版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
最近在看一些关于Hive优化的东西,看到一个很好用的函数:Grouping Sets函数,今天就先总结一下关于这个函数的用法!
在一个GROUP BY 查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果进行UNION ALL操作。GROUPING SETS就是一种将多个GROUP BY逻辑UNION写在一个HIVE SQL语句中的便利写法。GROUPING SETS会把在单个GROUP BY逻辑中没有参与GROUP BY的那一列置为NULL值,这样聚合出来的结果,未被GROUP BY的列将显示为NULL。
使用方法:
假如现在又如下场景,a,b,num三个字段,现在要求对a,b字段分别进行统计,有三种情况:(a,b)、(a)、(b)。常规写法我们可能会写成:
SELECT a,b,sum(num) AS total_num
FROM DW_AAA.BBB
GROUP BY a,b
UNION ALL
SELECT a,sum(num) AS total_num
FROM DW_AAA.BBB
GROUP BY a
UNION ALL
SELECT b,sum(num) AS total_num
FROM DW_AAA.BBB
GROUP BY b现在用GROUPING SETS来进行改写:
SELECT a
,b
,sum(num) AS total_num
FROM DW_AAA.BBB
GROUP BY a,b
GROUPING SETS (a,b),(a),(b)可见代码简洁了很多,并且生成的job数也变少且计算的效率提高了(UNION ALL是多次扫描表)。
下面看一个案例:
有如下店铺销售数据:
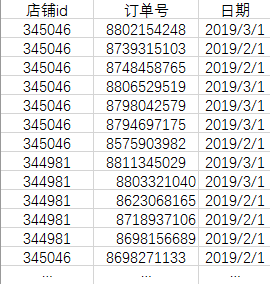
现有如下需求:按照店铺id和日期维度汇总订单量
代码如下:
SELECT businessid
,date
,count(DISTINCT orderid) AS ord_num
FROM dw_business.basic_info_detail a
GROUP BY date,businessid
grouping sets((date,businessid),(businessid))得到结果如下:
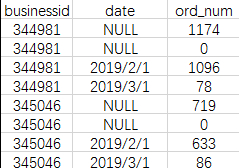
从结果中可以看出,businessid为344981的店铺,其订单量为1174,并且在二月份产单1096单,在3月份为78单。
注:
hive中grouping sets 数量较多时如何处理?
可以使用如下设置来
set hive.new.job.grouping.set.cardinality = 30;
这条设置的意义在于告知解释器,group by之前,每条数据复制量在30份以内。