由漫威电影公司出品的科幻电影<复仇者联盟3:无限战争>,于2018年5月11日在中国大陆上映,得到了观众的广泛好评,今天我们一起来看看网友们看完后的心得.
下面是爬取到的部分数据:
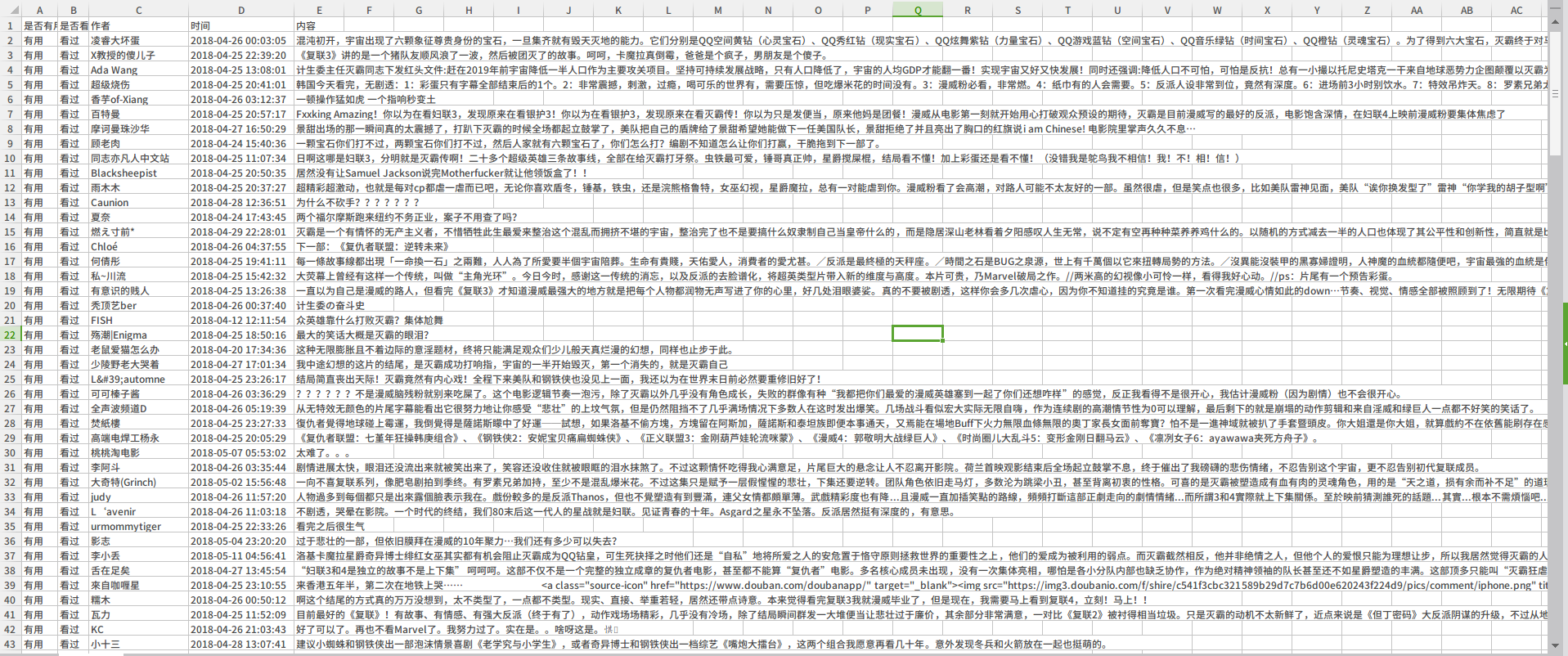
下面是完整代码:
环境:Python3.6
import requests
import re
import time
import os
import xlsxwriter
# 用于记录写入数据的条数
data_cursor = 1
# 创建工作文件
def write_data():
# 删除文件
if os.path.exists('./复仇者联盟3评论信息.xlsx'):
os.remove('复仇者联盟3评论信息.xlsx')
# 创建工作文件
workbooke = xlsxwriter.Workbook('复仇者联盟3评论信息.xlsx')
# 创建工作表
worksheet = workbooke.add_worksheet()
# 写标题
worksheet.write(0, 0, '是否有用')
worksheet.write(0, 1, '是否看过')
worksheet.write(0, 2, '作者')
worksheet.write(0, 3, '时间')
worksheet.write(0, 4, '内容')
return workbooke, worksheet
def main():
global data_cursor
try:
page_num = int(input("请输入页数:"))
# 创建excel文件
workbooke, worksheet = write_data()
for page in range(page_num):
# 评论url地址
# url = "https://movie.douban.com/subject/4920389/comments?start=" + str(
# page * 20) + "&limit=20&sort=new_score&status=P&percent_type="
url = "https://movie.douban.com/subject/24773958/comments?start=" + str(
page * 20) + "&limit=20&sort=new_score&status=P&percent_type="
# 获取网页源代码
html = requests.get(url)
html.encoding = 'utf-8'
html = html.text
# 正则匹配得到需要的数据
result = re.findall(
r'<a href="javascript:;" class="j a_show_login" onclick="">(.*?)</a>'
r'.*?<a href="https://www.douban.com/.*?" class="">(.*?)</a>'
r'.*?<span>(.*?)</span>'
r'.*?<span class="comment-time " title="(.*?)">.*?</span>'
r'.*?<p class=""> (.*?)</p>',
html, re.S)
# print(result, len(result))
for index, item in enumerate(result):
# 用用 作者 看过 时间 评论内容
# print(item[0], item[1], item[2], item[3], item[4].strip(''))
# 写入数据
worksheet.write(data_cursor, 0, item[0])
worksheet.write(data_cursor, 1, item[2])
worksheet.write(data_cursor, 2, item[1])
worksheet.write(data_cursor, 3, item[3])
worksheet.write(data_cursor, 4, item[4])
data_cursor += 1
print('第{}页完成...'.format(page + 1))
# 每一页之间间隔1秒
time.sleep(1)
except Exception as e:
print(e)
finally:
# 关闭文件对象
workbooke.close()
if __name__ == '__main__':
main()