案例:
相亲约会对象数据,这个样本时男士的数据,三个特征,玩游戏所消耗时间的 百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数。然后有一个 所属类别,被女士评价的三个类别,不喜欢didnt、魅力一般small、极具魅力large 也许也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的 人觉得这三个特征同等重要。
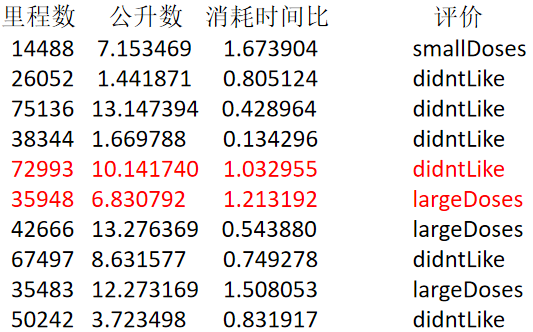
在此处为什么要进行归一化,归一化说白了就是控制数据在指定的范围内,防止过大数据对结果造成干扰。
这里先使用一个算法k-means算法,该算法后面会详细介绍。
k-means就是同一特征下的两个样本,相减取平方。
对于上图标红的两个样本(从现在开始,表中的行称为样本,列称为特征值),使用k-means时,计算(72993-35948)^2 + (10.141740-6.830792)^2 + (1.032955-1.213192)^2,会发现(72993-35948)^2的值过大,后面两项基本可以忽略不计了,但是案例中有一句话很重要------“统计的 人觉得这三个特征同等重要”。所以,就要解决这个情况,可以使用归一化解决。
问题:如果数据中异常点较多,会有什么影响?