一、安装pandas
pip install pandas
二、数据结构
pandas有两种数据结构,这里篇幅主要讲述DataFrame。
DataFrame相当于一种二维的数据模型,相当于excel表格中的数据,有横竖两种坐标,横轴很Series 一样使用index,竖轴用columns 来确定,在建立DataFrame 对象的时候,需要确定三个元素:数据,横轴,竖轴。
三、DataFrame基本使用
1 创建DataFrame数据
创建不是我们本次的重点,我们所直接使用下列读取现有表的方法
2 读取excel/csv,读取到的数据在DataFrame具柄中进行处理
# 读取test.xls,并指定sheet df = pd.DataFrame(pd.read_excel('test.xls',sheet_name='detail'))
3 抽取指定列名赋值给need_df
# 指定列名,将这一列赋值到package_num_df 这个具柄,并打印结果 need_df = df[['工厂','仓库','捆包号','树种','规格','账面数量','账面米数']] print(need_df)
4 在need_df的dataframe中筛选[捆包号]=J-0001-04,并打印结果
find_need_df = need_df.loc[need_df['捆包号'] == 'J-0001-04'] print(find_need_df)
5在df的dataframe中删除label标签=1 的数据并打印结果(dataframe只存在于内存中,并不会改变原来的excle表数据,可以通过将内容中的dataframe重新赋值给新表即可
#删除行号=1的那一整行,axis默认=0,inplace默认=False(不删除原来excel的数据) 标志为True的话就说明将存储在内存中的df 行号为1进行删除 res = df.drop(labels=1, axis=0, inplace=True) print(df)
find_need_df = need_df.loc[need_df['捆包号'] == '原来df数据
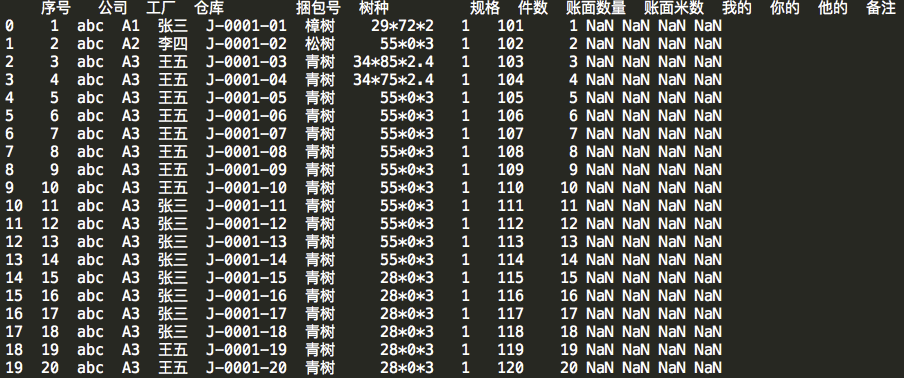
drop后df的数据
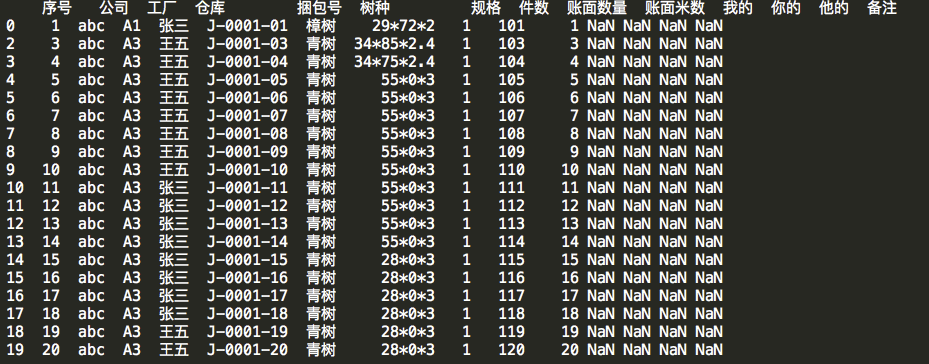
6写入excel/csv
#安装本地目录,格式化制定文件名称 wb_path = os.path.join(dir_path,'work_book') ctime = datetime.datetime.now().strftime('%Y%m%d_%H%M') df.to_excel('%s/%s_detail.xls'%(wb_path,ctime))
若遇到 # ModuleNotFoundError: No module named 'xlwt' ,则需要安装xlwt模块
find_need_df.to_csv('temp.csv', mode='a', encoding='gbk')
三、数据透视表
未完待续