版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
python之数据分析
为什么要进行数据分析
人工智能、大数据等数据的采集需要数据----数据通过python分析而来----进行数据的清洗操作—建立数据模型model1----生成一个目标数据—通过目标数据预测未来—得到结果
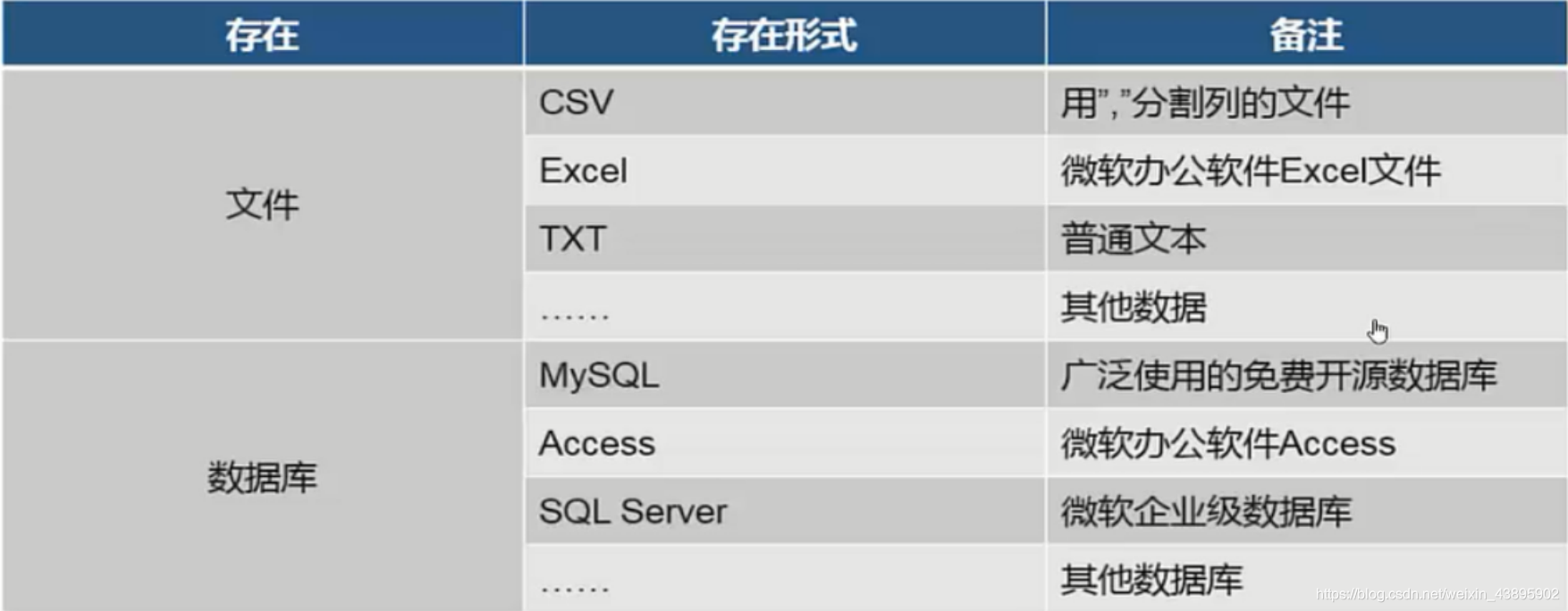
数据存在的形成
(1)存在于‘文件’,例如excel word txt csv
(2)存在于‘数据库’,例如mysql sqlserver oracle db2
import numpy as np
import pandas as pd
from pandas import read_table ,read_excel,read_csv,DataFrame,to_datetime
导入文本文件类型
- read_table在分析数据里读取文本数据,可以快速读取大数据、海量数据人工智能的数据集。
pd1=read_table('C:/ZhangTao/python课件/0806/数据处理/4.1/2.txt')
# 通过name属性修改列的名称,sep用,隔开数据
pd2 = read_table('C:/ZhangTao/python课件/0806/数据处理/4.1/2.txt', names=['age', 'name'], sep=',')
pd3 = read_table('C:/ZhangTao/python课件/0806/数据处理/4.1/2.txt', names=['年龄', '姓名'], sep=',')
# table也可以读取csv数据
pd4=read_table('C:/ZhangTao/python课件/0806/数据处理/4.1/1.csv')
# 解决数据编码格式
pd5=read_table('C:/ZhangTao/python课件/0806/数据处理/4.1/3.xls') # 'utf-8' codec can't decode byte 0xd0 in position 0
导入excel类型
- read_excel读取excel类型的数据。传统大数据开发就是在excel里进行数据分析,他可以处理大数据库!
- 在以上两个方法中可以通过name属性给列起名称方便数据的读取,通过sep分割数据
pd6=read_excel('C:/ZhangTao/python课件/0806/数据处理/4.1/3.xlsx')
导入csv文件类型
- from pandas import read_csv
导入csv的文件需要通过 read_csv
#CSv自身可以处理编码问题
pd7=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.1/1.csv',encoding='utf-8')
csv 和 word excel wps、txt等哪个处理数据集更好?
csv
解决数据的编码格式的方法
- 通过EditsPlus或者UE开发工具进行编码的切换!面对海量数据不可用代码转码,这样会导致服务器、数据等发生异常情况!建议使用第三方工具。
- csv自身可以处理编码问题
pd8=read_csv(‘d:/pythondata01/1.csv’,encoding=‘utf-8’)
总结: read_table /excel/csv 等,全部返回值是DataFrame类型
导包的/导模块的区别
#建议用什么module导入什么模块即可!
from pandas import DataFrame
#导入的是pnadas里面的所有module,Python解析器解析速度慢,在工作里面编码规范不要求这样大量写
import pandas as pd
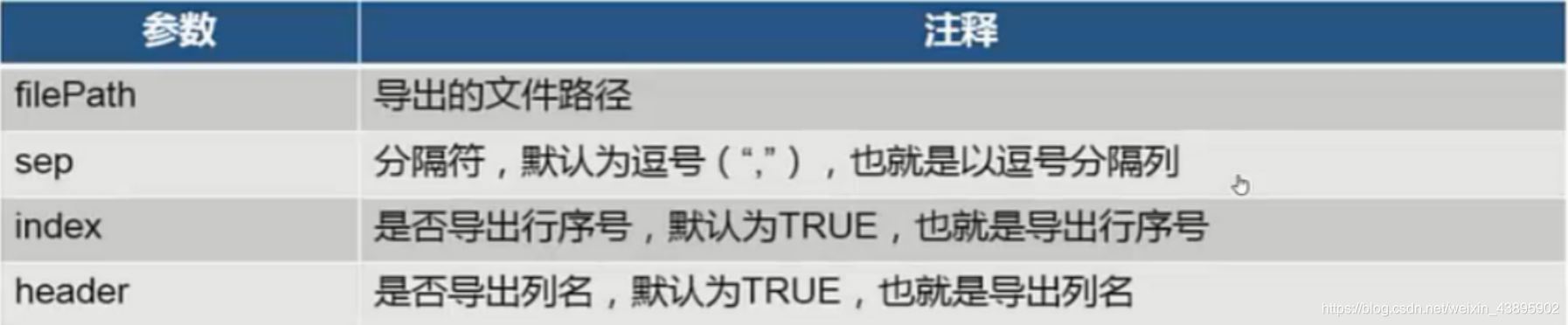
导出数据文件
- df.to_csv(‘路径’)
- 不仅仅可以自动创建数据文件,也可以将手动创建的文件,通过数据存放到文件里面!建议大量使用!安全、数据维护简单!
- 导出文件时,可以导出csv、excel、xls、xlsx、txt、doc、docx等常用的文档类型。
to_csv(filePath,sep=’,’,index=True,header=True)
#创建一个;列表数据 ,将列表数据导出文本类型、csv类型 、excel等类型.....
df=pd.DataFrame({
'name':['赵雅芝','许仙','法海','金莲','西门庆'],
'age':[120,12,34,34,55]
})
print('df的数据是:\n',df)
#导出数据
df.to_csv('d:/pythondata01/xxx.csv') # csv
df.to_csv('d:/pythondata01/xxx.xls') # xls
df.to_csv('d:/pythondata01/xxx.txt') # txt
df.to_csv('d:/pythondata01/xxx.xlsx') #xlsx
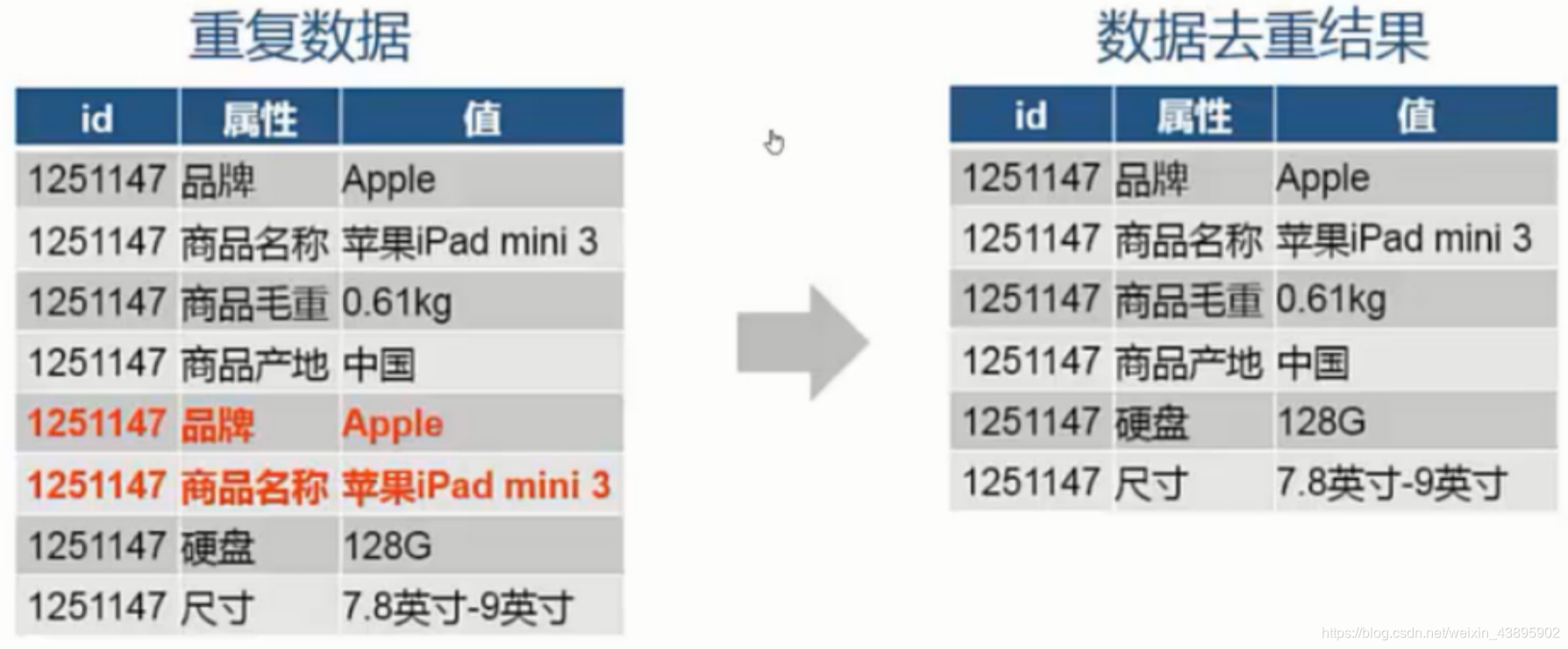
除去重复数据
- 除去数据中的重复项
- 出去重复数据函数:drop_duplicates()
# 除去重复数据
pd8=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.3/data.csv')
print('旧数据:\n',pd8)
newpd8=pd8.drop_duplicates()
print('新数据:\n',newpd8)
处理空格数据
- 清除字符型数据左右的空格
- 处理空格数据函数:strip()
# 处理空格数据 一个空格=一个字符 2个字符=一个汉字
pd9=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.4/data1.csv')
print('旧数据:\n',pd9)
newpd9=pd9['name'].str.strip(); # 移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
print('新数据:\n',newpd9)
数据字段抽取
- 根据已知列的数据的开始位置和结束位置抽取出新的列。
- 字段抽取函数:clice(start,stop)
- start:开始值
- stop:结束值
# 数据抽取
pd10=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.6/data.csv')
pd10['tel']=pd10['tel'].astype(str)
yys=pd10['tel'].str.slice(0,3);
areas=pd10['tel'].str.slice(3,7);
nums=pd10['tel'].str.slice(7,11);
print(pd10)
print(yys)
print(areas)
print(nums)
数据字段拆分
- 指的是按照固定的字符,拆分已有字符串。
- 字段拆分函数 split(‘sep’,n,expand=False)
- sep指的拆分哪个名称的列
- n表示分割列的数量
- expand表示是否展开为数据框,默认False
- 返回值:expand为True,返回DataFrame类型、expand为False,返回Series类型
# 数据字段拆分
df=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.4/data1.csv')
# newdf=df['name'].str.split(' ',1,True)
newdf=df['name'].str.split(' ',2,True)# 返回值类型 DataFrame
print(newdf)
newdf1=df['name'].str.split('',2,False) # 返回值类型series
print(newdf1)
数据记录抽取
- 指根据一定的条件,对数据进行抽取。
- 记录抽取函数:dataframe[condition]
- condition 过滤的条件,必须在数据中存在
- 返回值:DataFrame
- 常见的条件类型
- 字符匹配
- 逻辑运算
- 比较运算
- 范围运算
- 空值计算
# 数据记录抽取 其实就是对数据进行+ -等运算
df2=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.8/data1.csv',sep='|')
# 比较运算
print('选择comments中大于10000的数据\n',df2[df2.comments>10000])
# 范围运算
print('选择comments中1000-10000的数据\n',df2[df2.comments.between(1000, 10000)])
# 空值计算
print('选择title中空的数据\n',df2[pd.isnull(df2.title)])
# 字符匹配
print('选择title中包括台电的数据\n',df2[df2.title.str.contains('台电', na=False)])
# 逻辑运算
print('选择comments中>=1000并且<=10000的数据\n',df2[(df2.comments>=1000) & (df2.comments<=10000)])
数据随机抽样
- 指随机从数据中按照一定的行数或者比例抽取数据。
- 随机抽样函数:numpy.random.randint(start,end,num)
- start:范围的开始值
- end:范围的结束值
- num:抽取样数
- 返回值:行数的索引值序列
# 数据随机抽样
df3 = read_csv("C:/ZhangTao/python课件/0806/数据处理/4.9/data.csv")
r = np.random.randint(0, 10, 3)
print(df3.loc[r, :])
数据记录合并
- 通过关键字 concat 将几个结构相同的数据框合并成一个数据框。
#数据记录合并 -----通过关键字 concat 将几个结构相同的数据框合并成一个数据框
df4=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.10/data1.csv',sep='|')#data1表示的是一个数据文件
df5=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.10/data2.csv',sep='|')
df6=read_csv('C:/ZhangTao/python课件/0806/数据处理/4.10/data3.csv',sep='|')
df7 = pd.concat([df4, df5],sort=True)
# df4 = pd.concat([df, df2],sort=False)
print(df7)
df8=pd.concat([df4,df5,df6])
print(df8)
字段匹配
- 不同结构的数据框按照一定的条件进行合并。
- 字段匹配函数:merge(x,y,left_on,right_on)
- x:第一个数据框
- y:第二个数据框
- left_on:第一个数据框用于匹配的列
- right_on:第二个数据框用于匹配的列
- 返回值:DataFrame
# 字段匹配----不同结构的数据框按照一定的条件进行合并
items = read_csv("C:/ZhangTao/python课件/0806/数据处理/4.12/data1.csv", sep='|', names=['id', 'comments', 'title']);
prices = read_csv("C:/ZhangTao/python课件/0806/数据处理/4.12/data2.csv", sep='|', names=['id', 'oldPrice', 'nowPrice']);
itemPrices = pd.merge( items, prices,
left_on='id',
right_on='id'
);
print(items,'\n',prices,'\n',itemPrices)
数据标准化
- 指将数据按比例缩放,使之落入到特定区间,一般我们使用0-1标准化
# 数据标准化
df9 = read_csv("C:/ZhangTao/python课件/0806/数据处理/4.13/data.csv",sep='|');
scale = (df9.price-df9.price.min())/(df9.price.max()-df9.price.min())
print(scale)
数据分组
- 根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间部分来进行研究,以揭示其内在的联系和规律性。
- 数据分组函数:cut(series,bins,right=True,labels=NULL)
- series:需要分组的数据
- bins:分组的划分数组
- right:分组的时候,右边是否闭合
- labels:分组的自定义标签,可以不定义
# 数据分组
df10 = read_csv('C:/ZhangTao/python课件/0806/数据处理/4.15/data.csv', sep='|');
bins = [min(df10.cost)-1, 20, 40, 60, 80, 100, max(df10.cost)+1];
labels = ['20以下', '20到40', '40到60', '60到80', '80到100', '100以上'];
print('按照bins分组\n',pd.cut(df10.cost, bins))
print('按照bins分组并且右不闭合\n',pd.cut(df10.cost, bins, right=False))
print('按照bins分组并且右不闭合且添加自定义标签\n',pd.cut(df10.cost, bins, right=False, labels=labels))
日期转换
- 将字符型的日期格式的数据转换为日期型数据的过程。
- 日期转换函数:data=to_datatime(dataString,format)
- format属性及含义:
%Y------年份
%m-----月份
%d------日期
%H------小时
%M-----分钟
%S------秒
- format属性及含义:
# 日期转换
df11 = read_csv('C:/ZhangTao/python课件/0806/数据处理/4.16/data.csv');
df_dt = to_datetime(df11.注册时间, format='%Y/%m/%d')
print(df_dt)
日期格式化
- 将日期型的数据转化为字符型的日期格式数据。
- 日期格式化函数:apply(lambda x:处理逻辑)处理逻辑----datetime.strftime(x,format)
# 日期格式化
from datetime import datetime;
df12 = read_csv('C:/ZhangTao/python课件/0806/数据处理/4.17/data.csv')
df12_dt = to_datetime(df12.注册时间, format='%Y/%m/%d');
df12_dt_str = df12_dt.apply(lambda x: datetime.strftime(x, '%d-%m-%Y'));
print(df12_dt_str)
日期抽取
-
从日期格式里抽取需要的部分。
-
日期抽取函数:datetime列.dt.property
- property属性值及含义
属性 含义 second 1-60s,从1开始,到60 minute 1-60min,从1开始,到60 hour 1-24h,从1开始,到24 day 1-31,一个月中的第几天,从1开始,最大31 month 1-12,月份,从1开始,到12 year 年份 weekday 1-7,一周中的第几天,从1开始,最大为7
# 日期抽取
df13 = read_csv('C:/ZhangTao/python课件/0806/数据处理/4.18/data.csv')
df13_dt = to_datetime(df13.注册时间, format='%Y/%m/%d');
print('抽取年\n',df13_dt.dt.year)
print('抽取秒\n',df13_dt.dt.second)
print('抽取分\n',df13_dt.dt.minute)
print('抽取时\n',df13_dt.dt.hour)
print('抽取天\n',df13_dt.dt.day)
print('抽取月\n',df13_dt.dt.month)
print('抽取星期\n',df13_dt.dt.weekday)