前言:
一般来说,如果安装tensorflow主要目的是为了调试些小程序的话,只要下载相应的包,然后,直接使用pip install tensorflow即可。
但有时我们需要将Tensorflow的功能移植到其它平台,这时就无法直接安装了。需要我们下载相应的Tensorflow源码,自已动手编译了。
正文:
Tensorflow功能代码庞大,结构复杂;如何快速了解编译结构,就显示尤为重要了。
Tensorflow主体结构:
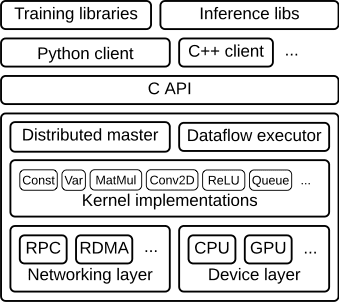
整个框架以C API为界,分为前端和后端两大部分。
前端:提供编译模型,多语言接口支持,如:python,java,c++等。
后端:提供运行环境,完成计算图执行,大致可分为4层:
运行层:分布式运行时和本地运行时,负责计算图的接收,构造,编排等;

计算层:提供各算子的内核实现,例如: conv2d,relu等;
通信层:实现组件间数据通信,基于GRPC,RDMA两种通信方式;
设备层:提供多种异构设备支持,如:CPU,GPU,TPU,FPGA等;
模型构造和执行流程:
Tensorflow图的构造与执行是分开的,用户添加完算子,构建好图后,才开始进行训练和执行。
流程如下:
1、图构建:用户在Client中基于Tensorflow的多语言编程接口,添加算子,完成计算图的构造;
2、 图传递:Client开启Session,通过它建立和Master之间的连接,执行Session.run()时,将构造好的graph序列化为graphdef后,以protobuf格式传递给master。
3、图剪枝:master 根据session.run()传递的fetches和feeds列表,反向遍历全图full graph,实施剪枝,得到最小依赖子图;
未完待续。。。