常用相似度量及python代码实现
- 一.常用相似度量原理解析
- 1.欧几里得距离(Euclidean Distance)
- 2.皮尔逊相关度(Correlation distance)
- 3.曼哈顿距离(Manhattan Distance)
- 4.闵可夫斯基距离(Minkowski Distance)
- 5.Jaccard系数(Jaccard Distance)
- 6.余弦相似度(Cosine Distance)
- 7.马氏距离(Mahalanobis Distance)
- 8.Tanimoto系数
- 9.汉明距离(Hamming Distance)
- 10.Bregman距离
- 11.信息熵(Information Entropy)
- 12.标准欧式距离(Standardized Euclidean Distance)
- 二.python实例演示
一.常用相似度量原理解析
1.欧几里得距离(Euclidean Distance)
指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
计算公式:

你可以找到更多关于欧几里得距离的信息here.
2.皮尔逊相关度(Correlation distance)
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商
计算公式:

你可以找到更多关于皮尔逊相关度的信息here.
3.曼哈顿距离(Manhattan Distance)
我们可以定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里德空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。
产生:曼哈顿距离示意图在早期的计算机图形学中,屏幕是由像素构成,是整数,点的坐标也一般是整数,原因是浮点运算很昂贵,很慢而且有误差,如果直接使用AB的欧氏距离(欧几里德距离:在二维和三维空间中的欧氏距离的就是两点之间的距离),则必须要进行浮点运算,如果使用AC和CB,则只要计算加减法即可,这就大大提高了运算速度,而且不管累计运算多少次,都不会有误差。
你可以找到更多关于曼哈顿距离的信息here.
4.闵可夫斯基距离(Minkowski Distance)

特例:

你可以找到更多关于闵可夫斯基距离的信息here.
5.Jaccard系数(Jaccard Distance)



应用参考:项目相似性度量是协同过滤系统的核心。相关研究中,基于物品协同过滤系统的相似性度量方法普遍使用余弦相似性。然而,在许多实际应用中,评价数据稀疏度过高,物品之间通过余弦相似度计算会产生误导性结果。将杰卡德相似性度量应用到基于物品的协同过滤系统中,并建立起相应的评价分析方法。与传统相似性度量方法相比,杰卡德方法完善了余弦相似性只考虑用户评分而忽略了其他信息量的弊端,特别适合于应用到稀疏度过高的数据。
你可以找到更多关于Jaccard系数的信息here.
6.余弦相似度(Cosine Distance)
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
注意这上下界对任何维度的向量空间中都适用,而且余弦相似性最常用于高维正空间。例如在信息检索中,每个词项被赋予不同的维度,而一个维度由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。
另外,它通常用于文本挖掘中的文件比较。此外,在数据挖掘领域中,会用到它来度量集群内部的凝聚力。

你可以找到更多关于余弦相似度的信息here.
7.马氏距离(Mahalanobis Distance)
马氏距离也可以定义为两个服从同一分布并且其协方差矩阵为Σ的随机变量之间的差异程度。
如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
通俗例子:
如果我们以厘米为单位来测量人的身高,以克(g)为单位测量人的体重。每个人被表示为一个两维向量,如一个人身高173cm,体重50000g,表示为(173,50000),根据身高体重的信息来判断体型的相似程度。
我们已知小明(160,60000);小王(160,59000);小李(170,60000)。根据常识可以知道小明和小王体型相似。但是如果根据欧几里得距离来判断,小明和小王的距离要远远大于小明和小李之间的距离,即小明和小李体型相似。这是因为不同特征的度量标准之间存在差异而导致判断出错。
以克(g)为单位测量人的体重,数据分布比较分散,即方差大,而以厘米为单位来测量人的身高,数据分布就相对集中,方差小。马氏距离的目的就是把方差归一化,使得特征之间的关系更加符合实际情况。
图(a)展示了三个数据集的初始分布,看起来竖直方向上的那两个集合比较接近。在我们根据数据的协方差归一化空间之后,如图(b),实际上水平方向上的两个集合比较接近。
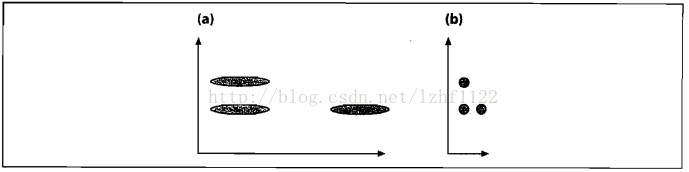
例子转载来源 https://blog.csdn.net/lzhf1122/article/details/72935323
更多可参考:https://www.jianshu.com/p/5706a108a0c6
更多可参考:https://blog.csdn.net/panglinzhuo/article/details/77801869
你可以找到更多关于马氏距离的信息here.
8.Tanimoto系数

9.汉明距离(Hamming Distance)
汉明距离是以理查德·卫斯里·汉明的名字命名的。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。

你可以找到更多关于汉明距离的信息here.
10.Bregman距离




更多可参考豆丁页面: https://www.docin.com/p-1622895250.html
你可以找到更多关于Bregman距离的信息here.
11.信息熵(Information Entropy)
更多可参考:https://blog.csdn.net/am290333566/article/details/81187124
你可以找到更多关于信息熵的信息here.
12.标准欧式距离(Standardized Euclidean Distance)


二.python实例演示
以实际生活中的影评数据为例,进而对每位用户进行个性化影片推荐: