目录
- 4.3、在统一进程的多线程之间,下列哪些程序状态部分会被共享?
- 4.5、第三章讨论了Google的chrome浏览器,以及在单独进程中打开每个新网站的做法。如果chrome设计成在单独线程中打开每个新网页,那么会有什么样的好处?
- 4.9、具有2个双核处理器的系统有4个处理核可用于调度。这个系统有一个cpu密集型应用程序运行。在程序启动时,所有输入通过打开一个文件而读入。同样,在程序终止前,所有程序输出的结果都写入一个文件。在程序启动和终止之间,该程序为cpu密集型。你的任务是通过多线程技术来提高这个应用程序的性能。这个应用程序运行在采用一对一线程模型的系统。
- 4.10、考虑下面的代码
- 4.15、修改第三章的习题3.13.这个修改包括写一个多线程程序,以测试你的习题3.13的解决方案
- 4.17、计算Π时的已给有趣的办法时,使用一个称为Monte Carlo的技术,这种技术涉及随机。编写一个多线程算法,它创建一组单独线程以产生一组随机点。该线程计算圈内点的数量,并将结果存储到一个全局变量。
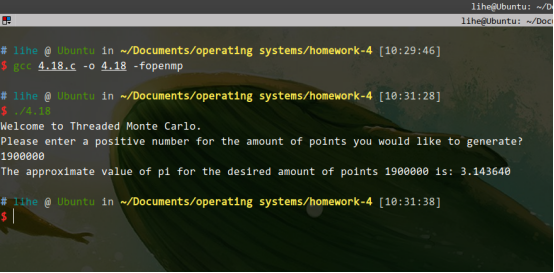
- 4.18、重复4.17,但不是使用一个单独的线程来生成随机点,而是采用OpenMP并行化点的生成。注意:不要把Π的计算放在并行区域,因为你只需要计算Π一次。
4.3、在统一进程的多线程之间,下列哪些程序状态部分会被共享?
堆内存和全局变量
4.5、第三章讨论了Google的chrome浏览器,以及在单独进程中打开每个新网站的做法。如果chrome设计成在单独线程中打开每个新网页,那么会有什么样的好处?
每个标签页都会启动一个独立的进程,这样即使因为某个页面崩溃了也不会影响到其他页面。
4.9、具有2个双核处理器的系统有4个处理核可用于调度。这个系统有一个cpu密集型应用程序运行。在程序启动时,所有输入通过打开一个文件而读入。同样,在程序终止前,所有程序输出的结果都写入一个文件。在程序启动和终止之间,该程序为cpu密集型。你的任务是通过多线程技术来提高这个应用程序的性能。这个应用程序运行在采用一对一线程模型的系统。
(1)、你将创建多少个线程,用于执行输入和输出?请解释。
线程数取决于应用程序的要求,因此创建一个线程用于执行输入和输出就足够了。
(2)、你将创建多少个形成,用于应用程序的cpu密集型部分?请解释。
线程数应该和处理核数是一样的,因此要创建四个线程。
4.10、考虑下面的代码
a.创建了多少个单独的进程?
b.创建了都少个单独的线程?
创建了5个单独的进程
创建了2个单独的线程。
4.15、修改第三章的习题3.13.这个修改包括写一个多线程程序,以测试你的习题3.13的解决方案
#include <stdlib.h>
#include <pthread.h>
#include <stdio.h>
#include <time.h>
#include <omp.h>
#include <unistd.h>
#define MIN_PID 300
#define MAX_PID 5000
#define TRUE 1
#define FALSE 0
pthread_mutex_t mutex;
int threadVar = 0;
struct PidTable{
int pid;
int isAvailable;
}*PID;
int allocate_map(){
int i;
PID = (struct PidTable*)calloc((MAX_PID - MIN_PID + 1), sizeof(struct PidTable));
if(PID == NULL) return -1;
PID[0].pid = MIN_PID;
PID[0].isAvailable = TRUE;
for(i = 1; i < MAX_PID - MIN_PID + 1; i++){
PID[i].pid = PID[i - 1].pid + 1;
PID[i].isAvailable = TRUE;
}
return 1;
}
int allocate_pid(){
int i ;
for(i = 0;i < MAX_PID - MIN_PID + 1; i++){
if(PID[i].isAvailable == TRUE){
PID[i].isAvailable = FALSE;
return PID[i].pid;
}
}
if(i == MAX_PID - MIN_PID + 1)
return -1;
else
return 0;
}
void release_pid(int pid){
PID[pid - MIN_PID].isAvailable = TRUE;
}
void *threadCall(void* X)
{
int ret = allocate_pid();
printf("%d %d\n",threadVar++, ret);
sleep(rand());
release_pid(ret);
}
int main()
{
srand(time(NULL));
int pid;
allocate_map();
pthread_t thread[100];
printf("Every thread will print the value of pid and increment it by 1.\n");
omp_set_num_threads(5);
#pragma omp parallel for
for(int i = 0; i < 100; i++){
pthread_create(&thread[i], NULL, &threadCall, NULL);
}
return 0;
}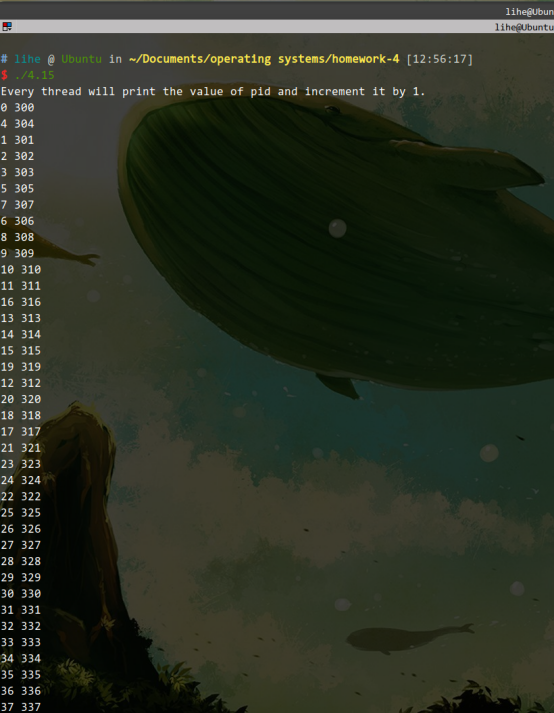
总结:在for循环中利用pthread_create创建100个线程运行threadCall函数,以检验
习题3.13的程序是否正确。
4.17、计算Π时的已给有趣的办法时,使用一个称为Monte Carlo的技术,这种技术涉及随机。编写一个多线程算法,它创建一组单独线程以产生一组随机点。该线程计算圈内点的数量,并将结果存储到一个全局变量。
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <math.h>
#include <time.h>
#include <stdlib.h>
int desired_amount = 0;
int total_points = 0;
void *count(void *X){
for (int i=0; i < desired_amount; i++){
double X = (double)rand() / RAND_MAX; // random numbers 0~1
double Y = (double)rand() / RAND_MAX;
if (((X * X) + (Y * Y)) <= 1){
total_points++;
}
}
}
int main(){
printf("Welcome to Threaded Monte Carlo.\n");
srand(time(NULL));
pthread_t thread;
do{
printf("Please enter a positive number for the amount of points you would like to generate? \n");
scanf("%d", &desired_amount);
}while (desired_amount <= 0);
pthread_create(&thread, NULL, &count, NULL);
pthread_join(thread, NULL); // End thread
double points = 4.0 * total_points;
double pi = points / desired_amount;
printf("The approximate value of pi for the desired amount of points %d is: %f \n", desired_amount, pi);
return 0;
}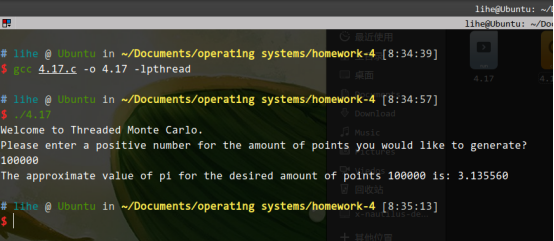
总结:利用pthread_create创建一个单独的县线程调用count生成随机点。
4.18、重复4.17,但不是使用一个单独的线程来生成随机点,而是采用OpenMP并行化点的生成。注意:不要把Π的计算放在并行区域,因为你只需要计算Π一次。
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <math.h>
#include <time.h>
#include <stdlib.h>
#include <omp.h>
int desired_amount = 0;
int total_points = 0;
double X, Y;
double wall_time;
clock_t clock_timer;
int main(){
printf("Welcome to Threaded Monte Carlo.\n");
srand(time(NULL));
do{
printf("Please enter a positive number for the amount of points you would like to generate? \n");
scanf("%d", &desired_amount);
}while (desired_amount <= 0);
omp_set_num_threads(5);
#pragma omp parallel for
for (int i=0; i < desired_amount; i++){
double X = (double)rand() / RAND_MAX; // random numbers 0~1
double Y = (double)rand() / RAND_MAX;
if (((X * X) + (Y * Y)) <= 1){
total_points++;
}
}
double points = 4.0 * total_points;
double pi = points / desired_amount;
printf("The approximate value of pi for the desired amount of points %d is: %f \n", desired_amount, pi);
return 0;
}