1. 构造供pandas使用的DataFrame数据
import pandas as pd lst = [ ["susan", 25, "male", "北京"], ["merry", 36, "female", "杭州"], ["jake", 23, "male", "苏州"], ["mali", 12, "female", "上海"], ["wus", 42, "male", "武汉"], ] dfcols = ["name", "age", "gender", "live"] # 只含有列名的空 DataFrame(简称 DF) df = pd.DataFrame(columns=dfcols) # 两个 DF上下合并, ignore_index=True: 忽略行索引在原 DF基础上继续增加行索引 df = df.append(pd.DataFrame(data=lst, columns=dfcols), ignore_index=True) print(df)

2. 基本的DF查询数据
df.values # type: "<class 'numpy.ndarray'>" df.values.tolist() # type: "<class 'list'>" df["name"] # 获取到name 这一列的值 df.loc["index的行索引"] # 显式索引, 获取到行索引为xx的这一行数据 df.iloc[1] # 隐式索引, 获取到第2行的数据 df.loc[2, "name"] # 第2行数据的 name 值 df.loc[0:3] # 第1行 到 第3行的数据
3. DF添加一行数据 (行数据为 Series 一维数组)
df = df.append(pd.Series(["lee", 32, "female", "西安"], index=dfcols), ignore_index=True) print(df)

4. DF按条件过滤数据
# 过滤出年龄大于 30岁 的人 df[df["age"] > 30]
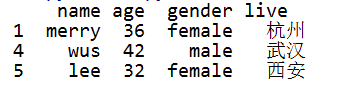
# 第2行数据的age值改为空值 df.loc[3, "age"] = None print(df)
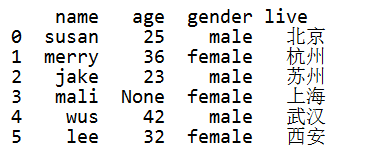
# 删除有空值的行数据 print(df[df["age"].notnull()]) # 在pandas的drop系列函数中, axis=0表示x轴数据(行数据), 1表示y轴数据(列数据) print(df.dropna(axis=0)) 上面两种方式都一样

5. groupby分组
待补充...
6. agg()方法
待补充...
7. apply()方法
待补充...