一、文件
(一)写入文件
file1 = open('name.txt','w')
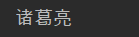
file1.write('诸葛亮'+'\n'+'刘备'+'\n'+'关羽')
file1.close()
(二)读取文件
1.单行读取
file4 = open('name.txt')
print(file4.readline()) #readline单行读取
2.逐行读取
file5 = open('name.txt')
for line in file5.readlines(): #readlines逐行读取
print(line)

(三)文件指针
需求:操作完成后,回到文件开头位置。
需要用到 tell()函数, tell()告诉用户文件的指针在哪儿。
seek()函数,其中可以写入两个参数:第一个为偏移位置,第二个参数 0表示从文件开头偏移,1表示从当前位置偏移,2表示从文件结尾偏移。
如:seek(5,0)表示从文件开头偏移5个位置。
file6 = open('name.txt')
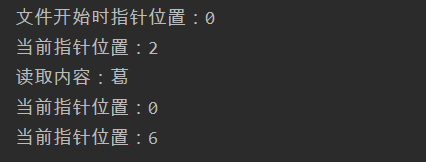
print('文件开始时指针位置:%s' %file6.tell())
file6.read(1) #读取一个
print('当前指针位置:%s' %file6.tell())
print('读取内容:%s' %file6.read(1))
file6.seek(0)
print('当前指针位置:%s' %file6.tell())
file6.seek(6,0)
print('当前指针位置:%s' %file6.tell())
(四)其他操作
name.txt:

weapon.txt:

#读取人物名称
f = open('name.txt')
data = f.read() #读取的内容
print(data.split('1')) #用'1‘做分割
#读取兵器名称
f2 = open('weapon.txt')
i = 1
for line in f2.readlines()
if i%2 ==1:
print(line.strip('\n')) #输出的内容中去掉每行的换行符
i +=1
f3 = open('sanguo.txt',encoding='GB18030') #中文问题,以GB18030字符编码打开
print(f3.read().replace('\n'),'') #把文件中所有的换行符替换为空
二、异常的检测和处理
 异常:
异常:
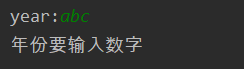
year = int(input('year:'))

异常处理:
try:
year = int(input('year:'))
except ValueError:
print('年份要输入数字')
其他操作:
- except可以用于多个异常的处理,但要把它们放在一个元组中。
except (ValueError,KeyError,……)
- 希望不但显示错误信息,还要显示给用户的错误时操作。
异常:
print(1/0)

try:
print(1/0)
except ZeroDivisionError as e: #把错误信息重命名为一个变量e
print('0不能做除数%s' %e)

- 捕获全部的错误信息,Exception
try:
print(1/'a')
except Exception as e: #把所有错误信息重命名为一个变量e
print('%s' %e)

- 自己定义新的错误信息
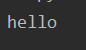
try:
raise NameError('helloError') #把NameError定义为helloError
except NameError:
print('hello')
- 不论是否产生错误,都要执行finally
try:
a = open('name.txt')
except Exception as e: #打开文件失败,输出错误信息
print(e)
finally:
a.close()
三、函数

(一)函数定义和调用
def func(filename):
print(open('filename').read())
func('name.txt')
import re
def find_item(hero): #统计名字在小说中出现的次数
with open('sanguo.txt',encoding='GB18030') as f:
data = f.read().replace('\n','')
name_num = re.findall(hero,data) #findall函数打印hero在data中出现的字符
print('主机 %s 出现 %s 次' %(hero,len(name_num)))
return len(name_num)
#读取人物的信息
name_dict = {}
with open('name.txt') as f: #f是指向文件的一个变量
for line in f:
names = line.split(']')
for n in names:
name_sum = find_item(n) #名字对应的次数
name_dict[n] = name_sum
(二)函数传参
函数中的参数需要按顺序输入,如果想跳过某个参数,可以使用关键字参数。
例子:

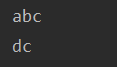
print('abc',end='\n')
print('dc')
例子:
def func(a,b,c):
print('a=%s' %a)
print('b=%s' %b)
print('c=%s' %c)
func(1,c=3,b=2)
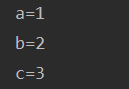
可变长参数
可边长参数前面加*,表示是可选的。
def howlong(first,*other):
print(1+len(other)) #first的长度是1
howlong(123,234,34)

(三)变量作用域
函数内部和外部有变量同名。
global 用于定义全局变量。

(四)迭代器与生成器
迭代器举例:
list1 = [1,2,3]
it = iter(list1) #用iter将list1处理成迭代器
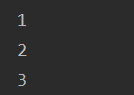
print(next(it)) #用next取it中的第一个元素
print(next(it))
print(next(it))
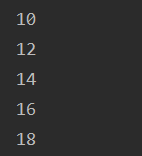
for i in range(10,20,2): #输出10——19,步长为2
print(i)
实例:编写一个步长为小数的迭代器(生成器)
#一个步长为小数的迭代器
def frange(start,stop,step):
x = start
while x < stop:
x += step
print(x)
frange(10,20,0.5)
 这里函数在最后输出的值是20.0
这里函数在最后输出的值是20.0
yield函数
如果没有加yield,函数会把所有的值一次性的返回。加入yield,会在此暂停,并且记住当前位置,当通过next调用时,会从该位置继续返回一个值。
#一个步长为小数的迭代器
def frange(start,stop,step):
x = start
while x < stop:
yield x
x += step
for i in frange(10,20,0.5):
print(i)

这里最后输出的值是19.5
(四)lambda表达式
用法:
def add(x,y):return x+y
lambda x,y : x+y
lambda x:x<=(month,day)
def func1(x):return x<=(month,day)
四、python内建函数
(一)fileter函数
filter(function or none, iterable)选择iterable中满足function或none的值。
用法:
a = [1,2,3,4,5,6,7]
b = list(filter(lambda x:x>2,a)) #选择a中大于2的数,list强制转换为列表类型否则lambda不会被执行
print(b)
(二)map函数
map(func,*iterables),对数据依次处理。
a = [1,2,3]
b = [4,5,6]
ma =list(map(lambda x:x+1,a))
print(ma)
mab=list(map(lambda x,y:x+y,a,b))
print(mab)

(三)reduce函数
reduce函数不能直接应用,必须通过functools导入。
from functools import reduce
reduce ( function , sequence [ , initial ] ),中括号的意思为初始值可以省略,作用为将序列和初始值按照函数的方式做运算,每次运行一个序列。
用法:

意思 是:((1+2)+3)+4 =10
(四)zip函数
zip( iter1, [ , iter2 [ …… ] ] )
用法:
a = (1,2,3)
b = (4,5,6)
zip(a,b)
for i in zip(a,b):
print(i)

zip函数实现字典中的key和value值对调:
dicta = {'a':'aa','b':'bb'}
dictb = dict(zip(dicta.values(),dicta.keys()))
print(dictb)
