一 AWK的简介
awk 是一种很棒的语言,它适合文本处理和报表生成,其语法较为常见,借鉴了某些语言的一些精华,如 C 语言等。在 linux 系统日常处理工作中,发挥很重要的作用,掌握了 awk将会使你的工作变的高大上。 awk 是三剑客的老大,利剑出鞘,必会不同凡响。
AWK是一种优良的文本处理工具。它不仅是 Linux 中也是任何环境中现有的功能最强大的数据处理引擎之一。这种编程及数据操作语言( awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母)的最大功能取决于一个人所拥有的知识。AWK 提供了极其强大的功能:可以进行样式装入、流控制、数学运算符、进程控制语句甚至于内置的变量和函数。它具备了一个完整的语言所应具有的几乎所有精美特性。实际上 AWK 的确拥有自己的语言:AWK 程序设计语言, 三位创建者已将它正式定义为“样式扫描(pattern)和处理语言(action)”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报 表,还有无数其他的功能。
快速掌握awk的技巧:只要记住awk是以行为单位读入和输出的。
awk语言的最基本功能描述:在文件或者字符串中(操作对象object)基于指定规则(模式pattern)浏览和抽取信息(干什么action),awk抽取信息后,才能进行其他文本操作(管道命令)。
二 使用方法
awk [option] 'pattern {action}' {filenames}(1) pattern 表示 AWK 在数据中查找的内容,pattern就是要表示的正则表达式,用斜杠括起来
(2) action 是在找到匹配内容时所执行的一系列动作命令。
(3)花括号'{}'不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。
通常awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
强调:对于处理的每一行pattern,action可能是毫无关系的操作!
三 pattern的详细介绍
(1)BEGIN 和END模式(不需要去读取文件的内容)
(2)其他pattern
1. 空模式,就是平时不添加任何模式参数的情况,即会匹配文本中的每一行,对于满足条件的行执行相应的动作;如 awk '{print $0}' test
2. 关系运算模式; 如 awk 'NF==5 {print $0}' test
关系运算符有:
<:小于
<=:小于等于
==:等于
!=:不等于
>=:大于等于
>:大于
~:与对应的正则匹配则为真
!~: 与对应的正则不匹配则为真
3. 正则模式:
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本
awk '/正则表达式/{print $0}' /etc/passwd
当正则表达式中已经存在/ 号时,需要使用转义符对其进行转义;
如awk'/\/bin\/bash$/{print $0}' /etc/passwd
除此之外,awk在使用正则模式时,使用到的正则用法属于"扩展正则表达式"
当使用{x, y}这种次数匹配的正则表达式时,需要配合--posix或--re-interval选项,否则会报错;
4. 行范围模式:pat1,pat2
注意相邻的正则表达式用逗号隔开,且都是以第一次匹配到的行为为准;
awk '/正则1/,/正则2/{动作}’ /some/file
这种方法还可以用多个关系表达式来达到效果:但相互之间用&&连接 如: awk 'NR>=3 && NR<=6 {print $0}' file 四
五 常用的内置变量
- FS 输入字段分隔符(默认是任何空格,多个分割字符); FS=":”
- OFS 输出字段分隔符,(默认值是一个空格);
- RS 输入记录分隔符(输入换行符),指定输入时的换行符,默认换行;
- ORS 输出记录分隔符(输出换行符),输出时用指定符号代替换行符,默认换行;
- FS/OFS/RS/ORS使用时都要用-v选项
- NF 表示字段数,在执行过程中对应于当前的字段数(即当前行被分割成了几列),字段数量;
- NR 表示记录数,当前处理的文本行的行号;
- FNR 同NR,各文件分别计数的行号;
- ARGC 命令行参数的个数;
- ARGV 包含命令行参数的数组,保存的是命令行所给定的各参数;
这几个内置变量和FS/OFS RS/ORS不同的是,它们是在大括号内使用,且可以直接使用,不需要用-v参数;
特点:这几个内置变量和FS/OFS RS/ORS不同的是,它们是在大括号内使用,且可以直接使用,不需要用-v参数!
三 awk的执行流程图
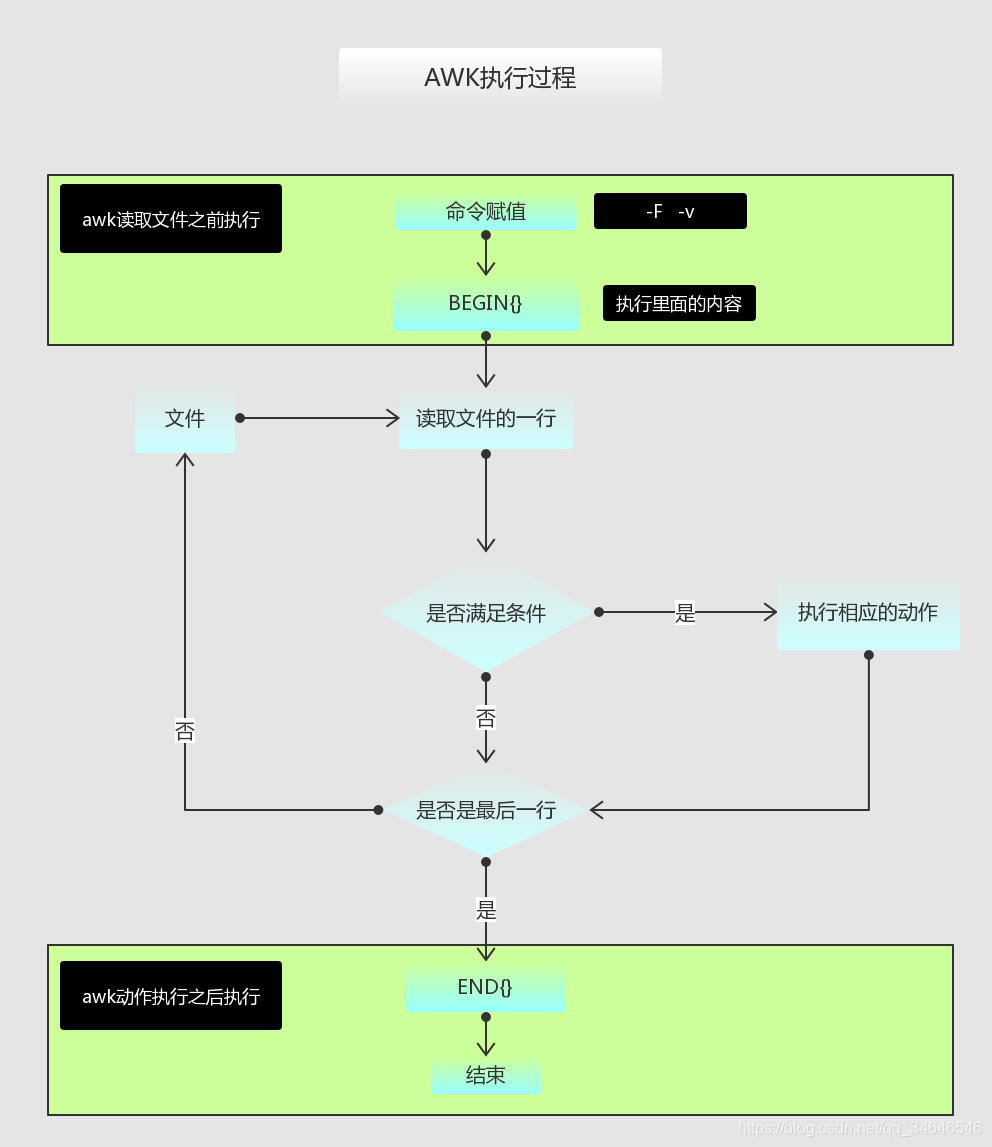
执行流程的过程说明
(1)进行逐行扫描文件(没有处理),第一行到最后一行!
(2)寻找匹配的特定模式的行,在行上进行操作!
(3)如果没有指定动作处理,则把所有的匹配都显示在标准输出!
[root@server2 ~]# awk 'NR==2' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin(4)如果没有指定模式,则所有的操作的行都被处理!
awk '{print }' /etc/passwd六 相关参数的说明

七 awk的输入来源
# 标准输入、一个或者多个文件、其它命令的输出
# shell能做的,它都可以做!echo 1 2 |awk '{print $1,$2}' #
awk -F : '{print $1,$2}' /etc/passwd # 默认OFS是空格!
ls |awk '{print $1}' # 命令行的输出八 awk的语法格式
awk [optipons] 'command' filenames
awk [optipons] -f awk-scripts filenames(1)选项
-f 从文件中读取处理命令
-F 指明行的段分隔符;分割针对输入时的数据。
# 支持模式匹配,扩展的正则表达式,目的是将行分割成为多个对象.或确定每次循环时待处理的对象
-v 自定义变量(2)命令(command)
# 处理前 行处理 行处理后
# BEGIN{} {} END{}
# 读文件前(初始化) action 扫尾处理前案例说明
# BEGIN初始化(做了一个简单计算),然后虽然读取了文件,但是没有进行任何的操作(没有action)!
awk 'BEGIN{print 12/3}' /etc/passwd # 4
# 定义字段分割字符--> 可以通过 -F :来指定!
awk 'BEGIN{FS=":";OFS=":"} {print $1,$2}' /etc/passwd
# 输出时-->OFS替换','(默认是空格符号),替换为':'
# 注意:只能识别','-->($1,$2)!
#####注意:如果不是,号,不管多少个空格都是连续的!####
awk 'BEGIN{FS=":";OFS=":"} {print $1 $2 $NF}' /etc/passwd
##### 一般OSF不这样完,下面的常用!
awk 'BEGIN{FS=":"} {print $1"----"$2 }' /etc/passwdEND
awk 'BEGIN{print 1/2} {print "ok"} END {print "wzj110"}' /etc/hosts
# 说明几行就几个OK!
0.5
ok
ok
wzj110
# 注意:单引号和双引号的关系!基础练习
awk '/^root/' /etc/passwd # 打印该行(默认)
# 模式(匹配)-->处理(动作)
awk -F : '/root/{print $1}' /etc/passwd
awk -F : '$3>=1000{print}' /etc/passwd
# mysql:x:1000:1000::/home/mysql:/sbin/nologin