQL5.5后的版本,支持Fast Crash Recovery
因为一份数据,需要有一个从库去备份数据
存储的IO隔离问题
Standby 机器资源浪费
改进
利用一个Standby机器,接管1-3组的故障切换,一旦切换,就不再接管其他切换
少量闲置,更多的重用
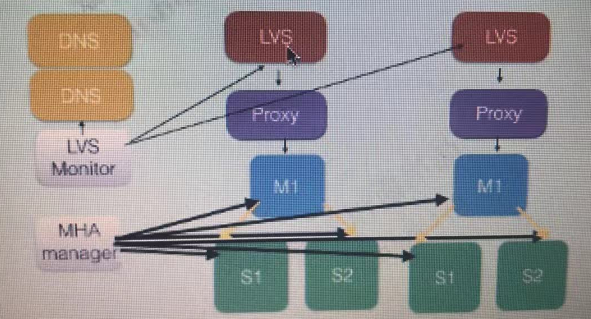
业界四层架构设计
1. 基于域名提供数据库访问
2. 利用LVS full nat提供Proxy层负载均衡
3. Proxy层提供DB的读写分离及拆分
4. DB层使用MHA或是其他高可用技术,搞定故障切换
新的高可用方向
replication-manager (美的)
https://github.com/signal18/replication-manager
orchestrator (京东,滴滴,曹操专车)
https://github.com/github/orchestrator