文章目录
- 1. 深度学习与 Tensorflow
- 1.1 项目演示
- 1.2 开发环境搭建
- 1.3 深度学习介绍
- 1.4 深度学习框架介绍
- 1.5 神经网络基础
- 1.6 神经网络分类原理
- 1.7 卷积网络简介
- 1.8卷积网络原理
- 学习目标
- 1.8.1 卷积神经网络三个结构
- 1.8.2 卷积层
- 1.8.2.1 卷积核(Filter)的四大要素
- 1.8.2.2 卷积如何计算大小
- 1.8.2.3 卷积如何计算步长
- 1.8.2.4 卷积如何计算卷积核个数
- 1.8.2.5 卷积如何计算零填充大小
- 1.8.2.6 总结-输出大小计算公式
- 1.8.2.7 多通道图片如何观察
- 1.8.2.8 卷积网络 API
- 1.8.2.9 总结
- 1.8.3 激活函数
- 1.8.4 池化层(Polling)
- 1.8.5 全连接层
- 1.8.6 卷积神经网络总结
- 1.8.7 面试题练习
- 1.9 案例:CNNMnist手写数字识别
1. 深度学习与 Tensorflow
1.1 项目演示
学习目标
- 目标:了解项目的演示结果
1.1.1 项目演示
项目已经部署上线,Web端+小程序端演示
1.1.2 项目结构

1.1.3 课程安排
- 第一天
深度学习介绍
TensorFlow
神经网络
卷积网络
手写数字识别案例 - 第二天:算法模型
RCNN以及相关算法
YOLO与SSD
算法接口介绍 - 第三天:数据集处理
数据集标记格式
数据集存储与读取 - 第四天:项目实现
训练、设备部署逻辑实现
测试接口
TensorFlow serving部署模型
Web server+TensorFlow serving Client
小程序
1.2 开发环境搭建
学习目标
- 应用:开发环境搭建
1.2.1 安装
1.2.1.1 虚拟环境安装
1、现在虚拟环境管理工具, 环境隔离(python3版本))
pip3 install virtualenv
2、配置参数
export WORKON_HOME=$HOME/virtualenv source /usr/local/bin/virtualenvwrapper.sh
3、新建虚拟环境
mkvirtualenv + -p /user/bin/python(python版本所在位置) + test(虚拟环境名称)
4、进入虚拟环境
workon test
1.2.1.2 安装环境包
环境包:
pip install -r requirements.txt
requirements.txt文件当中包含所有要安装的库。
TensorFlow版本
关于TensorFlow:
上一种方式当中,TensorFlow默认安装的是非GPU版本(1.8版本),如果要安装GPU版本,参考一下资料中提供的如下文件中的安装过程。
1.3 深度学习介绍
1.3.1 深度学习与机器学习的区别

1.3.1.1 特征提取方面
- 机器学习的特征工程步骤是要靠手动完成的,而且需要大量领域专业知识
- 深度学习通常由多个层组成,它们通常将更简单的模型组合在一起,通过将数据从一层传递到另一层来构建更复杂的模型。通过大量数据的训练自动得到模型,不需要人工设计特征提取环节。
深度学习算法试图从数据中学习高级功能,这是深度学习的一个非常独特的部分。因此,减少了为每个问题开发新特征提取器的任务。适合用在难提取特征的图像、语音、自然语言领域
1.3.1.2 数据量
机器学习需要的执行时间远少于深度学习,深度学习参数往往很庞大,需要通过大量数据的多次优化来训练参数。
当数据量很大时,机器学习的表现就不如深度学习好了。

第一、它们需要大量的训练数据集
第二、是训练深度神经网络需要大量的算力
可能要花费数天、甚至数周的时间,才能使用数百万张图像的数据集训练出一个深度网络。所以以后
- 需要强大对的GPU服务器来进行计算
- 全面管理的分布式训练与预测服务——比如谷歌 TensorFlow 云机器学习平台——可能会解决这些问题,为大家提供成本合理的基于云的 CPU 和 GPU
1.3.1.3 算法代表
- 机器学习:
朴素贝叶斯、决策树、线性回归、KNN等。 - 深度学习:
神经网络(是一个统称),会衍生出各种不同的网络,以解决不同的问题。
1.3.2 深度学习的应用场景
- 图像识别
物体识别
人脸识别
目标检测
场景识别
车型识别
人脸检测跟踪
人脸关键点定位
人脸身份认证 - 自然语言处理技术
机器翻译
文本识别
聊天对话 - 语音技术
语音识别
1.4 深度学习框架介绍
1.4.1 常见深度学习框架对比

| 比较项 | Caffe | Torch | Theano | TensorFlow | MXNet |
|---|---|---|---|---|---|
| 主语言 | C++/cuda | C++/Lua/cuda | Python/c++/cuda | C++/cuda | C++/cuda |
| 从语言 | Python/Matlab | - | - | Python | Python/R/Julia/Go |
| 硬件 | CPU/GPU | CPU/GPU/FPGA | CPU/GPU | CPU/GPU/Mobile | CPU/GPU/Mobile |
| 分布式 | N | N | N | Y(未开源) | Y |
| 速度 | 快 | 快 | 中等 | 中等 | 快 |
| 文档 | 全面 | 全面 | 中等 | 中等 | 全面 |
| 适合模型 | CNN | CNN/RNN | CNN/RNN | CNN/RNN | CNN |
| 操作系统 | 所有系统 | Linux, OSX | 所有系统 | Linux, OSX | 所有系统 |
| 命令式 | N | Y | N | N | Y |
| 声明式 | Y | N | Y | Y | Y |
| 接口 | protobuf | Lua | Python | C++/Python | Python/R/Julia/Go |
| 网络结构 | 分层方法 | 分层方法 | 符号张量图 | 符号张量图 | 无 |
1.4.2TensorFlow的特点

官网:https://www.tensorflow.org/
- 高度灵活(Deep Flexibility)
它不仅是可以用来做神经网络算法研究,也可以用来做普通的机器学习算法,甚至是只要你能够把计算表示成数据流图,都可以用TensorFlow。 - 语言多样(Language Options)
TensorFlow使用C++实现的,然后用Python封装。谷歌号召社区通过SWIG开发更多的语言接口来支持TensorFlow - 设备支持
TensorFlow可以运行在各种硬件上,同时根据计算的需要,合理将运算分配到相应的设备,比如卷积就分配到GPU上,也允许在 CPU 和 GPU 上的计算分布,甚至支持使用 gRPC 进行水平扩展。 - Tensorboard可视化
TensorBoard是TensorFlow的一组Web应用,用来监控TensorFlow运行过程,或可视化Computation Graph。TensorBoard目前支持5种可视化:标量(scalars)、图片(images)、音频(audio)、直方图(histograms)和计算图(Computation Graph)。TensorBoard的Events Dashboard可以用来持续地监控运行时的关键指标,比如loss、学习速率(learning rate)或是验证集上的准确率(accuracy)
1.4.3 TensorFlow的安装
1.4.3.1 CPU版本
安装较慢,指定镜像源,请在带有numpy等库的虚拟环境中安装
- ubuntu安装
pip install tensorflow==1.8 -i https://mirrors.aliyun.com/pypi/simple - MacOS安装
pip install tensorflow==1.8 -i https://mirrors.aliyun.com/pypi/simple
1.4.3.2 GPU版本
在 Ubuntu 上安装 TensorFlow
在 masOS 上安装 TensorFlow
1.5 神经网络基础
学习目标
- 目标
了解感知机结构、作用以及优缺点
了解tensorflow playground的使用
说明感知机与神经网络的联系
说明神经网络的组成
1.5.1 神经网络
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN)。是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)结构和功能的 计算模型。经典的神经网络结构包含三个层次的神经网络。分别输入层,输出层以及隐藏层。

其中每层的圆圈代表一个神经元,隐藏层和输出层的神经元有输入的数据计算后输出,输入层的神经元只是输入。
- 神经网络的特点
每个连接都有个权值
同一层神经元之间没有连接
最后的输出结果对应的层也称之为全连接层
神经网络是深度学习的重要算法,用途在图像(如图像的分类、检测)和自然语言处理(如文本分类、聊天等)
那么为什么设计这样的结构呢?首先从一个最基础的结构说起,神经元。以前也称之为感知机。神经元就是要模拟人的神经元结构。

一个神经元通常具有多个树突,主要用来接受传入信息;而轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。
1.5.2 感知机(PLA: Perceptron Learning Algorithm)
感知机就是模拟这样的大脑神经网络处理数据的过程。感知机模型如下图:

每个连接都有各自的权重,权重代表了影响因素的重要性程度。
权重是由网络训练得到的。
- 如果做房价预测(连续值):权重、输入、偏置
- 如果做房子好坏预测(离散值):权重、输入、偏置、激活函数
做分类时需要使用激活函数
感知机是一种最基础的分类模型,类似于逻辑回归。感知机最基础是这样的函数,而逻辑回归用的 sigmoid。这个感知机具有连接的权重和偏置。

我们通过一个平台去演示,就是tensorflow playground。
1.5.3 playground 的使用

网址:http://playground.tensorflow.org/
那么在这整个分类过程当中,是怎么做到这样的效果那要受益于神经网络的一些特点。

要区分一个数据点是橙色的还是蓝色的,你该如何编写代码?也许你会像下面一样任意画一条对角线来分隔两组数据点,定义一个阈值以确定每个数据点属于哪一个组。
其中 b 是确定线的位置的阈值。通过分别为 x1 和 x2 赋予权重 w1 和 w2,你可以使你的代码的复用性更强。

此外,如果你调整 w1 和 w2 的值,你可以按你喜欢的方式调整线的角度。你也可以调整 b 的值来移动线的位置。所以你可以重复使用这个条件来分类任何可以被一条直线分类的数据集。但问题的关键是程序员必须为 w1、w2 和 b 找到合适的值——即所谓的参数值,然后指示计算机如何分类这些数据点。
1.5.3.1 playground 简单两类分类结果

但是这种结构的线性的二分类器,不能对非线性的数据并不能进行有效的分类。
一个感知机可以进行简单数据的分类,对于描述复杂数据的分布状态需要多个感知机。
而神经网络就是由多个感知机组成的
感知机结构,能够很好去解决与、或等问题,但是并不能很好的解决异或等问题。我们通过一张图来看,有四个样本数据:
与问题:每个样本的两个特征同时为1,结果为1
或问题:每个样本的两个特征一个为1,结果为1
异或:每个样本的两个特征相同为0, 不同为1
根据上述的规则来进行划分,我们很容易建立一个线性模型

相当于给出这样的数据


1.5.3.2 单神经元复杂的两类 playground 演示

那么怎么解决这种问题呢?其实我们多增加几个感知机即可解决?也就是下图这样的结构,组成一层的结构?

1.5.3.3 多个神经元效果演示

可以将隐层的每个神经元看作一条直线,那么三个隐层神经元就基本可以将蓝点和红点分开了。
1.6 神经网络分类原理
学习目标
- 目标
说明神经网络的分类原理
说明softmax回归
说明交叉熵损失
神经网络的主要用途在于分类,那么整个神经网络分类的原理是怎么样的?我们还是围绕着损失、优化这两块去说。神经网络输出结果如何分类?
比如一个四分类问题:输出神经元的个数 = 类别个数

神经网络解决多分类问题最常用的方法是设置 n 个输出节点,其中 n 为类别的个数,输出 n 个类别概率,找到最大的概率输出其对应类别。
任意事件发生的概率都在 0 和 1 之间,且总有某一个事件发生(概率的和为 1)。如果将分类问题中“一个样例属于某一个类别”看成一个概率事件,那么训练数据的正确答案就符合一个概率分布。如何将神经网络前向传播得到的结果也变成概率分布呢?Softmax 回归就是一个非常常用的方法。
1.6.1 softmax 回归
神经网络的输出 -> softmax -> 最终的 n 个类别概率值



- softmax特点
如何理解这个公式的作用呢?看一下计算案例
假设输出结果为:2.3, 4.1, 5.6
softmax的计算输出结果为:
y1_p = e^2.3/(e^2.3+e^4.1+e^5.6)
y1_p = e^4.1/(e^2.3+e^4.1+e^5.6)
y1_p = e^5.6/(e^2.3+e^4.1+e^5.6)
这样就把神经网络的输出变成了一个概率输出。

类似于逻辑回归当中的sigmoid函数,sigmoid输出的是某个类别的概率
想一想线性回归的损失函数以及逻辑回归的损失函数,那么如何去衡量神经网络预测的概率分布和真实答案的概率分布之间的距离?
1.6.2 交叉熵损失
1.6.2.1 公式
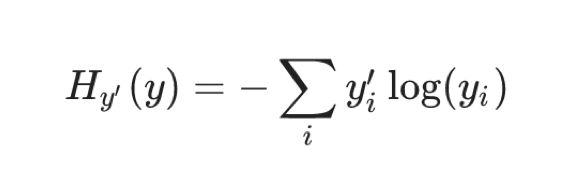
为了能够衡量距离,目标值需要进行 one-hot 编码,能与概率值一一对应,如下图:

训练结果:保存网络中的权重
损失衡量:每个样本的真实值 one_hot 编码与网络输出结果之间进行计算。
它的损失如何计算?
0log(0.10)+0log(0.05)+0log(0.15)+0log(0.10)+0log(0.05)+0log(0.20)+1log(0.10)+0log(0.05)+0log(0.10)+0log(0.10)
上述的结果为1log(0.10),那么为了减少这一个样本的损失。神经网络应该怎么做?所以会提高对应目标值为 1 的位置输出概率大小(输出概率越接近 1,损失越小)。由于 softmax 公式影响,其它的概率必定会减少。只要这样进行调整就预测成功了!
1.6.2.2 损失大小
神经网络最后的损失为平均每个样本的损失大小,对所有样本的损失求和取其平均值,即 avg loss。
1.6.3 网络原理总结
我们不会详细地讨论可以如何使用反向传播和梯度下降等算法训练参数。训练过程中的计算机会尝试一点点增大或减小每个参数,看其能如何减少相比于训练数据集的误差,以望能找到最优的权重、偏置参数组合。


神经网络的训练过程:通过计算样本预测值与真实值之间的损失来优化神经网络的参数。
1.6.4 softmax、交叉熵损失API
tf.nn.softmax_cross_entropy_with_logits(labels=None,logits=None,name=None)
计算logits和labels之间的交叉损失熵
labels:标签值(真实值)
logits:样本加权之后的值
return:返回损失值列表
- tf.reduce_mean(input_tensor)
计算张量的尺寸的元素平均值
1.6.5 总结
- tf.nn.softmax_cross_entropy_with_logits进行 softmax、交叉熵损失计算
- tf.reduce_mean 计算平均值
1.7 卷积网络简介
学习目标
- 目标:了解卷积神经网络的历史
随着人工智能需求的提升,我们想要做复杂的图像识别,做自然语言处理,做语义分析翻译,等等。多层神经网络显然力不从心。
1.7.1 卷积神经网络与传统多层神经网络对比
- 传统意义上的多层神经网络是只有输入层、隐藏层、输出层。其中隐藏层的层数根据需要而定,没有明确的理论推导来说明到底多少层合适
- 卷积神经网络CNN,在原来多层神经网络的基础上,加入了更加有效的特征学习部分,具体操作就是在原来的全连接的层前面加入了部分连接的卷积层与池化层。卷积神经网络出现,使得神经网络层数得以加深,深度学习才能实现。
通常所说的深度学习,一般指的是这些 CNN 等新的结构以及一些新的方法(比如新的激活函数 Relu 等),解决了传统多层神经网络的一些难以解决的问题。
也就是说,卷积神经网络在普通神经网络之上,提出了将隐层变成卷积层、池化层和激活层。
1.7.2 卷积神经网络发展历史
LeNet:手写数字识别

- 网络结构加深
- 加强卷积功能
- 从分类到检测
- 新增功能模块
1.7.3 卷积网络ImageNet比赛错误率
ImageNet 从 Caltech101(2004 年一个专注于图像分类的数据集,也是李飞飞开创的)。ImageNet 不但是计算机视觉发展的重要推动者,也是这一波深度学习热潮的关键驱动力之一。
截至 2016 年,mageNet 中含有超过 1500 万由人手工注释的图片网址,也就是带标签的图片,标签说明了图片中的内容,超过 2.2 万个类别。
AlexNet 由于网络结构的改变,实现了突破。
ResNet 比人识别的准确率还高(人由于模糊可能看不清)。

1.8卷积网络原理
学习目标
- 目标
说明卷积神经网络的三个结构
说明卷积层的卷积核个数、大小、步长以及零填充参数作用
说明激活函数种类以及在神经网络中的作用
说明池化层的大小、步长参数的作用
记忆卷积、池化层的输出大小以及零填充计算公式
说明全连接层在卷机网络中的作用
卷积网络结构什么样?
- 结构:卷积 + 池化 + FC(做分类,输出类别的个数)

1.8.1 卷积神经网络三个结构
神经网络(neural networks)的基本组成包括输入层、隐藏层、输出层。而卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)以及激活层。每一层的作用:
- 卷积层:通过在原始图像上平移来提取特征
- 激活层:增加非线性分割能力
- 池化层:通过特征后稀疏参数来减少学习的参数,降低网络的复杂度,(最大池化和平均池化)
为了能够达到分类效果,还会有一个全连接层(FC)也就是最后的输出层,进行损失计算分类。
1.8.2 卷积层
卷积层(Convolutional layer),卷积神经网络中每层卷积层由若干卷积单元(卷积核)组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。
卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和棱角等,更深层的网络能从低级特征中迭代提取更复杂的特征。
1.8.2.1 卷积核(Filter)的四大要素
- 卷积核个数
- 卷积核大小
- 卷积核步长
- 卷积核零填充大小
接下来通过计算案例讲解,假设图片是黑白图片(只有一个通道),一张像素值表。
1.8.2.2 卷积如何计算大小
卷积核我们可以理解为一个观察的人,带着若干权重和一个偏置去观察,进行特征加权运算。

注:上述要加上偏置
推荐卷积核大小:1 * 1、3 * 3、5 * 5
通常卷积核大小选择这些大小,是经过研究人员证明比较好的效果。这个人观察之后会得到一个运算结果,
那么这个人想观察所有这张图的像素怎么办?那就需要这样:
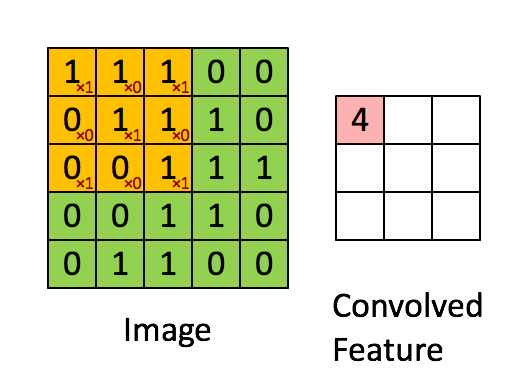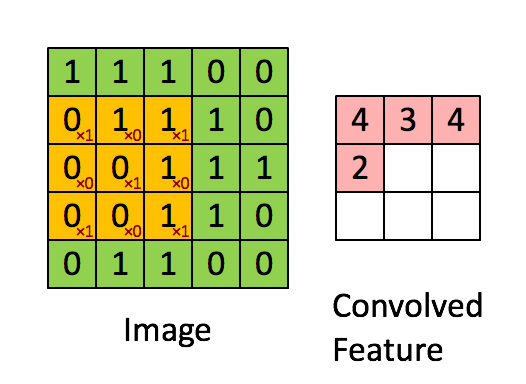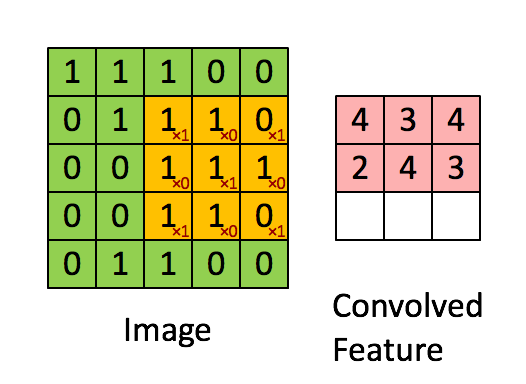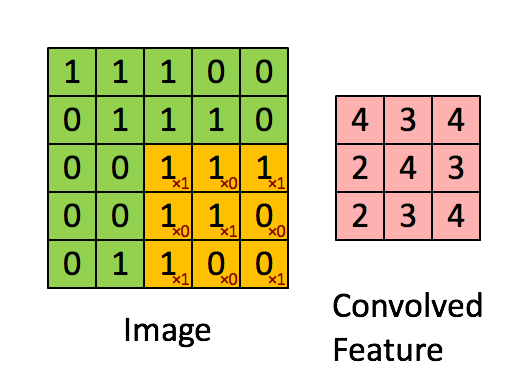
1.8.2.3 卷积如何计算步长
需要去移动卷积核观察这张图片,需要的参数就是步长。
假设移动的步长为一个像素,那么最终这个人观察的结果以下图为例:
5x5的图片,3x3的卷积大小去一个步长运算得到3x3的大小观察结果

如果移动的步长为2那么结果是这样:
5x5的图片,3x3的卷积大小去两个步长运算得到2x2的大小观察结果

1.8.2.4 卷积如何计算卷积核个数
那么如果在某一层结构当中,不止是一个人观察,多个人(卷积核)一起去观察。那就得到多张观察结果。
不同的卷积核带的权重和偏置都不一样,即随机初始化的参数
我们已经得出输出结果的大小有大小和步长决定的,但是只有这些吗,还有一个就是零填充。Filter观察窗口的大小和移动步长会导致超过图片像素宽度!
1.8.2.5 卷积如何计算零填充大小
零填充就是在图片像素外围填充一圈值为0的像素。

1.8.2.6 总结-输出大小计算公式
最终零填充到底填充多少呢?我们并不需要去关注,接下来我们利用已知的这些条件来去求出输出的大小来看结果。
输出结果
- 输出尺寸:(原图尺寸 - 卷积核大小 + 2*填充大小)/ 步长 + 1
- 厚度:卷积核数量

通过一个例子来理解下面的公式:
计算案例:
1、假设已知的条件:输入图像32321, 50个Filter,大小为5*5,移动步长为1,零填充大小为1。请求出输出大小?
H2 = (H1 - F + 2P)/S + 1 = (32 - 5 + 2 * 1)/1 + 1 = 30
W2 = (H1 - F + 2P)/S + 1 = (32 -5 + 2 * 1)/1 + 1 = 30
D2 = K = 50
所以输出大小为[30, 30, 50]2、假设已知的条件:输入图像32321, 50个Filter,大小为33,移动步长为1,未知零填充。输出大小3232?
H2 = (H1 - F + 2P)/S + 1 = (32 - 3 + 2 * P)/1 + 1 = 32
W2 = (H1 - F + 2P)/S + 1 = (32 -3 + 2 * P)/1 + 1 = 32
所以零填充大小为:1*1
1.8.2.7 多通道图片如何观察
如果是一张彩色图片,那么就有三种表分别为R,G,B。原本每个人需要带一个 3x3 或者其他大小的卷积核,现在需要带 3 张 3x3 的权重和一个偏置,总共就27个权重,最终每个人还是得出一张结果。
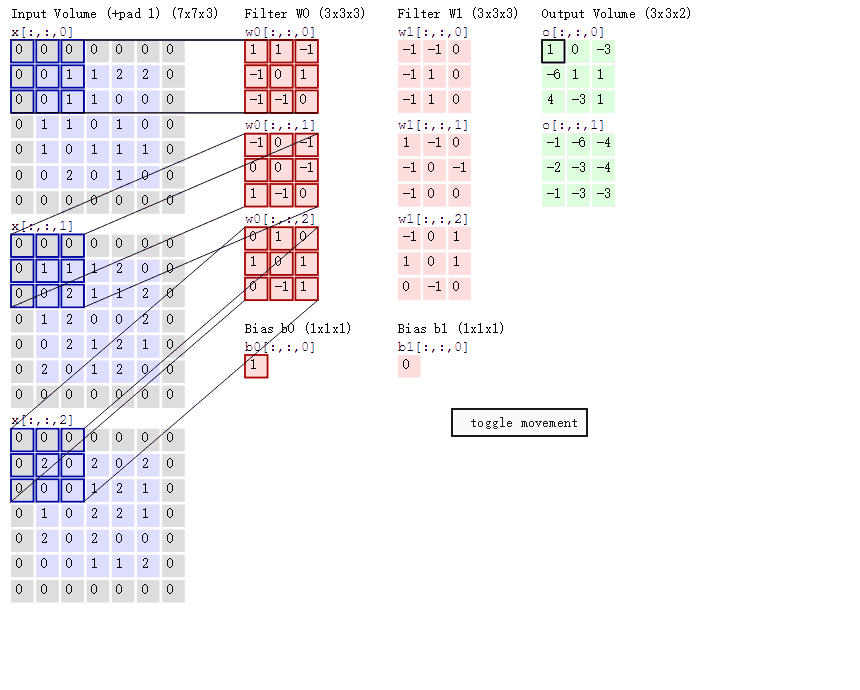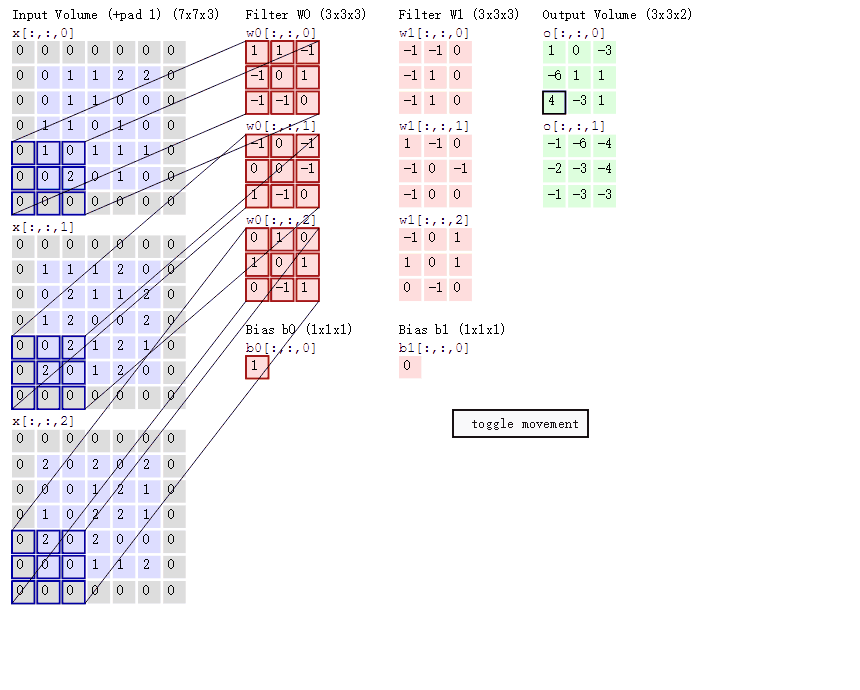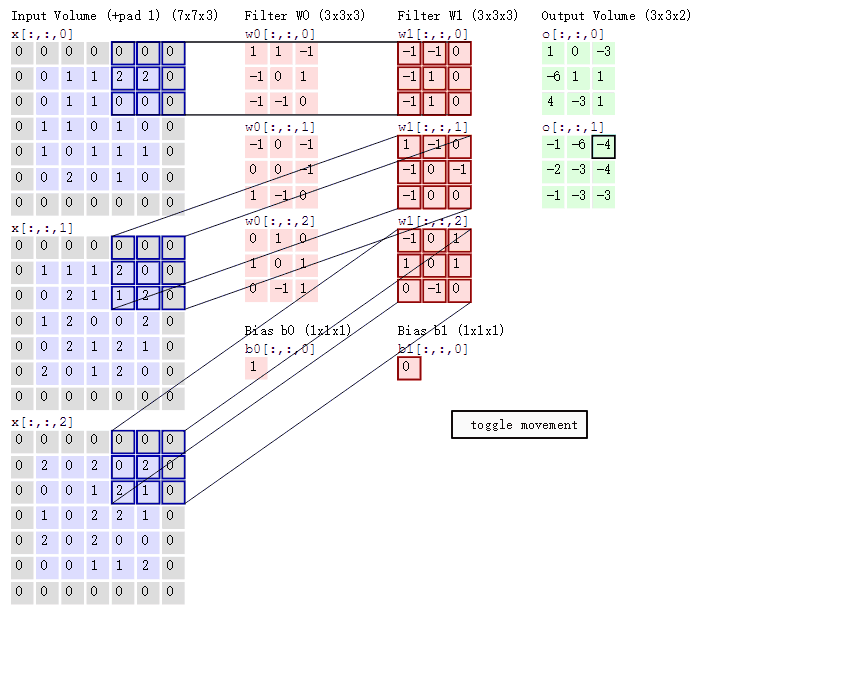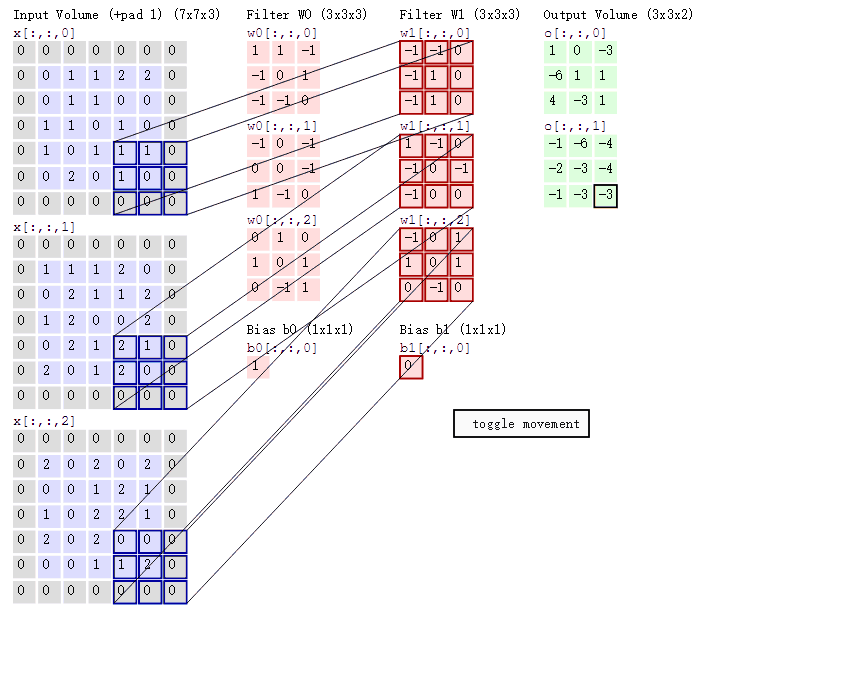
1.8.2.8 卷积网络 API
tf.nn.conv2d(input, filter, strides=, padding=, name=None)
- 计算给定4-D input和filter张量的2维卷积
- input:给定的输入张量,具有[batch,heigth,width,channel],类型为float32,64
- filter:指定过滤器的权重数量,[filter_height, filter_width, in_channels, out_channels]
- strides:strides = [1, stride, stride, 1],步长
- padding:“SAME”, “VALID”,具体解释见下面。
Tensorflow的零填充方式有两种方式,SAME 和 VALID
- SAME:越过边缘取样,取样的面积和输入图像的像素宽度一致。公式 :
- H 为输入的图片的高或者宽,S为步长。
- 无论过滤器的大小是多少,零填充的数量由API自动计算。
- VALID:不越过边缘取样,取样的面积小于输入人的图像的像素宽度。不填充。
在Tensorflow当中,卷积API设置”SAME”之后,如果步长为1,输出高宽与输入大小一样(重要)
1.8.2.9 总结
1、已知固定输出大小,反过来求出零填充,已知零填充,根据步长等信息,求出输出大小。
2、卷积层过滤器(卷积核)大小,三个选择1x1,3x3,5x5,步长一般都为1,过滤器个数不定,不同结构选择不同。
3、每个过滤器会带有若干权重和 1 个偏置
1.8.3 激活函数
目的:达到更好的非线性分割的效果
卷积网络结构采用激活函数,自从网络得到发展之后。大家发现原有的 sigmoid 这些激活函数并不能达到好的效果,所以采取新的激活函数。
1.8.3.1 Relu
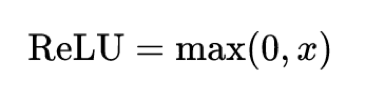

效果是什么样的呢?

1.8.3.2 playground演示不同激活函数作用
网址:http://playground.tensorflow.org/
- Relu
- Tanh
- sigmoid
1.8.3.3 为什么采取的新的激活函数
- Relu 优点
– 有效解决梯度爆炸问题
– 计算速度非常快,只需要判断输入是否大于0。SGD(批梯度下降)的求解速度速度远快于sigmoid和tanh
- sigmoid 缺点
– 采用sigmoid等函数,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。在深层网络中,sigmoid函数 反向传播 时,很容易就会出现梯度梯度爆炸的情况
1.8.3.4 激活函数API
- tf.nn.relu(features, name=None)
– features:卷积后加上偏置的结果
– return:结果
1.8.4 池化层(Polling)
目的:减少特征数量,降低计算量
Pooling 层主要的作用是降低计算量,通过去掉 Feature Map 中不重要的样本,进一步减少参数数量。Pooling 的方法很多,通常采用最大池化
- max_polling:取池化窗口的最大值
- avg_polling:取池化窗口的平均值

1.8.4.1 池化层计算
池化层也有窗口的大小以及移动步长,那么之后的输出大小怎么计算?计算公式同卷积计算公式一样。
计算:224x224x64,窗口为2,步长为2输出结果?
H2 = (224 - 2 + 2*0)/2 +1 = 112
w2 = (224 - 2 + 2*0)/2 +1 = 112
通常池化层采用 2x2 大小、步长为 2 窗口。
1.8.4.2 池化层API
- tf.nn.max_pool(value, ksize=, strides=, padding=,name=None)
– 输入上执行最大池数
– value:4-D Tensor形状[batch, height, width, channels]
– channel:并不是原始图片的通道数,而是多少filter观察
– ksize:池化窗口大小,[1, ksize, ksize, 1]
– strides:步长大小,[1,strides,strides,1]
– padding:“SAME”, “VALID”,使用的填充算法的类型,默认使用“SAME”
1.8.5 全连接层
目的:输出类别概率
前面的卷积和池化相当于做特征工程,最后的全连接层在整个卷积神经网络中起到“分类器”的作用。
1.8.6 卷积神经网络总结

- 3 个卷积核对输入图片进行卷积,得到 3 张 28 * 28 的特征图;
- 进行下采样,特征图尺寸减半,但第三维不变;
- 8 个卷积核对上一层的特征图进行下采样,每个卷积核带有 3 张权重,共 24 张权重,得到 8 张 10 * 10 的特征图;
- 池化操作同前面,最后通过全连接层输出 100 个类别概率,由 softmax 激活函数将概率输出为确定的类别。
1.8.7 面试题练习

答案:C
1.9 案例:CNNMnist手写数字识别
学习目标
- 目标
应用 tf.nn.conv2d 实现卷积计算
应用 tf.nn.relu 实现激活函数计算
应用 tf.nn.max_pool 实现池化层的计算
应用卷积神经网路实现图像分类识别 - 应用
CNN-Mnist手写数字识别
1.9.1 数据集介绍

文件说明:
- train-images-idx3-ubyte.gz: training set images (9912422 bytes)
- train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
- t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
网址:http://yann.lecun.com/exdb/mnist/
1.9.2 特征值


1.9.3 目标值

1.9.4 Mnist数据获取API
TensorFlow框架自带了获取这个数据集的接口,所以不需要自行读取。
- from tensorflow.examples.tutorials.mnist import input_data
- mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
mnist.train.next_batch(100)(提供批量获取功能)
mnist.train.images、labels
mnist.test.images、labels
1.9.5 实战:Mnist手写数字识别

1.9.6 网络设计
我们自己定义一个卷积神经网络去做识别,这里定义的结构有些是通常大家都会采用的数量以及熟练整个网络计算流程。但是至于怎么定义结构是没办法确定的,也就是神经网络的黑盒子特性,如果想自己设计网络通常还是比较困难的,可以使用一些现有的网络结构如之前的GoogleNet、VGG等等.
1.9.6.1 网络结构

1.9.6.2 具体参数
- 第一层
卷积:32个filter、大小5*5、strides=1、padding=“SAME”
激活:Relu
池化:大小2x2、strides2 - 第一层
卷积:64个filter、大小5*5、strides=1、padding=“SAME”
激活:Relu
池化:大小2x2、strides2 - 全连接层
经过每一层图片数据大小的变化需要确定,Mnist 输入的每批次若干图片数据大小为 [None, 784],如果要进过卷积计算,需要变成 [None, 28, 28, 1]
- 第一层
卷积:[None, 28, 28, 1]———>[None, 28, 28, 32]
权重数量:[5, 5, 1 ,32]
偏置数量:[32]
激活:[None, 28, 28, 32]———>[None, 28, 28, 32]
池化:[None, 28, 28, 32]———>[None, 14, 14, 32] - 第二层
卷积:[None, 14, 14, 32]———>[None, 14, 14, 64]
权重数量:[5, 5, 32 ,64]
偏置数量:[64]
激活:[None, 14, 14, 64]———>[None, 14, 14, 64]
池化:[None, 14, 14, 64]———>[None, 7, 7, 64] - 全连接层
[None, 7, 7, 64]———>[None, 7 7 64]
权重数量:[7 7 64, 10],由分类别数而定
偏置数量:[10],由分类别数而定
1.9.7 案例:CNN识别Mnist手写数字
1.9.7.1 手写字识别分析
- 准备手写数字数据, 可以通过 tensorflow
- 实现前面设计的网络结构: 卷积、激活、池化(两层)
- 全连接层得到输出类别预测全连接层得到输出类别预测
- 计算损失值并优化计算损失值并优化
- 计算准确率计算准确率
1.9.7.2 代码
1. 网络结构实现:
def conv_model():
"""
自定义的卷积网络结构
:return: x, y_true, y_predict
"""
# 1、准备数据占位符
# x [None, 784] y_true [None, 10]
with tf.variable_scope("data"):
x = tf.placeholder(tf.float32, [None, 784])
y_true = tf.placeholder(tf.int32, [None, 10])
# 2、卷积层一 32个filter, 大小5*5,strides=1, padding=“SAME”
with tf.variable_scope("conv1"):
# 随机初始化这一层卷积权重 [5, 5, 1, 32], 偏置[32]
w_conv1 = weight_variables([5, 5, 1, 32])
b_conv1 = bias_variables([32])
# 首先进行卷积计算
# x [None, 784]--->[None, 28, 28, 1] x_conv1 -->[None, 28, 28, 32]
x_conv1_reshape = tf.reshape(x, [-1, 28, 28, 1])
# input-->4D
x_conv1 = tf.nn.conv2d(x_conv1_reshape, w_conv1, strides=[1, 1, 1, 1], padding="SAME") + b_conv1
# 进行激活函数计算
# x_relu1 -->[None, 28, 28, 32]
x_relu1 = tf.nn.relu(x_conv1)
# 进行池化层计算
# 2*2, strides 2
# [None, 28, 28, 32]------>[None, 14, 14, 32]
x_pool1 = tf.nn.max_pool(x_relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# 3、卷积层二 64个filter, 大小5*5,strides=1,padding=“SAME”
# 输入:[None, 14, 14, 32]
with tf.variable_scope("conv2"):
# 每个filter带32张5*5的观察权重,一共有64个filter去观察
# 随机初始化这一层卷积权重 [5, 5, 32, 64], 偏置[64]
w_conv2 = weight_variables([5, 5, 32, 64])
b_conv2 = bias_variables([64])
# 首先进行卷积计算
# x [None, 14, 14, 32] x_conv2 -->[None, 14, 14, 64]
# input-->4D
x_conv2 = tf.nn.conv2d(x_pool1, w_conv2, strides=[1, 1, 1, 1], padding="SAME") + b_conv2
# 进行激活函数计算
# x_relu1 -->[None, 28, 28, 32]
x_relu2 = tf.nn.relu(x_conv2)
# 进行池化层计算
# 2*2, strides 2
# [None, 14, 14, 64]------>x_pool2[None, 7, 7, 64]
x_pool2 = tf.nn.max_pool(x_relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# 4、全连接层输出
# 每个样本输出类别的个数10个结果
# 输入:x_poll2 = [None, 7, 7, 64]
# 矩阵运算: [None, 7 * 7 * 64] * [7 * 7 * 64, 10] +[10] = [None, 10]
with tf.variable_scope("fc"):
# 确定全连接层权重和偏置
w_fc = weight_variables([7 * 7 * 64, 10])
b_fc = bias_variables([10])
# 对上一层的输出结果的形状进行处理成2维形状
x_fc = tf.reshape(x_pool2, [-1, 7 * 7 * 64])
# 进行全连接层运算
y_predict = tf.matmul(x_fc, w_fc) + b_fc
return x, y_true, y_predict
2. 损失计算优化、准确率计算:
# 1、准备数据API
mnist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True)
# 2、定义模型,两个卷积层、一个全连接层
x, y_true, y_predict = conv_model()
# 3、softmax计算和损失计算
with tf.variable_scope("softmax_loss"):
# labels:真实值 [None, 10] one_hot
# logits:全脸层的输出[None,10]
# 返回每个样本的损失组成的列表
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,
logits=y_predict))
# 4、梯度下降损失优化
with tf.variable_scope("optimizer"):
# 学习率
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# train_op = tf.train.AdamOptimizer(0.1).minimize(loss)
# 5、准确率计算
with tf.variable_scope("accuracy"):
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
# 初始化变量op
init_op = tf.global_variables_initializer()
会话运行:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
tf.app.flags.DEFINE_integer("is_train", 1, "指定是否是训练模型,还是拿数据去预测")
FLAGS = tf.app.flags.FLAGS
# 定义两个专门初始化权重和偏置的函数
def weight_variables(shape):
w = tf.Variable(tf.random_normal(shape=shape, mean=0.0, stddev=0.1))
return w
def bias_variables(shape):
b = tf.Variable(tf.random_normal(shape=shape, mean=0.0, stddev=0.1))
return b
def cnn_model():
"""
自定义CNN 卷积模型
第一层
卷积:32个filter、大小5 * 5、strides = 1、padding = "SAME"
激活:Relu
池化:大小2x2、strides2
第一层
卷积:64个filter、大小5 * 5、strides = 1、padding = "SAME"
激活:Relu
池化:大小2x2、strides2
全连接层: [7*7*64, 10] [10]
:return:
"""
# 1、准备数据的占位符,便于后面卷积计算
# x [None, 784], y_true = [None, 10]
with tf.variable_scope("x_data"):
x = tf.placeholder(tf.float32, [None, 784], name="x")
y_true = tf.placeholder(tf.int32, [None, 10], name="y_true")
# 2、第一层
# 卷积:32个filter、大小5 * 5、strides = 1、padding = "SAME"
# 激活:Relu
# 池化:大小2x2、strides2
with tf.variable_scope("conv_1"):
# 准备权重和偏置参数
# 权重数量:[5, 5, 1 ,32]
# 偏置数量:[32]
w_conv1 = weight_variables([5, 5, 1, 32])
b_conv1 = bias_variables([32])
# 特征形状变成4维,用于卷积运算
x_reshape = tf.reshape(x, [-1, 28, 28, 1])
# 进行卷积,激活函数运算
# [None, 28, 28, 1]--->[None, 28, 28, 32]
# [None, 28, 28, 32]--->[None, 28, 28, 32]
x_relu1 = tf.nn.relu(tf.nn.conv2d(x_reshape,
w_conv1,
strides=[1, 1, 1, 1],
padding="SAME",
name="conv1") + b_conv1,
name="relu1")
# 进行池化层
# [None, 28, 28, 32]--->[None, 14, 14, 32]
x_pool1 = tf.nn.max_pool(x_relu1,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding="SAME",
name="pool1")
# 3、第二层
# 卷积:64 个filter、大小5 * 5、strides = 1、padding = "SAME"
# 激活:Relu
# 池化:大小2x2、strides2
with tf.variable_scope("conv_2"):
# 确定权重、偏置形状
# 权重数量:[5, 5, 32, 64]
# 偏置数量:[64]
w_conv2 = weight_variables([5, 5, 32, 64])
b_conv2 = bias_variables([64])
# 进行卷积、激活运算
# 卷积:[None, 14, 14, 32]--- >[None, 14, 14, 64]
# 激活:[None, 14, 14, 64]--- >[None, 14, 14, 64]
x_relu2 = tf.nn.relu(tf.nn.conv2d(x_pool1,
w_conv2,
strides=[1, 1, 1, 1],
padding="SAME",
name="conv2") + b_conv2,
name='relu2')
# 进行池化运算
# 池化:[None, 14, 14, 64]--- >[None, 7, 7, 64]
x_pool2 = tf.nn.max_pool(x_relu2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding="SAME",
name="pool2")
# 4、全连接层
# 全连接层: [7 * 7 * 64, 10][10]
with tf.variable_scope("fc"):
# 初始化权重,偏置
w_fc = weight_variables([7 * 7 * 64, 10])
b_fc = bias_variables([10])
# 矩阵运算转换二维
x_fc_reshape = tf.reshape(x_pool2, [-1, 7 * 7 * 64])
# 全连接层矩阵运算
y_predict = tf.matmul(x_fc_reshape, w_fc) + b_fc
return x, y_true, y_predict
def train():
"""
卷积网络识别训练
:return:
"""
# 1、准备数据输入
mnist = input_data.read_data_sets("./data/mnist/input_data/", one_hot=True)
# 2、建立卷积网络模型
# y_true :[None, 10]
# y_predict :[None, 10]
x, y_true, y_predict = cnn_model()
# 3、根据输出结果与真是结果建立softmax、交叉熵损失计算
with tf.variable_scope("softmax_cross"):
# 先进性网络输出的值的概率计算softmax,在进行交叉熵损失计算
all_loss = tf.nn.softmax_cross_entropy_with_logits(labels=y_true,
logits=y_predict,
name="compute_loss")
# 求出平均损失
loss = tf.reduce_mean(all_loss)
# 4、定义梯度下降优化器进行优化
with tf.variable_scope("GD"):
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 5、求出每次训练的准确率为
with tf.variable_scope("accuracy"):
# 求出每个样本是否相等的一个列表
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
# 计算相等的样本的比例
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
# (2)、收集要显示的变量
# 先收集损失和准确率
tf.summary.scalar("losses", loss)
tf.summary.scalar("acc", accuracy)
# 初始化变量op
init_op = tf.global_variables_initializer()
# (3)、合并所有变量op
merged = tf.summary.merge_all()
# 创建模型保存和加载
saver = tf.train.Saver()
# 开启会话进行训练
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# (1)创建一个events文件实例
file_writer = tf.summary.FileWriter("./tmp/summary/", graph=sess.graph)
# 加载模型
if os.path.exists("./tmp/modelckpt/checkpoint"):
saver.restore(sess, "./tmp/modelckpt/fc_nn_model")
if FLAGS.is_train == 1:
# 循环步数去训练
for i in range(1000):
# 每批次给50个样本
mnist_x, mnist_y = mnist.train.next_batch(50)
_, loss_run, acc_run = sess.run([train_op, loss, accuracy],
feed_dict={x: mnist_x, y_true: mnist_y})
# 打印每部训练的效果
print("第 %d 步的50个样本损失为:%f , 准确率为:%f" % (i, loss_run, acc_run))
# 运行合变量op,写入事件文件当中
summary = sess.run(merged, feed_dict={x: mnist_x, y_true: mnist_y})
file_writer.add_summary(summary, i)
if i % 100 == 0:
saver.save(sess, "./tmp/modelckpt/fc_nn_model")
else:
# 如果不是训练,我们就去进行预测测试集数据
for i in range(100):
# 每次拿一个样本预测
mnist_x, mnist_y = mnist.test.next_batch(1)
print("第%d个样本的真实值为:%d, 模型预测结果为:%d" % (
i + 1,
tf.argmax(sess.run(y_true, feed_dict={x: mnist_x, y_true: mnist_y}), 1).eval(),
tf.argmax(sess.run(y_predict, feed_dict={x: mnist_x, y_true: mnist_y}), 1).eval()
)
)
return None
if __name__ == '__main__':
train()