协程
协程,又称微线程,纤程。英文名Coroutine。
进程和线程的运行都是抢占式的
协程是协作式的(非抢占式),程序的运行先后顺序我们可以完全控制
协程本质上就只有一个线程,主要解决IO操作
优点:
优点1: 协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
优点2: 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
yield的简单实现
1 import time
2 import queue
3
4 def consumer(name):
5 print("--->ready to eat baozi...")
6 while True:
7 new_baozi = yield
8 print("[%s] is eating baozi %s" % (name,new_baozi)) 9 #time.sleep(1) 10 11 def producer(): 12 13 r = con.__next__() 14 r = con2.__next__() 15 n = 0 16 while 1: 17 time.sleep(1) 18 print("\033[32;1m[producer]\033[0m is making baozi %s and %s" %(n,n+1) ) 19 con.send(n) 20 con2.send(n+1) 21 22 n +=2 23 24 25 if __name__ == '__main__': 26 con = consumer("c1") 27 con2 = consumer("c2") 28 p = producer()
Greenlet
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
1 from greenlet import greenlet
2
3
4 def test1():
5 print(12)
6 gr2.switch()
7 print(34)
8 gr2.switch() 9 10 11 def test2(): 12 print(56) 13 gr1.switch() 14 print(78) 15 16 17 gr1 = greenlet(test1) 18 gr2 = greenlet(test2) 19 gr1.switch()
Gevent
协程: 遇见IO操作会自动切换进行下一个需要cpu的操作
1 import gevent
2
3 import requests,time
4
5
6 start=time.time()
7
8 def f(url):
9 print('GET: %s' % url)
10 resp =requests.get(url) 11 data = resp.text 12 print('%d bytes received from %s.' % (len(data), url)) 13 14 gevent.joinall([ 15 16 gevent.spawn(f, 'https://www.python.org/'), 17 gevent.spawn(f, 'https://www.yahoo.com/'), 18 gevent.spawn(f, 'https://www.baidu.com/'), 19 gevent.spawn(f, 'https://www.sina.com.cn/'), 20 21 ]) 22 23 # f('https://www.python.org/') 24 # 25 # f('https://www.yahoo.com/') 26 # 27 # f('https://baidu.com/') 28 # 29 # f('https://www.sina.com.cn/') 30 31 print("cost time:",time.time()-start)
Python中的上下文管理器(contextlib模块)>
IO模型
事件驱动模型
协程:遇见IO操作会切换,那么什么时候切换回来?如何确定IO操作结束了?
线性编程模式
开始--->代码块A--->代码块B--->代码块C--->代码块D--->......--->结束
每一个代码块里是完成各种各样事情的代码,但编程者知道代码块A,B,C,D...的执行顺序,唯一能够改变这个流程的是数据。输入不同的数据,根据条件语句判断,流程或许就改为A--->C--->E...--->结束。每一次程序运行顺序或许都不同,但它的控制流程是由输入数据和你编写的程序决定的。如果你知道这个程序当前的运行状态(包括输入数据和程序本身),那你就知道接下来甚至一直到结束它的运行流程。
事件驱动模型
开始--->初始化--->等待
与上面传统编程模式不同,事件驱动程序在启动之后,就在那等待,等待什么呢?等待被事件触发。传统编程下也有“等待”的时候,比如在代码块D中,你定义了一个input(),需要用户输入数据。但这与下面的等待不同,传统编程的“等待”,比如input(),你作为程序编写者是知道或者强制用户输入某个东西的,或许是数字,或许是文件名称,如果用户输入错误,你还需要提醒他,并请他重新输入。事件驱动程序的等待则是完全不知道,也不强制用户输入或者干什么。只要某一事件发生,那程序就会做出相应的“反应”。这些事件包括:输入信息、鼠标、敲击键盘上某个键还有系统内部定时器触发。
如果创建一个线程用来检测用户的鼠标点击事件,缺点:
-
CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
-
如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
-
如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
所以利用事件驱动模型解决这个问题,大体思路:
-
有一个事件(消息)队列;
-
鼠标按下时,往这个队列中增加一个点击事件(消息);
-
有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
-
事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;

事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。
用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。
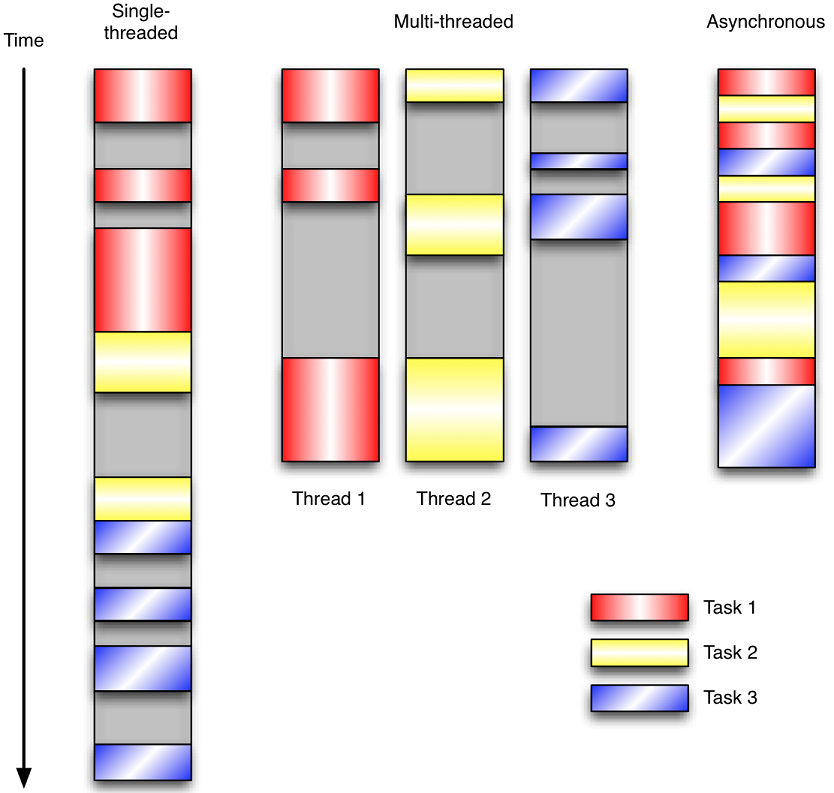
最初的问题:怎么确定IO操作完了切回去呢?通过回调函数 ( 注意,事件驱动的监听事件是由操作系统调用的cpu来完成的)
 事件驱动注解
事件驱动注解
IO模型
文章参考
https://www.cnblogs.com/yuanchenqi/articles/6248025.html
https://www.cnblogs.com/linhaifeng/articles/6817679.html#_label1