Regression 回归
能够用线较为精确地描述数据之间的关系。这样当出现新的数据的时候,就能够预测出一个简单的值。回归中最常见的就是房价的问题。收集到的房屋面积和房价的数据,如下图所示:

在这种情况下,就可以利用回归模型构造出一条线来近似地描述房价与房屋面积之间的关系,从而就可以根据房屋面积推测出房价(这里也可以有多个标签,例如房间的个数,卧室的面积等)。

回归算法的输出是一个数值(标量)。例如我们想预测股市,输入到函数的就是过去的股市信息,得到预测值;无人驾驶系统我们是把车的各个传感器接收的信号作为输入,模型计算出方向盘的角度;在推荐系统中,输入的是消费者和某种商品,得到的是消费者购买的可能性,这样就可以挑选可能性高的几种商品进行推荐。

风靡全球的AR手游Pokemon Go想必大家都不陌生,回归算法的实例一就是根据神奇宝贝现有的参数,计算神奇宝贝升级后的CP值,让我们一起来看吧:
所以我们就是要找到一个function:
- input: - CP值, - 神奇宝贝种类, - HP, - Weight, - Height,我们把这些的称为Feature
- output: - 进化后的CP值。
这里的参数下标代表他的component(成分),上标代表object的编号。
在Introduction中,我们说过,做machine learning就是三个步骤:
- 找一个model(function set)
- 拿一个function看evaluate好坏
- 找到最好的function
Step1:模型Model
模型指的是一组函数的集合(function set),其中函数的输入是宝可梦的特征
(各个参数),输出是宝可梦进化后的CP值(
)。
我们采用最简单的模型(线性模型),并且假设因变量只有一个,即宝可梦进化前的cp值,则表达式为
。其中
和
均有无穷多种选择,所以函数空间中函数的取值(二元组)也为无穷多个。但是某些取值显然是不合理的,例如图中的
就是和进化前的
成反比的。
对单变量模型进行泛化,生成多变量线性模型,表达式为
。其中
表示的是每个特征的取值,
表示的是每个特征对应的权重,
表示的是偏置(bias)。

Step2:函数的评估标准
由于函数空间中函数数量众多,如果没有一个评估标准,我们则无法选择到最优函数。
这里的模型评估标准的作用对象是训练数据。即在函数空间中选择某一个函数,然后使用评估标准函数对预测后的结果进行评估,从而得到函数的优劣。

这里我们选取十对正确的数据,绘制在坐标系上。
就是我们验证过的神奇宝贝进化后的CP,之后我们引出Loss fuction这个概念:

在机器学习中,评估标准的专业术语称为损失函数(Loss Function)或者目标函数。在线性回归中,使用的是平方误差或者均方误差来作为损失函数。
其中
表示的是真实值,后者表示的是预测值。公式是对每个样本的误差求平方和。
拓展阅读:线性回归损失函数为什么要用平方形式
下图中使用等高线图表示出哪些函数区域的效果较好(上边误差较小),哪些函数区域的效果较差(下边误差较大)。

Step3:最优函数
从理论上来说,如果存在评估标准和函数空间,就可以使用穷举法选择出最优函数。但实际上来说,这是不可取的(宇宙毁灭之时也可能计算不完)。所以我们需要在有限时间内(而且不能太慢),求出最优函数。
我们把问题进行转化,把求最优函数问题转化为最优化问题。

求最优化问题有两种思路:一种是解析解,一种是使用梯度下降(迭代法)。课程只介绍了梯度下降法。
为什么能够使用梯度下降法?本质上是从微分的定义出发的。
如果导数为正、而且
为正,则
就会增加。而我们要使
减小,所以使得
注意上述公式是在
极其小的情况下才满足。在机器学习中,我们将
称作为学习率,一般取0.01或者0.001。
Gradient Descent 梯度下降

这里引入梯度下降的概念,他的作用就是快速帮我们找到Loss最小的点。
通俗的理解就是坐滑梯,在滑梯上坐下,自然就滑到底了。
数学理解就是,求微分。如果微分是负的那么就是左边高右边底,我们需要增大
,就向右下降,我们现在来看具体一次下降多少:

现在我们位于
点,向下滑动的距离就是
。由于微分是负的所以要减去这个负值来增大
,反之亦然。

图中展示的是两次下降过程,
到
,
到
。上边我们提到通常学习率使我们设置的,例如0.001。微分的结果是跟曲线倾斜度相关的,越陡峭,微分越大,一次下降的越多,越平缓,微分越小,一次下降的越少。
是Local minima局部最小,后面的是global minima全局最小。线性回归是一个凸函数,所以不用考虑局部最小,结果一定是线性最小。
我们知道,线性回归有两个参数,
和
。那么两个参数是如何同时更新的呢?
原来就是对function求偏微分,这样就可以分别更新两个参数了。如下图所示:

我们把单个参数推广到多个参数中。其中
指代的是梯度函数。
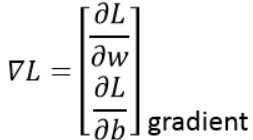
下图为梯度下降的直观图。

我们可以通过图像更好的理解下降的过程,我们可以看到,经过两次下降,Loss已经达到了很低的位置。
梯度下降存在的问题
1.局部最优化点。2.鞍点。
在这两种类型的点中,导数为0,则无法继续进行迭代,停留在当前点中。

线性回归的对应的偏微分:
我们真正关心的是,model在测试集(新data)上的表现

相比在训练集的
,测试上
是否存在更好的函数,使得训练数据和测试数据的评估误差都变小呢?根据泰勒公式,任何形式的函数都可以近似表示为若干个多项式函数之和。而我们现在使用的是线性函数,尝试使用多项式函数降低数据误差。
二次函数

三次函数

四次函数
五次函数

到目前为止,我们尝试了五个model,由折线图我们可以看出,在训练集上error rate是一直在减小的。高幂的function space是包含低幂的(即最高次幂项常数为0),所以如果梯度下降能帮我们找到best function的话,model越复杂,包含越多的function,理论上就可以找出一个function在训练集上的error rate越来越低。


但是在测试集上,越复杂的model不一定能得到更好的结果,这就是Overfitting(过拟合),如model 4和5。暂时我们选择model 3作为我们的function set。
单个特征到多个特征
之前的模型只考虑了宝可梦进化前的cp值。现在我们添加第二个特征,如宝可梦的种类。

如果我们为每个种类做if,那么对应的是这些function set。我们如何把这几个if改写成一个Liner function:这里我们使用开关函数,将他们串联在一起,起到if的作用。若种类对应则
为1反之为0。这样波波鸟就得到
蓝色框框里就是feature。

按照惯例看一下在training set和test set上的average error。可以看出即使是线性模型,训练和测试误差都很小。


课程开始的时候我们就说过,可以考虑将这神奇宝贝拥有的feature都加进去。在下图中可以看到,这么复杂的model很容易什么?Overfitting。
在我们无法简化feature的情况下,我们选择重新设计Loss function。
正则化
正则化的公式如下所示,需要注意的是正则化项不包括偏置项。因为偏执性不会改变曲线的平滑程度。
正则化公式中的
取值越大,会使得函数越平滑。这是由于
的值越大,在尽量使损失函数变小的前提下,就会使得
越小,
越小就会使得函数越平滑。

一个平滑的函数对noise不那么敏感,但是太平滑也不行,会在test set得到糟糕的结果。
λ本质上表示的是惩罚项,惩罚项过大可能就会影响学习的效果,因为惩罚项过大,就会导致参数空间变的比较小,所以最终结果一般,如下图所示:

推荐学习:奔腾老师的博客