如何查询硬解析问题:

--捕获出需要使用绑定变量的SQL
drop table t_bind_sql purge;
create table t_bind_sql as select sql_text,module from v$sqlarea;
alter table t_bind_sql add sql_text_wo_constants varchar2(1000);
create or replace function
remove_constants( p_query in varchar2 ) return varchar2
as
l_query long;
l_char varchar2(10);
l_in_quotes boolean default FALSE;
begin
for i in 1 .. length( p_query )
loop
l_char := substr(p_query,i,1);
if ( l_char = '''' and l_in_quotes )
then
l_in_quotes := FALSE;
elsif ( l_char = '''' and NOT l_in_quotes )
then
l_in_quotes := TRUE;
l_query := l_query || '''#';
end if;
if ( NOT l_in_quotes ) then
l_query := l_query || l_char;
end if;
end loop;
l_query := translate( l_query, '0123456789', '@@@@@@@@@@' );
for i in 0 .. 8 loop
l_query := replace( l_query, lpad('@',10-i,'@'), '@' );
l_query := replace( l_query, lpad(' ',10-i,' '), ' ' );
end loop;
return upper(l_query);
end;
/
update t_bind_sql set sql_text_wo_constants = remove_constants(sql_text);
commit;
---执行完上述动作后,以下SQL语句可以完成未绑定变量语句的统计
set linesize 266
col sql_text_wo_constants format a30
col module format a30
col CNT format 999999
select sql_text_wo_constants, module,count(*) CNT
from t_bind_sql
group by sql_text_wo_constants,module
having count(*) > 100
order by 3 desc;
--注:可以考虑试验如下脚本
drop table t purge;
create table t(x int);
select * from v$mystat where rownum=1;
begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values ( '||i||')';
end loop;
commit;
end;
/
附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> ---执行完上述动作后,以下SQL语句可以完成未绑定变量语句的统计
SQL> set linesize 266
SQL> col sql_text_wo_constants format a30
SQL> col module format a30
SQL> col CNT format 999999
SQL> select sql_text_wo_constants, module,count(*) CNT
2 from t_bind_sql
3 group by sql_text_wo_constants,module
4 having count(*) > 100
5 order by 3 desc;
SQL_TEXT_WO_CONSTANTS MODULE CNT
------------------------------ ------------------------------ -------
INSERT INTO T VALUES ( @) SQL*Plus 7366
绑定变量的不适合场景:
---1.构建T表,数据,及主键
VARIABLE id NUMBER
COLUMN sql_id NEW_VALUE sql_id
DROP TABLE t;
CREATE TABLE t
AS
SELECT rownum AS id, rpad('*',100,'*') AS pad
FROM dual
CONNECT BY level <= 1000;
ALTER TABLE t ADD CONSTRAINT t_pk PRIMARY KEY (id);
---2.收集统计信息
BEGIN
dbms_stats.gather_table_stats(
ownname => user,
tabname => 't',
estimate_percent => 100,
method_opt => 'for all columns size skewonly'
);
END;
/
---3.查询T表当前的分布情况
SELECT count(id), count(DISTINCT id), min(id), max(id) FROM t;
---4.发现当前情况下,可以区分出数据分布情况而正确使用执行计划
set linesize 1000
set autotrace traceonly explain
SELECT count(pad) FROM t WHERE id < 990;
SELECT count(pad) FROM t WHERE id < 10;
---5.现在将id的值该为变量实验一下绑定变量的SQL是否能使用直方图
--首先代入990,发现执行计划是走全表扫描,很正确
EXECUTE :id := 990;
SELECT count(pad) FROM t WHERE id < :id;
---6.接着代入10,发现仍然走全表扫描
EXECUTE :id := 10;
SELECT count(pad) FROM t WHERE id < :id;
---7.把共享池清空,很重要的一步,保证硬解析
ALTER SYSTEM FLUSH SHARED_POOL;
---8.代入10,发现可以使用直方图,执行计划为索引读,很正常
EXECUTE :id := 10;
SELECT count(pad) FROM t WHERE id < :id;
---9.代入990后,发现异常,仍然走索引读,这个时候由于返回大部分数据,应该全表扫描才对。
EXECUTE :id := 990;
SELECT count(pad) FROM t WHERE id < :id;
---明白了,这个就是传说中的绑定变量窥视!
附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> SELECT count(pad) FROM t WHERE id < 990;
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 7 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
|* 2 | TABLE ACCESS FULL| T | 990 | 101K| 7 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> SELECT count(pad) FROM t WHERE id < 10;
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 9 | 945 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_PK | 9 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
SQL> EXECUTE :id := 990;
PL/SQL 过程已成功完成。
SQL> SELECT count(pad) FROM t WHERE id < :id;
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 50 | 5250 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_PK | 9 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
SQL> EXECUTE :id := 10;
SQL> SELECT count(pad) FROM t WHERE id < :id;
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 50 | 5250 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_PK | 9 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------

sql的逻辑读变零:
drop table t purge;
create table t as select * from dba_objects;
insert into t select * from t;
commit;
set autotrace on
set timing on
set linesize 1000
select /*+ result_cache */ count(*) from t;
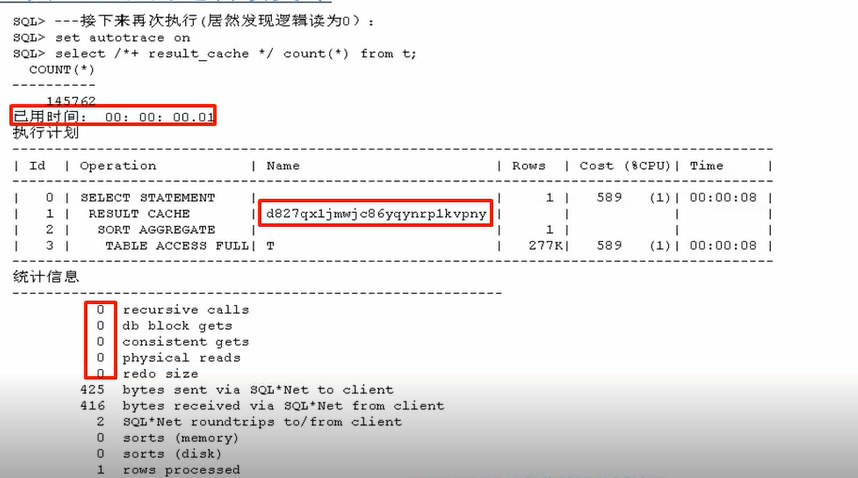
---接下来再次执行(居然发现逻辑读为0):
set autotrace on
select /*+ result_cache */ count(*) from t;
附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> ---接下来再次执行(居然发现逻辑读为0):
SQL> set autotrace on
SQL> select /*+ result_cache */ count(*) from t;
COUNT(*)
----------
145762
已用时间: 00: 00: 00.01
执行计划
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 589 (1)| 00:00:08 |
| 1 | RESULT CACHE | d827qx1jmwjc86yqynrp1kvpny | | | |
| 2 | SORT AGGREGATE | | 1 | | |
| 3 | TABLE ACCESS FULL| T | 277K| 589 (1)| 00:00:08 |
------------------------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
425 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
函数的逻辑读变成零:
drop table t;
CREATE TABLE T AS SELECT * FROM DBA_OBJECTS;
CREATE OR REPLACE FUNCTION F_NO_RESULT_CACHE RETURN NUMBER AS
V_RETURN NUMBER;
BEGIN
SELECT COUNT(*) INTO V_RETURN FROM T;
RETURN V_RETURN;
END;
/
set autotrace on statistics
SELECT F_NO_RESULT_CACHE FROM DUAL;
--看调用F_NO_RESULT_CACHE执行第2次后的结果
SELECT F_NO_RESULT_CACHE FROM DUAL;
CREATE OR REPLACE FUNCTION F_RESULT_CACHE RETURN NUMBER RESULT_CACHE AS
V_RETURN NUMBER;
BEGIN
SELECT COUNT(*) INTO V_RETURN FROM T;
RETURN V_RETURN;
END;
/
SELECT F_RESULT_CACHE FROM DUAL;
--看调用F_RESULT_CACHE执行第2次后的结果
SELECT F_RESULT_CACHE FROM DUAL;
--以下细节是探讨关于如何保证在数据变化后,结果的正确性
SELECT COUNT(*) FROM T;
SELECT F_RESULT_CACHE(1) FROM DUAL;
DELETE T WHERE ROWNUM = 1;
SELECT COUNT(*) FROM T;
SELECT F_RESULT_CACHE(1) FROM DUAL;
COMMIT;
SELECT F_RESULT_CACHE(1) FROM DUAL;
EXEC DBMS_RESULT_CACHE.FLUSH
CREATE OR REPLACE FUNCTION F_RESULT_CACHE(P_IN NUMBER)
RETURN NUMBER RESULT_CACHE RELIES_ON (T) AS
V_RETURN NUMBER;
BEGIN
SELECT COUNT(*) INTO V_RETURN FROM T;
RETURN V_RETURN;
END;
/
SELECT COUNT(*) FROM T;
SELECT F_RESULT_CACHE(1) FROM DUAL;
SELECT F_RESULT_CACHE(1) FROM DUAL;
DELETE T WHERE ROWNUM = 1;
SELECT COUNT(*) FROM T;
SELECT F_RESULT_CACHE(1) FROM DUAL;
---添加了RELIES_ON语句后,Oracle会根据依赖对象自动INVALIDATE结果集,从而保证RESULT CACHE的正确性。
附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> --看调用F_NO_RESULT_CACHE执行第2次后的结果
SQL> SELECT F_NO_RESULT_CACHE FROM DUAL;
F_NO_RESULT_CACHE
-----------------
72883
统计信息
---------------------------------------------------
1 recursive calls
0 db block gets
1043 consistent gets
0 physical reads
0 redo size
434 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> --看调用F_RESULT_CACHE执行第2次后的结果
SQL> SELECT F_RESULT_CACHE FROM DUAL;
F_RESULT_CACHE
--------------
72883
统计信息
---------------------------------------------------
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
431 bytes sent via SQL*Net to client
415 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed

keep让sql跑的更快:
--前提:必须保证db_keep_cache_size值不为0,所以首先有如下操作: --设置100M这么大。 alter system set db_keep_cache_size=100M; drop table t; create table t as select * from dba_objects; create index idx_object_id on t(object_id); --未执行KEEP命令,通过如下查询出BUFFER_POOL列值为DEFAULT,表示未KEEP。 select BUFFER_POOL from user_tables where TABLE_NAME='T'; select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID'; alter index idx_object_id storage(buffer_pool keep); --以下将索引全部读进内存 select /*+index(t,idx_object_id)*/ count(*) from t where object_id is not null; --以下将数据全部读进内存 alter table t storage(buffer_pool keep); select /*+full(t)*/ count(*) from t; --执行KEEP操作后,通过如下查询出BUFFER_POOL列值为KEEP,表示已经KEEP成功了 select BUFFER_POOL from user_tables where TABLE_NAME='T'; select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID'; 附:贴出部分执行结果 ------------------------------------------------------------------------------------------------------ --未执行KEEP命令,通过如下查询出BUFFER_POOL列值为DEFAULT,表示未KEEP。 select BUFFER_POOL from user_tables where TABLE_NAME='T'; BUFFER_POOL ------------------- DEFAULT select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID'; BUFFER_POOL ------------------- DEFAULT --执行KEEP操作后,通过如下查询出BUFFER_POOL列值为KEEP,表示已经KEEP成功了 select BUFFER_POOL from user_tables where TABLE_NAME='T'; BUFFER_POOL ------------------- KEEP select BUFFER_POOL from user_indexes where INDEX_NAME='IDX_OBJECT_ID'; BUFFER_POOL ------------------- KEEP

查看系统各维度规律:
select s.snap_date,
decode(s.redosize, null, '--shutdown or end--', s.currtime) "TIME",
to_char(round(s.seconds/60,2)) "elapse(min)",
round(t.db_time / 1000000 / 60, 2) "DB time(min)",
s.redosize redo,
round(s.redosize / s.seconds, 2) "redo/s",
s.logicalreads logical,
round(s.logicalreads / s.seconds, 2) "logical/s",
physicalreads physical,
round(s.physicalreads / s.seconds, 2) "phy/s",
s.executes execs,
round(s.executes / s.seconds, 2) "execs/s",
s.parse,
round(s.parse / s.seconds, 2) "parse/s",
s.hardparse,
round(s.hardparse / s.seconds, 2) "hardparse/s",
s.transactions trans,
round(s.transactions / s.seconds, 2) "trans/s"
from (select curr_redo - last_redo redosize,
curr_logicalreads - last_logicalreads logicalreads,
curr_physicalreads - last_physicalreads physicalreads,
curr_executes - last_executes executes,
curr_parse - last_parse parse,
curr_hardparse - last_hardparse hardparse,
curr_transactions - last_transactions transactions,
round(((currtime + 0) - (lasttime + 0)) * 3600 * 24, 0) seconds,
to_char(currtime, 'yy/mm/dd') snap_date,
to_char(currtime, 'hh24:mi') currtime,
currsnap_id endsnap_id,
to_char(startup_time, 'yyyy-mm-dd hh24:mi:ss') startup_time
from (select a.redo last_redo,
a.logicalreads last_logicalreads,
a.physicalreads last_physicalreads,
a.executes last_executes,
a.parse last_parse,
a.hardparse last_hardparse,
a.transactions last_transactions,
lead(a.redo, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_redo,
lead(a.logicalreads, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_logicalreads,
lead(a.physicalreads, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_physicalreads,
lead(a.executes, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_executes,
lead(a.parse, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_parse,
lead(a.hardparse, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_hardparse,
lead(a.transactions, 1, null) over(partition by b.startup_time order by b.end_interval_time) curr_transactions,
b.end_interval_time lasttime,
lead(b.end_interval_time, 1, null) over(partition by b.startup_time order by b.end_interval_time) currtime,
lead(b.snap_id, 1, null) over(partition by b.startup_time order by b.end_interval_time) currsnap_id,
b.startup_time
from (select snap_id,
dbid,
instance_number,
sum(decode(stat_name, 'redo size', value, 0)) redo,
sum(decode(stat_name,
'session logical reads',
value,
0)) logicalreads,
sum(decode(stat_name,
'physical reads',
value,
0)) physicalreads,
sum(decode(stat_name, 'execute count', value, 0)) executes,
sum(decode(stat_name,
'parse count (total)',
value,
0)) parse,
sum(decode(stat_name,
'parse count (hard)',
value,
0)) hardparse,
sum(decode(stat_name,
'user rollbacks',
value,
'user commits',
value,
0)) transactions
from dba_hist_sysstat
where stat_name in
('redo size',
'session logical reads',
'physical reads',
'execute count',
'user rollbacks',
'user commits',
'parse count (hard)',
'parse count (total)')
group by snap_id, dbid, instance_number) a,
dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.dbid = b.dbid
and a.instance_number = b.instance_number
order by end_interval_time)) s,
(select lead(a.value, 1, null) over(partition by b.startup_time order by b.end_interval_time) - a.value db_time,
lead(b.snap_id, 1, null) over(partition by b.startup_time order by b.end_interval_time) endsnap_id
from dba_hist_sys_time_model a, dba_hist_snapshot b
where a.snap_id = b.snap_id
and a.dbid = b.dbid
and a.instance_number = b.instance_number
and a.stat_name = 'DB time') t
where s.endsnap_id = t.endsnap_id
order by s.snap_date ,time desc;
找到提交过频繁的语句:
--检查是否有过分提交的语句(关键是得到sid就好办了,代入V$SESSION就可知道是什么进程,接下来还可以知道V$SQL)
set linesize 1000
column sid format 99999
column program format a20
column machine format a20
column logon_time format date
column wait_class format a10
column event format a32
column sql_id format 9999
column prev_sql_id format 9999
column WAIT_TIME format 9999
column SECONDS_IN_WAIT format 9999
--提交次数最多的SESSION
select t1.sid, t1.value, t2.name
from v$sesstat t1, v$statname t2
where t2.name like '%user commits%'
and t1.STATISTIC# = t2.STATISTIC#
and value >= 10000
order by value desc;
--取得SID既可以代入到V$SESSION 和V$SQL中去分析
--得出SQL_ID
select t.SID,
t.PROGRAM,
t.EVENT,
t.LOGON_TIME,
t.WAIT_TIME,
t.SECONDS_IN_WAIT,
t.SQL_ID,
t.PREV_SQL_ID
from v$session t
where sid in(194) ;
--根据sql_id或prev_sql_id代入得到SQL
select t.sql_id,
t.sql_text,
t.EXECUTIONS,
t.FIRST_LOAD_TIME,
t.LAST_LOAD_TIME
from v$sqlarea t
where sql_id in ('ccpn5c32bmfmf');
--也请关注一下这个:
select * from v$active_session_history where session_id=194
--在别的session先执行如下试验脚本
drop table t purge;
create table t(x int);
select * from v$mystat where rownum=1;
begin
for i in 1 .. 100000 loop
insert into t values (i);
commit;
end loop;
end;
/
附:贴出部分执行结果
------------------------------------------------------------------------------------------------------
SQL> select t1.sid, t1.value, t2.name
2 from v$sesstat t1, v$statname t2
3 where t2.name like '%user commits%'
4 and t1.STATISTIC# = t2.STATISTIC#
5 and value >= 10000
6 order by value desc;
SID VALUE NAME
------ ---------- -------------------------
132 100003 user commits
SQL> select t.SID,
2 t.PROGRAM,
3 t.EVENT,
4 t.LOGON_TIME,
5 t.WAIT_TIME,
6 t.SECONDS_IN_WAIT,
7 t.SQL_ID,
8 t.PREV_SQL_ID
9 from v$session t
10 where sid in(132);
SID PROGRAM EVENT LOGON_TIME WAIT_TIME SECONDS_IN_WAIT SQL_ID PREV_SQL_ID
------ -------------------- ---------------------------------------------------------------------- --------------------------
132 sqlplus.exe SQL*Net message from client 13-11月-13 0 77 ccpn5c32bmfmf
SQL> select t.sql_id,
2 t.sql_text,
3 t.EXECUTIONS,
4 t.FIRST_LOAD_TIME,
5 t.LAST_LOAD_TIME
6 from v$sqlarea t
7 where sql_id in ('ccpn5c32bmfmf');
SQL_ID SQL_TEXT EXECUTIONS FIRST_LOAD_TIME LAST_LOAD_TIME
------------------------------------------------------------------------------------------------------------------------------------
ccpn5c32bmfmfbegin for i in 1 .. 100000 loop 1 2013-11-13/16:13:56 13-11月-13
insert into t values (i);
commit;
end loop;
end;
