基本概念
树(Tree)
如果一个无向连通图中不存在回路,则这种图称为树。
生成树 (Spanning Tree)
无向连通图G的一个子图如果是一颗包含G的所有顶点的树,则该子图称为G的生成树。
生成树是连通图的极小连通子图。这里所谓极小是指:若在树中任意增加一条边,则将出现一条回路;若去掉一条边,将会使之变成非连通图。
最小生成树
一个带权值的连通图。用$n-1$条边把$n$个顶点连接起来,且连接起来的权值最小。
应用场景
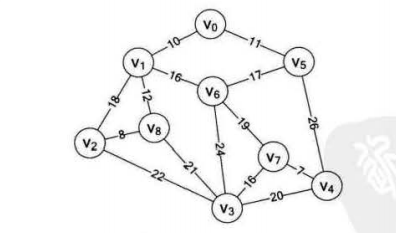
设想有9个村庄,这些村庄构成如下图所示的地理位置,每个村庄的直线距离都不一样。若要在每个村庄间架设网络线缆,若要保证成本最小,则需要选择一条能够联通9个村庄,且长度最小的路线。
Kruskal算法
知识点:数据结构——并查集
基本思想
始终选择当前可用、不会(和已经选取的边)构成回路的最小权植边。
具体步骤:
1. 将所有边按权值进行降序排序
2. 依次选择权值最小的边
3. 若该边的两个顶点落在不同的连通分量上,选择这条边,并把这两个顶点标记为同一连通分量;若这条边的两个顶点落到同一连通分量上,舍弃这条边。反复执行2,3,直到所有的都在同一连通分量上。【这一步需要用到上面的并查集】
模板题:https://www.luogu.org/problem/P3366
#include <iostream> #include <algorithm> #include <fstream> using namespace std; int pre[5005]; int n, m; //n个定点,m条边 struct ENode { int from, to, dis; bool operator<(ENode p) { return dis < p.dis; } }M[200005]; void initialize() { for (int i = 0; i <= 5000; i++) { pre[i] = i; } } int Find(int x) { return x == pre[x] ? pre[x] : pre[x] = Find(pre[x]); } int kurskal() { int N = n, res = 0; initialize(); for (int i = 0; i < m && N > 1; i++) { int fx = Find(M[i].from), fy = Find(M[i].to); if (fx != fy) { pre[fx] = fy; N--;//找到了一条边,当N减到1的时候表明已经找到N-1条边了,就完成了 res += M[i].dis; } } if (N == 1)//循环做完,N不等于1 表明没有找到合适的N-1条边来构成最小生成树 return res; return -1; } int main() { #ifdef LOCAL fstream cin("data.in"); #endif // LOCAL cin >> n >> m; for (int i = 0; i < m; i++) { cin >> M[i].from >> M[i].to >> M[i].dis; } sort(M, M + m); int ans = kurskal(); if (ans != -1) cout << ans << endl; else cout << "orz" << endl; return 0; }
Prim算法
Prim算法思想:
首先将图的点分为两部分,一种是访问过的$u$(第一条边任选),一种是没有访问过的$v$
1: 每次找$u$到$v$的权值最小的边。
2: 然后将这条边中的$v$中的顶点添加到$u$中,直到$v$中边的个数$=$顶点数$-1$
图解步骤:
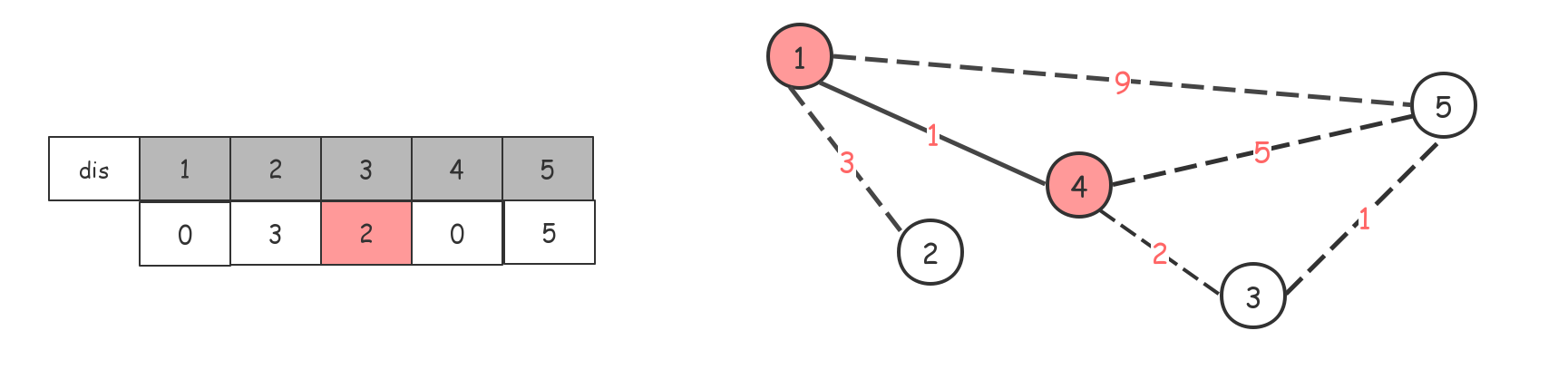
维护一个$dis$数组,记录只使用已访问节点能够到达各未访问节点最短的权值。
初始值为节点1(任意一个都可以)到各点的值,规定到自己是0,到不了的是$inf$(定义一个特别大的数)。
找当前能到达的权值最短的点。1-->4,节点4
 、
、
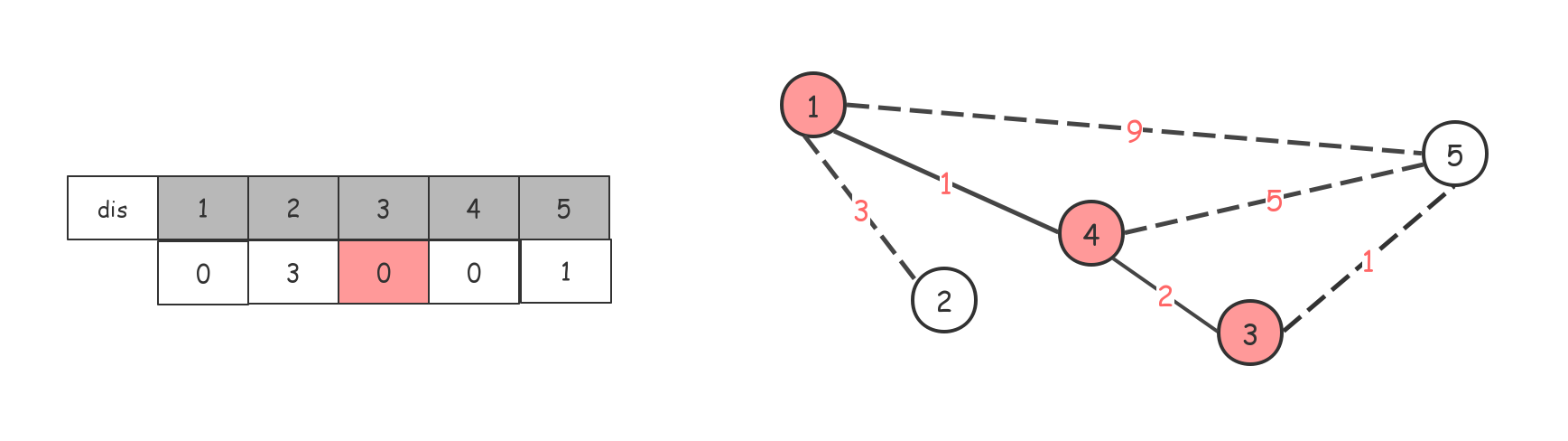
将dis[4]赋值为0,标记为已访问过,同时借助4节点更新dis数组。
后面依次
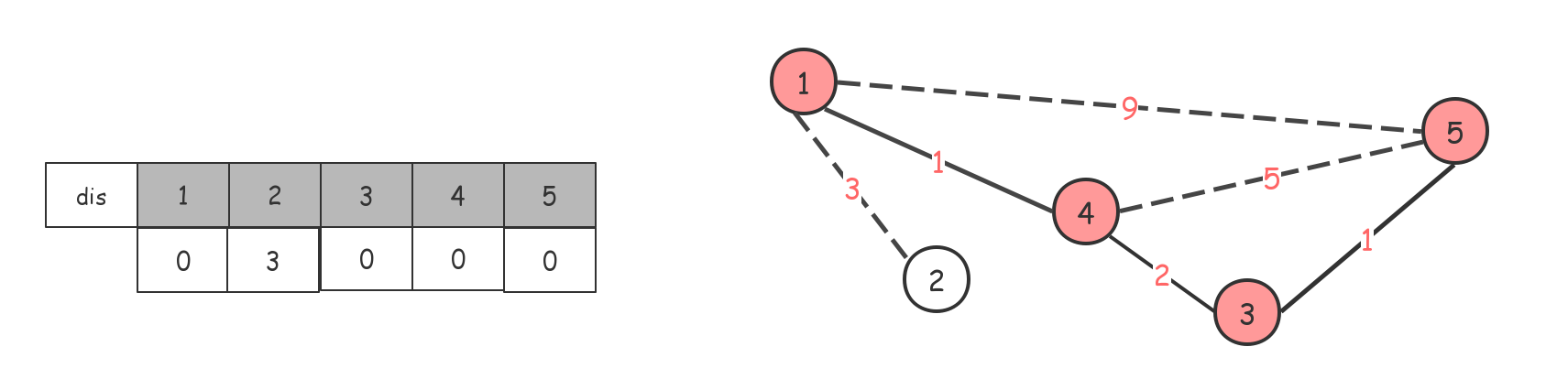
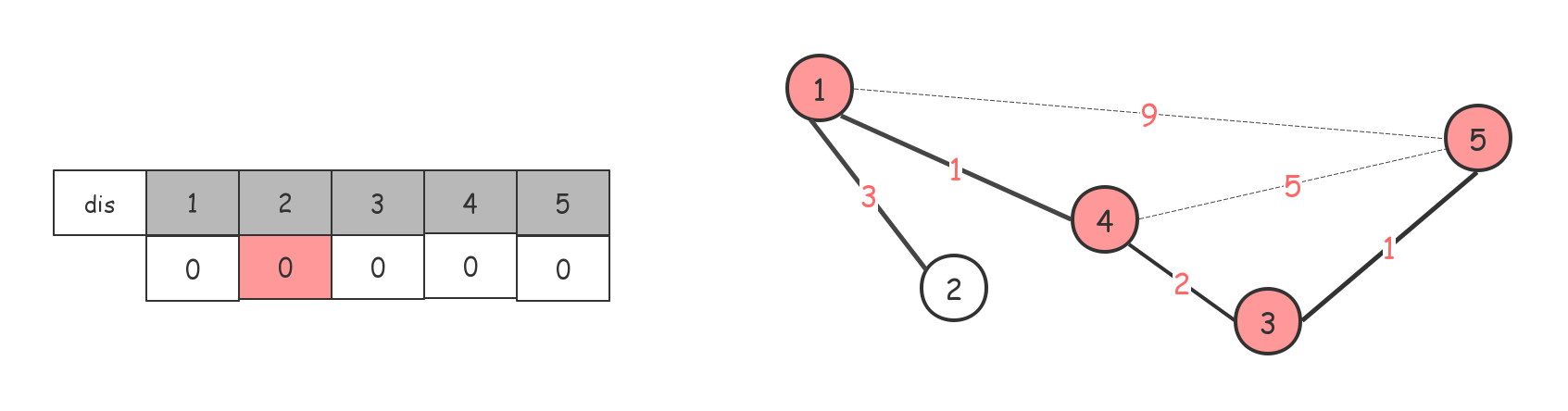
最后整个dis数组都是0了,最小生成树也就出来了,如果$dis$数组中还有 $inf$ 的话,说明这不是一个连通图。
还是上面那道模板题:https://www.luogu.org/problem/P3366
#include <iostream> #include <fstream> using namespace std; typedef long long LL; struct ENode { int dis, to;//权重、指向 ENode* next = NULL; void push(int to, int dis) { ENode* p = new ENode; p->to = to; p->dis = dis; p->next = next; next = p; } }*head; const int inf = 1 << 30; int n, m; int dis[5005]; int prim() { int res = 0; dis[1] = 0; for (int i = 2; i <= n; i++) { dis[i] = inf; } ENode* p = head[1].next; while (p) { if (p->dis < dis[p->to])//看了题目数据,有重边 dis[p->to] = p->dis; p = p->next; } for (int i = 1; i < n; i++) { int v,MIN = inf; for (int j = 1; j <= n; j++) { //到不了的,访问过的不进行比较 if (dis[j] != 0 && dis[j] < MIN) { v = j; MIN = dis[j]; } } if (MIN == inf) return -1;//没找够M-1条线,就没路了 res += dis[v]; dis[v] = 0; p = head[v].next; while (p) { if (dis[p->to] > p->dis) { dis[p->to] = p->dis; } p = p->next; } } return res; } int main() { #ifdef LOCAL fstream cin("data.in"); #endif // LOCAL cin >> n >> m; head = new ENode[n + 1]; for (int i = 0; i < m; i++) { int from, to, dis; cin >> from >> to >> dis; head[from].push(to, dis); head[to].push(from, dis); } int ans = prim(); if (ans != -1) cout << ans << endl; else cout << "orz" << endl; return 0; }
两者区别
时间复杂度
prim算法
时间复杂度为$O(n^2)$,$n$为顶点的数量,其时间复杂度与边得数目无关,适合稠密图。
kruskal算法
时间复杂度为$O(e\cdot loge)$,$e$为边的数目,与顶点数量无关,适合稀疏图。其实就是排序的时间,因为并查集的查询操作时$O(1)$,如果建堆的话会更快一些,自下而上建堆复杂度是$O(n)$,最好自己实现,用priority_queue试了一下,为啥更慢了![]() 。
。
通俗点说就是,点多边少用Kruskal,因为Kruskal算法每次查找最短的边。 点少边多用Prim,因为它是每次找一个顶点。
具体选择用那个,可以用电脑算一下,题目给的数据级别,$n^2$和$e\cdot loge$看看那个小,比如上面的模板题,题目给的数据级别是$(n<=5000,e<=200000)$,粗略估算一下,kurskal算法一定是会快不少的。
kurskal算法

prim算法

实现难度
明眼人都能看出来,kurskal算法要简单太多了。kurskal算法不需要把图表示出来,而Prim算法必须建表或者邻接矩阵,所以从上面的数据也能看出来当边的数目较大时,Prim算法所占用的空间比kurskal算法多了很多。
拓展
堆优化Prim算法
使用堆优化后的Prim算法时间复杂度为$O(nlogn)$。

#include<cstdio> #include<queue> #include<cstring> #include<algorithm> #define R register int using namespace std; int k,n,m,cnt,sum,ai,bi,ci,head[5005],dis[5005],vis[5005]; struct Edge { int v,w,next; }e[400005]; void add(int u,int v,int w) { e[++k].v=v; e[k].w=w; e[k].next=head[u]; head[u]=k; } typedef pair <int,int> pii; priority_queue <pii,vector<pii>,greater<pii> > q; void prim() { dis[1]=0; q.push(make_pair(0,1)); while(!q.empty()&&cnt<n) { int d=q.top().first,u=q.top().second; q.pop(); if(vis[u]) continue; cnt++; sum+=d; vis[u]=1; for(R i=head[u];i!=-1;i=e[i].next) if(e[i].w<dis[e[i].v]) dis[e[i].v]=e[i].w,q.push(make_pair(dis[e[i].v],e[i].v)); } } int main() { memset(dis,127,sizeof(dis)); memset(head,-1,sizeof(head)); scanf("%d%d",&n,&m); for(R i=1;i<=m;i++) { scanf("%d%d%d",&ai,&bi,&ci); add(ai,bi,ci); add(bi,ai,ci); } prim(); if (cnt==n)printf("%d",sum); else printf("orz"); }