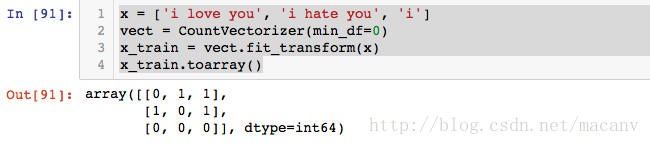
在sklearn中的sklearn.feature_extraction.text.Countvectorizer()或者是sklearn.feature_extraction.text.TfidfVectorizer()中其在进行却分token的时候,会默认把长度<2的字符抛弃,例如下面的例子:
x = ['i love you', 'i hate you', 'i']
vect = CountVectorizer(min_df=0)
x_train = vect.fit_transform(x)
x_train.toarray()- 1
- 2
- 3
- 4
其执行后的编码如下:
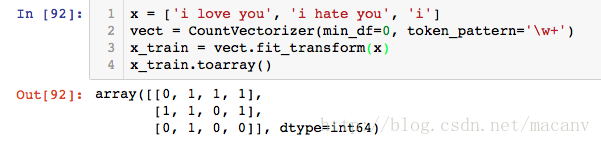
那么如果我们想要保留‘I’这种长度只有1的字符该怎么办呢?具体方法如下:
我么你可以指定最小的df,并且指定切分单词的模式,具体的例子:
x = ['i love you', 'i hate you', 'i']
vect = CountVectorizer(min_df=0, token_pattern='\w+') x_train = vect.fit_transform(x) x_train.toarray()- 1
- 2
- 3
- 4
运行结果: