5-1 简单线性回归
线性回归算法
- 解决回归问题
- 思想简单,实现容易
- 许多强大的非线性模型的基础
- 结果具有很好的可解释性
- 蕴含机器学习中的很多重要思想
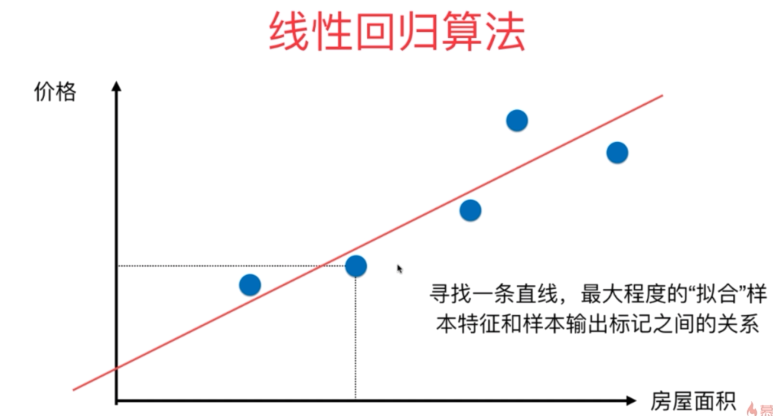
对比分类问题,两轴均为特征。

总结一下

说明

线性回归问题描述

解决思路

近乎所有参数学习算法都是这样的套路


5-2 最小二乘法

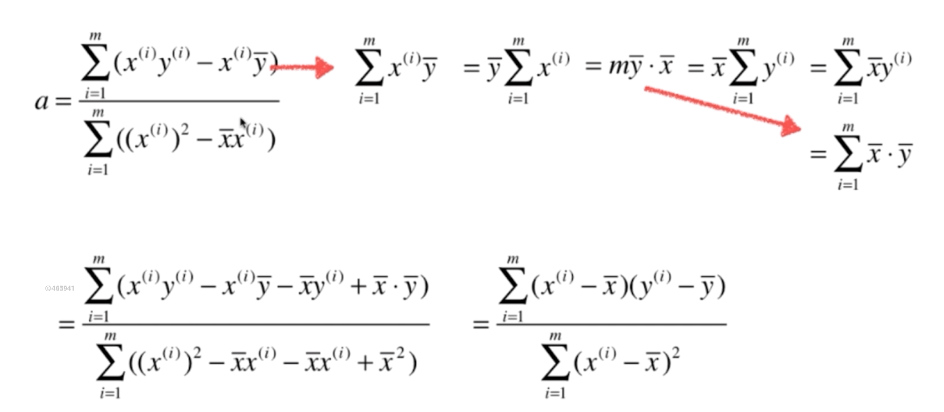
推导,得
(1)对 b 求偏导
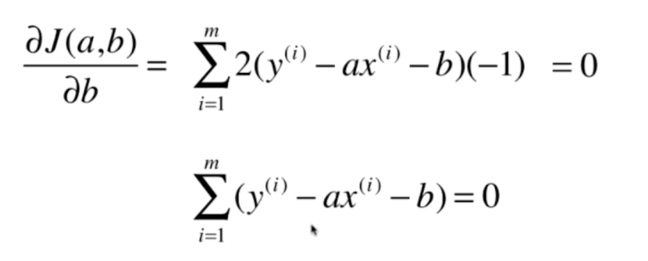
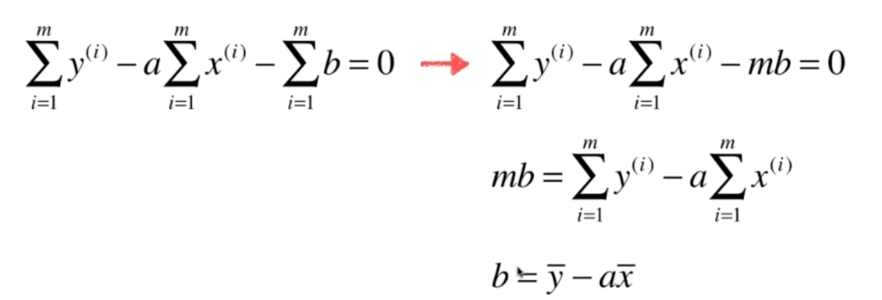
(2)对 a 求偏导
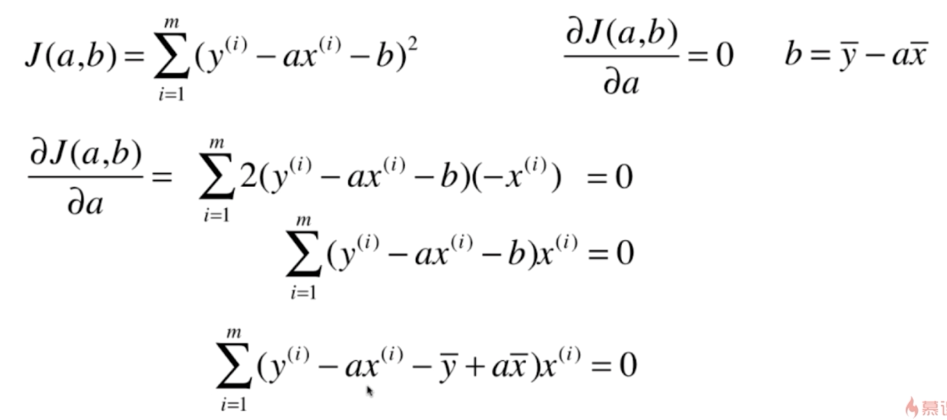
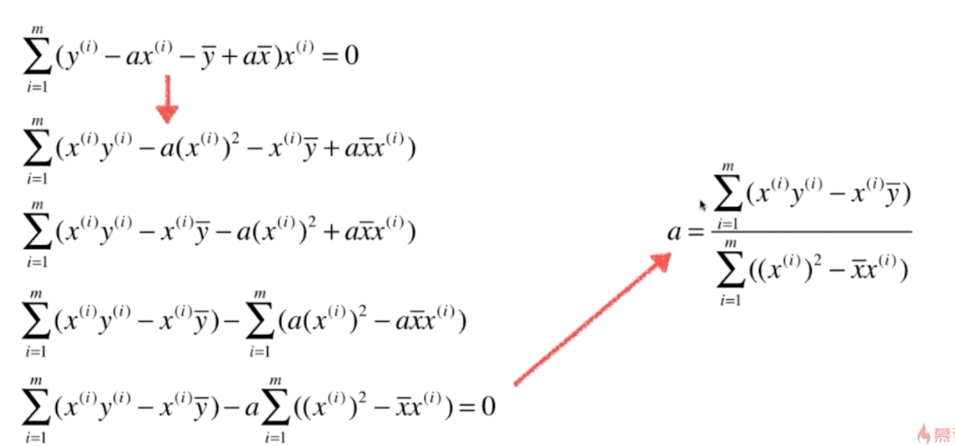

5-3 简单线性回归的实现
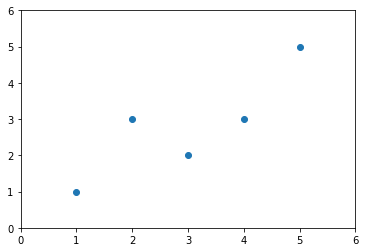
首先,看一个简单的例子
import numpy as np
import matplotlib.pyplot as plt
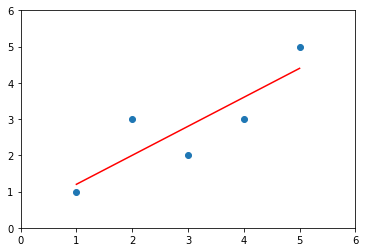
x = np.array([1., 2., 3., 4., 5.])
y = np.array([1., 3., 2., 3., 5.])
plt.scatter(x, y)
plt.axis([0, 6, 0, 6])
plt.show()
接下来计算相关值
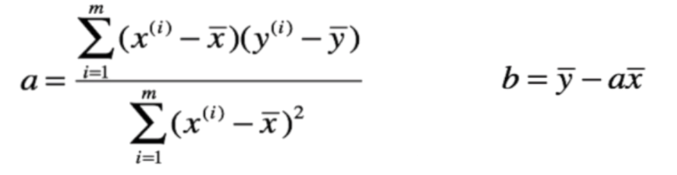
x_mean = np.mean(x)
y_mean = np.mean(y)
num = 0.0
d = 0.0
for x_i, y_i in zip(x, y):
num += (x_i - x_mean) * (y_i - y_mean)
d += (x_i - x_mean) ** 2
a = num/d
b = y_mean - a * x_mean
print("(a, b): ", (a, b)) # (a, b): (0.8, 0.39999999999999947)
y_hat = a * x + b
plt.scatter(x, y)
plt.plot(x, y_hat, color='r')
plt.axis([0, 6, 0, 6])
plt.show()
x_predict = 6
y_predict = a * x_predict + b
y_predict
封装自己的线性回归
# playML\SimpleLinearRegression.py
import numpy as np
class SimpleLinearRegression1:
def __init__(self):
"""初始化Simple Linear Regression 模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x, y in zip(x_train, y_train):
num += (x - x_mean) * (y - y_mean)
d += (x - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x,返回x的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression1()"
调用自己定义的简单线性回归
from playML.SimpleLinearRegression import SimpleLinearRegression1
reg1 = SimpleLinearRegression1()
reg1.fit(x, y)
print(reg1.predict(np.array([x_predict])))
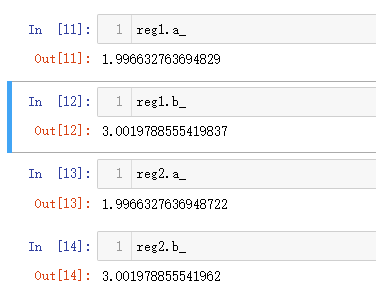
print("(a, b): ", (reg1.a_, reg1.b_))
# [5.2]
# (a, b): (0.8, 0.39999999999999947)绘图
y_hat1 = reg1.predict(x)
plt.scatter(x, y)
plt.plot(x, y_hat1, color='r')
plt.axis([0, 6, 0, 6])
plt.show()5-4 向量化
前面用for的形式来实现,性能低效。
考虑 向量

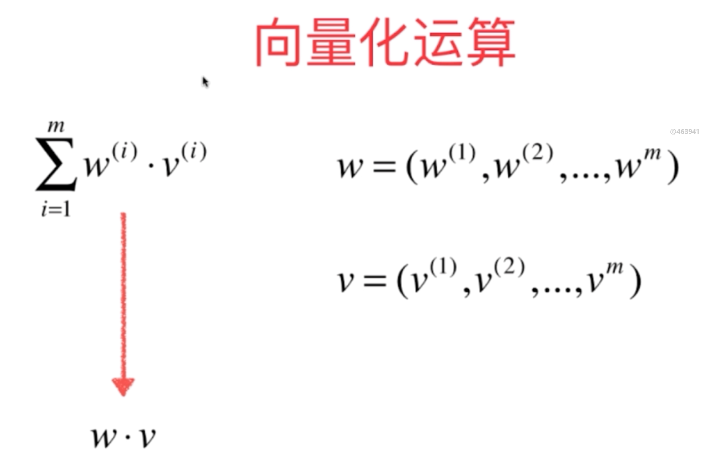
改良前面的算法。 主要改变 fit() 方法。
添加以下类。
# playML.SimpleLinearRegression.py
class SimpleLinearRegression2:
def __init__(self):
"""初始化Simple Linear Regression模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
self.a_ = (x_train - x_mean).dot(y_train - y_mean) / (x_train - x_mean).dot(x_train - x_mean)
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x_single,返回x_single的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression2()"
调用该类
from playML.SimpleLinearRegression import SimpleLinearRegression2
reg2 = SimpleLinearRegression2()
reg2.fit(x, y)
print("(a, b): ", (reg1.a_, reg1.b_))
# (a, b): (0.8, 0.39999999999999947)画图
y_hat2 = reg2.predict(x)
plt.scatter(x, y)
plt.plot(x, y_hat2, color='r')
plt.axis([0, 6, 0, 6])
plt.show()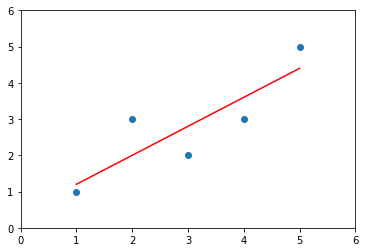
向量化实现的性能测试
m = 1000000
big_x = np.random.random(size=m)
big_y = big_x * 2 + 3 + np.random.normal(size=m)
%timeit reg1.fit(big_x, big_y)
%timeit reg2.fit(big_x, big_y)
# 1.48 s ± 35.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# 22.9 ms ± 1.57 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)