目录
一、用于HTTP请求中的常用请求头字段
Accept:用于高速服务器,客户机支持的数据类型
Accept-Charset:用于告诉服务器,客户机采用的编码格式
Accept-Encoding:用于告诉服务器,客户机支持的数据压缩格式
Accept-Language:客户机的语言环境
Host:客户机通过这个头高速服务器,想访问的主机名
If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间
Referer:客户机通过这个头告诉服务器,它是从哪个资源来访问服务器的(防盗链)
User-Agent:客户机通过这个头告诉服务器,客户机的软件环境
Cookie:客户机通过这个头可以向服务器带数据
Connection:处理完这次请求后是否断开连接还是继续保持连接
Date:当前时间值
1. 请求报文
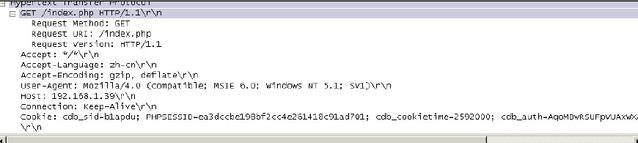
HTTP协议使用TCP协议进行传输,在应用层协议发起交互之前,首先是TCP的三次握手。完成了TCP三次握手后,客户端会向服务器发出一个请求报文。请求报文的格式如下图抓包所示:
(1)前三行为请求行,其余部分称为 request-header。
请求行中的method表示这次请求使用的是get方法。请求方法的种类比较多,如option, get post head put,delete,trace等,常用的主要是get,pos。
Get表示请求页面信息,返回页面实体;
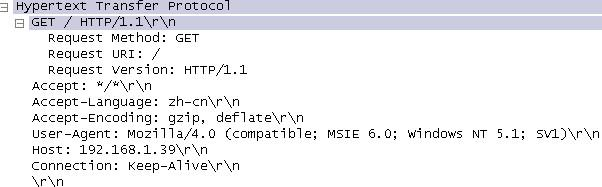
post是请求服务器将指定文档作为请求的url中的从属实体,简单说,我们常用的在网页中填写表单然后申请等动作就是使用了post方法,填写用户名密码登录站点就使用了post方法,如下图:

(2)方法之后是URI,表示请求的页面地址,图中的“/”表示服务器的根目录。之后是表示http的版本。
(3)请求行之后是请求首部。首部常见的部分有如下几个:
l Accept:请求的对象类型。如果是“/”表示任意类型,如果是指定的类型,则会变成“type/”。
l Accept-Language:使用的语言种类。
l Accept-Encording:页面编码种类。
l Accept-Charset:页面字符集。说到这里,需要解释以下字符集和编码的区别。字符集通常对应着一种语言,将语言中的所有字符集合起来就可以视为一种字符集,这样我们可以看出,中文并非是一种字符集,因为中文无法使用一些字符来进行表示;而编码则是将字符转换为计算机所能识别的2进制数的一种方式,例如常说的unicode,UTF-8,ANSI等等,我们在访问一些国外网站会出现乱码的原因就是因为我们浏览器所使用的编码与页面所使用的编码不能互相识别。我们常说的BIG5和GB2312都是编码。
l User-Agent:提供了客户端浏览器的类型和版本。
l Host:连接的目标主机,如果连接的服务器是非标准端口,在这里会出现使用的非标准端口。
l Connection:对于HTTP连接的处理,keep-alive表示保持连接,如果是在响应报文中发送页面完毕就会关闭连接,状态变为close。
二、HTTP响应
1、状态行:
用于描述服务器对请求的处理结果。
2、状态码:
100~199:表示成功接收请求,要求客户端继续提交下一次请求才能完成整个处理过程。
200~299:表示成功接收请求并已完成整个处理过程。常用200
300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(意味着你请求我,我让你去找别人),307和304(我不给你这个资源,自己拿缓存)
400~499:客户端的请求有错误,常用404(意味着你请求的资源在web服务器中没有)403(服务器拒绝访问,权限不够)
500~599:服务器端出现错误,常用500
3、多个响应头:
响应头用于描述服务器的基本信息,以及数据的描述,服务器通过这些数据的描述信息,可以通知客户端如何处理等一会儿它回送的数据。
Location:这个头配合302状态码使用,用于告诉客户找谁。
Server:服务器通过这个头告诉浏览器服务器的类型。
Content-Encoding:服务器通过这个头告诉浏览器数据的压缩格式。
Content-Length:服务器通过这个头告诉浏览器回送数据的长度
Content-Type:服务器通过这个头告诉浏览器回送数据的类型
Last-Modified:告诉浏览器当前资源的最后缓存时间
Refresh:告诉浏览器隔多久刷新一次
Content-Disposition:告诉浏览器以下载方式打开数据
Transfer-Encoding:告诉浏览器数据的传送格式
ETag:缓存相关的头
4、三种禁止浏览器缓存的头字段:
Expires:告诉浏览器把回送的资源缓存多长时间 -1或0则是不缓存
Cache-Control:no-cache
Pragma:no-cache
服务器通过以上两个头,也就是控制浏览器不要缓存数据
实体内容:代表服务器向客户端回送的数据
5、常见状态码解析
l200(正常)表示一切正常,返回的是正常请求结果。
l302/307(临时重定向)指出被请求的文档已被临时移动到别处,此文档的新的URL在Location响应头中给出。
l304(未修改)表示客户机缓存的版本是最新的,客户机应该继续使用它。
l403(禁止)服务器理解客户端请求,但拒绝处理它。通常由于服务器上文件或目录的权限设置所致。
l404(找不到)服务器上不存在客户机所请求的资源。
l500(内部服务器错误)服务器端的CGI、ASP、JSP等程序发生错误。
当收到get或post等方法发来的请求后,服务器就要对报文进行响应。同样,响应报文也分为两部分。
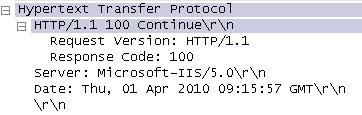
6、 前两行称为状态行
状态行给出了服务器的http版本,以及一个响应代码。
响应代码是服务器根据请求进行查找后得到的结果的一种反馈,共有5大类。分别以1、2、3、4、5开头。
1**表示接收到请求,继续进程,在发送post后可以收到该应答。
2**表示请求的操作成功,在发送get后返回。
3**表示重发,为了完成操作必须进一步动作。
4**表示客户端出现错误。
5**表示服务器出现错误。
7 、其余部分称为应答实体
其中的server表示服务器软件版本,
date标注了当前服务器的时间,
connection标明连接关闭,抓包可以发现在响应返回后服务器向客户端发出fin包单向关闭了连接。
Expires表示在某个时间以前可以不用重新缓存该页面,
cache-control表示对页面是否进行缓存。
Pragma的参数no-cache表示对页面不进行缓存。
content-type表示了应答请求后返回的内容类型。
Content还有内容长度和内容语言以及内容编码三个项,其中内容长度只有在请求报文中的connection值为keep-alive时才会用到。
8、常见问题
1.请按自己的理解简述HTTP 1.1与HTTP 1.0的区别。
HTTP1.0对于每个连接都的建立一次连接一次只能传送一个请求和响应,请求就会关闭,HTTP1.0没有Host字段;
而HTTP1.1在同一个连接中可以传送多个请求和响应,多个请求可以重叠和同时进行,HTTP1.1必须有Host字段。
2.请描述HTTP请求消息和HTTP响应消息的组成结构,并各举一例进行说明。
请求消息结构:一个请求行、若干消息头、以及尸体内容,当中的一些消息头和实体内容都是可选的,消息头和实体内容之间要用空行隔开。
响应消息结构:一个状态行、若干消息头、以及尸体内容,当中的一些消息头和实体内容都是可选的,消息头和实体内容之间要用空行隔开。
两者的区别:就是请求消息有请求行,响应消息有状态行。
GET /mail/aa.html HTTP/1.1
Accept: text/html, application/xhtml+xml, */*
Accept-Language: zh-CN
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)
Accept-Encoding: gzip, deflate
Host: localhost:8080
If-Modified-Since: Wed, 17 Oct 2012 09:35:13 GMT
If-None-Match: W/"62-1350466513174"
Connection: Keep-AliveHTTP/1.1 304 Not Modified
Server: Apache-Coyote/1.1
ETag: W/"62-1350466513174"
Date: Wed, 17 Oct 2012 09:45:38 GMT3.浏览器分别在哪些情况下使用GET方式和POST方式访问WEB服务器?如果浏览器传递给WEB服务器的参数内容超过1K,应该使用那种方式发送请求消息?
数据量不大,因为GET方式数据量限制1K,不带有保护数据的情况下使用GET方式访问WEB服务器;数据量大,而且带有需要保护的数据时使用POST方式访问WEB服务器。
如果浏览器传送服务器的数据量超过1K,应使用POST方式访问服务器,因为POST方式向服务器传送是数据时,会先把传送的数据打包发送到WEB服务器。
4.请描述200、302、304、404和500等响应状态码所表示的意义。
200:表示成功,正常结果;
302:表示重定向,转到别的站点;
304:表示未修改;
404:表示找不到资源;
500:表示内部服务器错误;
5.请列举三种禁止浏览器缓存的头字段,并写出相应的设置值。
Expires:告诉浏览器把回送的资源缓存多长时间 -1或0则是不缓存
Cache-Control:no-cache
Pragma:no-cache
三. Cookie
(1)概念及作用
cookie是一种类似缓存的机制,它保存在一个本地的文本文件中,
其主要作用是在发送请求时将cookie放在请求首部中发送给服务器,服务器收到cookie后查找自己已有的cookie信息,确定客户端的身份,然后返回相应的页面,cookie的方便之处在于可以保持一种已登录的状态,
例如:我们注册一个论坛,每次访问都需要进行填写用户名和密码然后登录。而使用了cookie后,如果cookie没有到达过期时间,那么我们只需在第一次登录时填写信息然后登录,以后的访问就可以省略这一步骤。
(2) 交互过程
在HTTP协议中,cookie的交互过程是这样的:
首先是三次握手建立TCP连接,
然后客户端发出一个http request,这个request中不包含任何cookie信息。
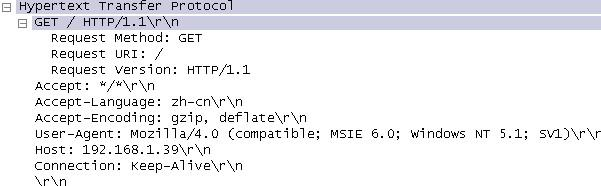
当服务器收到这个报文后,针对request method作出响应动作,在响应报文的实体部分,加入了set-cookie段,set-cookie段中给出了cookie的id,过期时间以及参数path,path是表示在哪个虚拟目录路径下的页面可以读取使用该cookie,将这些信息发回给客户端后,客户端在以后的http request中就会将自己的cookie段用这些信息填充。

如果用户在连接中通过了服务器相应的认证程序,服务器会添加一个cdb_auth到set-cookie中,这个段表示了客户端的认证信息,而客户端以后在访问过程中也会将cdb_auth信息写入自己的cookie字段。服务器每次收到http request后读取cookie,然后根据cookie的信息返回不同的页面。例如,没有通过认证的客户端在request中不会有cdb_auth,因此服务器读取cookie后,不会将通过认证的客户端的页面返回给该客户端。