转载自:https://blog.csdn.net/metheir/article/details/85080334
1. 为什么filter会快?
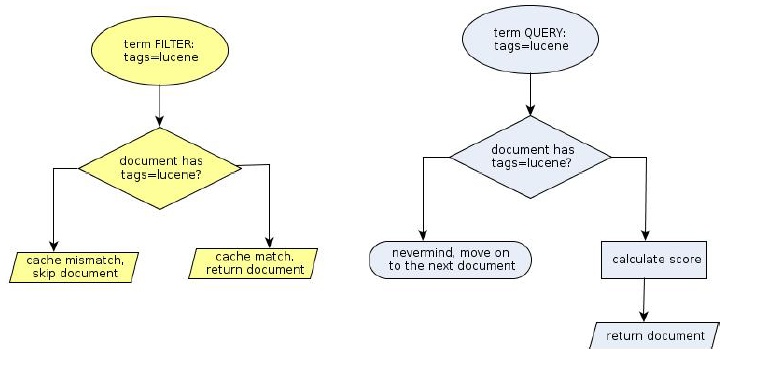
看上面的流程图就能很明显的看到,filter与query还是有很大的区别的。
比如,query的时候,会先比较查询条件,然后计算分值,最后返回文档结果;
而filter则是先判断是否满足查询条件,如果不满足,会缓存查询过程(记录该文档不满足结果);满足的话,就直接缓存结果。
综上所述,filter快在两个方面:
- 1 对结果进行缓存
- 2 避免计算分值
2. bool查询的使用
Bool查询对应Lucene中的BooleanQuery,它由一个或者多个子句组成,每个子句都有特定的类型
must
返回的文档必须满足must子句的条件,并且参与计算分值
filter
返回的文档必须满足filter子句的条件,但是不会像must一样,参与计算分值
should
返回的文档可能满足should子句的条件.在一个bool查询中,如果没有must或者filter,有一个或者多个should子句,那么只要满足一个就可以返回.minimum_should_match参数定义了至少满足几个子句.
must_not
返回的文档必须不满足定义的条件
如果一个查询既有
filter又有should,那么至少包含一个should子句.
bool查询也支持禁用协同计分选项disable_coord.一般计算分值的因素取决于所有的查询条件.
bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值.
3.JavaAPI使用
大专栏
ElasticSearch 中boolQueryBuilder的使用ava">
1 |
|