论文题目:ImageNetClassificationwithDeepConvolutional NeuralNetworks
发表日期:2012年
发表刊物:NIPS
作者:Alex Krizhevsk 等(Alex 是Hinton的学生,Hinton是神经网络领域三巨头:Geoffrey Hinton,Yann LeCun 和 Yoshua Bengio 之一)
1. 背景
第一个典型的CNN是LeNet5网络结构,但第一个引起大家注意的网络是AlexNet,即这篇文章中所介绍的网络。因为这篇的论文第一作者是Alex,所以网络结构称为AlexNet。这篇文章是由2012年的ImageNet竞赛中取得冠军的一个模型整理后发表的。
模型简介:AlexNet有60 million个参数和65 000个神经元,五层卷积,三层全连接(还含有三个池化层)组成的网络,最终的输出层是1000 way 的 softmax。AlexNet利用了两块GPU进行计算,大大提高了运算效率,并且在ILSVRC-2012竞赛中获得了top-5测试的15.3% error rate, 获得第二名的方法error rate 是 26.2%。
2. 数据集介绍
文章中的模型参加的竞赛是ImageNet LSVRC-2010,该ImageNet数据集有1.2 million幅高分辨率图像,总共有1000个类别。测试集分为top-1和top-5,并且分别拿到了37.5%和17%的error rates。
ILSVRC:ImageNet Large Scale Visual Recognition Challenge( ImageNet大规模视觉识别挑战),该数据集是ImageNet数据集中的一部分数据。
ImageNet: 有超过1500万个带有标签的高分辨率图像,大约属于22,000个类别。
top-5 error rates :简单理解就是五个预测的选项中存在真实的标签就将本次预测认为是正确的。
3. Alex网络结构
a. 原文给出的网络结构中的输入图片尺寸为 224 * 224 ,但实际输入网络时,图片被 resize 成了 227 * 227(原因是224进行 卷积核为:11*11,步长为 4 的卷积操作时根据卷积公式不能进行整除 )。
b. 在文章中给出的结构图中只是显示了 5 个卷积层和 3 个全连接层(没有给出在第1、2、5卷积层之后的 3 个池化层),所以其中的参数有些难以理解。
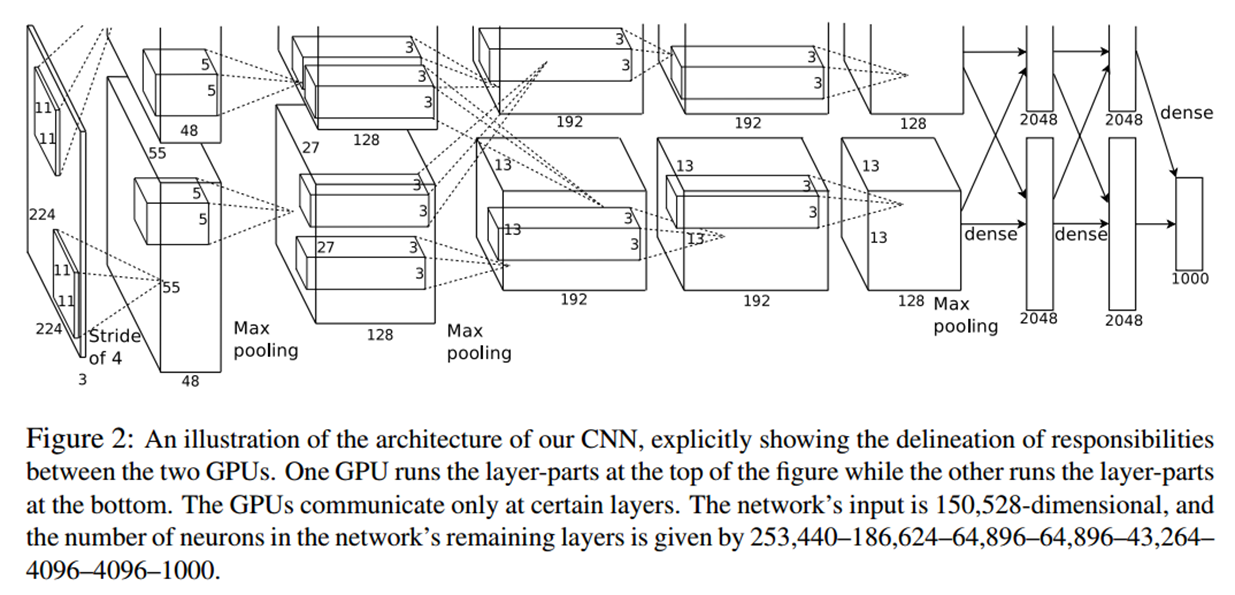
c. 原图分析 -- 1

d. 原图分析 -- 2

e. Alex网络中每层参数详解
注: 卷积公式 output_size = (input_size + 2 * padding – filter_size) / stride + 1;
带有部分重叠池化公式: output_size = (input_size – pool_size) / stride + 1;
输入:224 * 224 * 3 被 resize 成 227 * 227 * 3
Conv1: 11 * 11 * 3 卷积核(96个),步长 4,填充 0。 结果:55 * 55 * 96 ( 其中96 = 48 * 2 ,因为其在两块GPU上进行计算)。
Pool1: 3 * 3 池化,步长为 2 (部分重叠的池化)。 结果:27 * 27 * 96 。
Conv2: 5 * 5 * 48 卷积核 256 个,步长 1,填充 2。 结果:27 * 27 * 256(其中:256 = 128 * 2)。
Pool2: 3 * 3 池化,步长为2(部分重叠的池化)。 结果:13 * 13 * 256 。
Conv3: 3 * 3 * 256 卷积核 384 个,步长1,填充1。 结果:13 * 13 * 384(其中:384 = 192 * 2;卷积核的256 = 128 * 2;在此次卷积操作的时候两块GPU之间进行了信息交互)。
Conv4: 3 * 3 * 192 卷积核 384个,步长1,填充1。 结果:13 * 13 * 384(其中:384 = 192 * 2)。
Conv5: 3 * 3 * 192 卷积核 256 个,步长1,填充1。 结果:13 * 13 * 256。
Pool5: 3 * 3 池化,步长2(部分重叠的池化)。 结果:6 * 6 * 256(其中:6 * 6 * 256 = 9216;Pool5 与 Full6 之间有信息的交互)。
Full6: 4096
Full7: 4096
Full8: 1000
4. 原文详解
a.(3.1) 激活函数:作者用4层的神经网络在CIFAR-10数据集上训练比较了tanh和Relu分别作为激活函数的训练速度,发现要达到25% train error,Relu激活函数花费更少的时间,如下图:
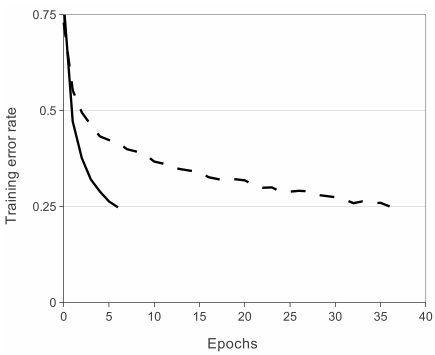
传统的激活函数tanh和sigmoid,作为软饱和的激活函数,一旦落入饱和区,梯度更新会趋向于0,导致梯度消失,变得很难训练。
而ReLU作为一种在负半轴抑制,正半轴是线性的激活函数,这种结构表达了非线性的筛选能力,又能解决梯度消失的问题,是一种比较好的选择
b.(3.2)在两块GPU上进行训练:当时GPU的算力有限,无奈之举。
c.(3.3)本地响应规范化: <还没搞懂,期待后续完善>
d.(3.4)部分重叠的池化 : 步长 < 池化尺寸。
即在池化后的图像上,每个像素点与附近的像素点之间是有信息的重叠的。
作者发现这种Overlapping的Pooling可以增加准确率,top1,top5 error各自降低了0.4%,0.3%个点。
作者认为这种Overlapping的Pooling在训练的时候可以轻微降低Overfitting。
e.(4)减少过拟合的方法:
1)数据增强:
i. 随机裁剪:256*256 的图像裁剪成224*224的图像,图像集扩充了2048倍,其中很多图像是高度依赖的,所以在训练的时候选取了其中的 10 种结果。
2048 = (256-224)*(256-224)* 2
10 = (4角 + 1中心)* 2 reflections
ii. 给图像增加一些随机的光照:对RGB空间做PCA,然后对主成分做一个(0,0.1)的高斯扰动。结果让错误率又下降了1%。
2) dropout:
在训练的时候,所有的神经元都以一定的概率p被置为0,论文中取p=0.5,但是网络的权值都是共享的。
这样,每个bacth送进网络进行训练的时候,相当于每次训练的网络结构都是不太相同的。
最终训练完成之后,进行分类的时候,所有的神经元都不会被置为0,也就是说Dropout只发生在训练阶段。
这样,最后的分类结果其实就相当于集成了多个不同的网络(集成学习的思想),效果自然会得到提升,泛化能力也强,在一定程度上可以减轻过拟合。
f.(5)学习的细节: <还没搞懂,期待后续完善>
g.(6)实验结果:
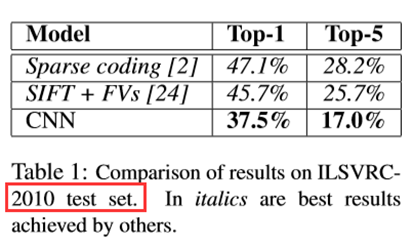
1) 表1总结了作者团队在 ILSVRC-2010 上的实验结果。实现了top-1和top-5测试集错误率分别为37.5%和17.0%。
在ILSVRC2010竞赛中获得的最佳性能分别为47.1%和28.2%,其方法是对根据不同特征训练的六个稀疏编码模型产生的预测进行平均,此后,最佳的结果分别为45.7%和25.7%。
2) 文中描述的CNN的top 5 的错误率达到18.2%。五个CNN的平均预测错误率为16.4%。
训练一个CNN,在最后一个池化层上再加上一个第六卷积层,以对整个ImageNet Fall 2011版本(1500万张图像,22K个类别)进行分类,
然后在ILSVRC-2012上对其进行“微调”,得出的错误率为16.6 %。
对使用上述五个CNN在整个2011年秋季版本中进行预训练的两个CNN的平均预测得出的错误率为15.3%。

3) 下图展示了八个ILSVRC-2010测试图像和模型认为最可能的五个标签(top 5)。将正确的标签写在每个图像下,并且用加粗的条显示对应标签预测的概率大小。

4) 下图:5张ILSVRC-2010测试图像在第一栏中。 其余的 6 列显示了 6 个训练图像,这些图像在最后一个隐藏层中生成特征向量,这些特征向量与测试图像的特征向量之间的欧式距离最小。

5. 参考链接:
AlexNet: https://www.jianshu.com/p/73532b63068e
我看AlexNet: https://www.jianshu.com/p/58168fec534d
注:本人为图像处理方面初学者,感谢网络上各位前辈们的无私分享。如有侵权或冒犯之处,请联系本人,我会尽快删除。