学习scrapy爬虫需要,不得不设计xpath 知识点训练。
练习xpath使用方法。参考:https://cuiqingcai.com/2621.html
1、准备资源
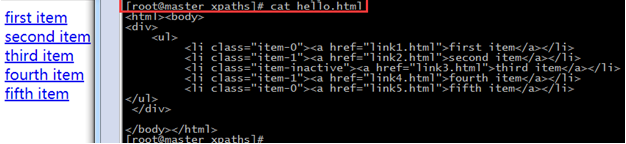
[root@master xpaths]# cat hello.html
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
访问地址和文件
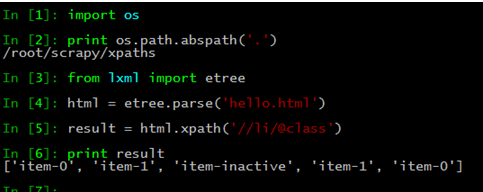
2、基础环境演示
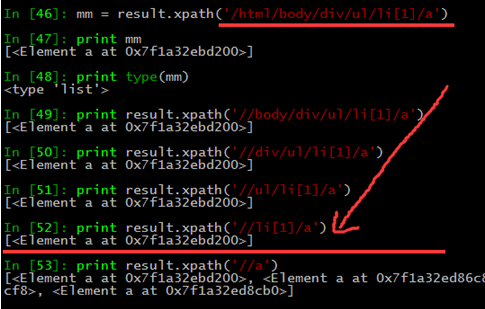
3、//路径用法。
页面获取xpath绝对路径。
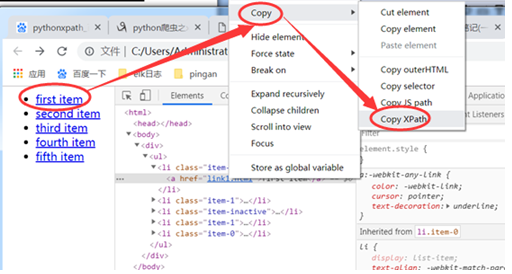
结果:/html/body/div/ul/li[1]/a
如下,//使用方法正常,从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
4、@选择属性
a标签属性的获取方法。
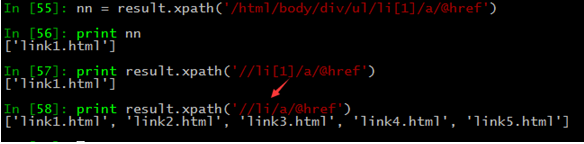
如上,获取的href链接地址信息。
属性放在中间的位置处理。

完成。