一直想撸个搜索框,本想使用第三方,但有些第三方维护的人太少,作者提交的又有bug,踩坑之后果断放弃。看了一下,系统自带的搜索框样式还是阔以滴,系统自带的虽然不算特别丑,但不能实现个性化需求,不过也可以先学着用~
其实也很简单,先po上效果图
首先我把toolbar做了改动,
1.主题theme改为noActionBar,
2.在xml文件中声明
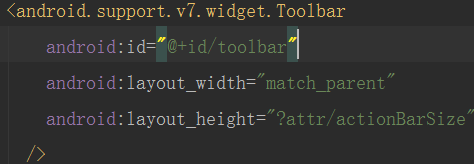
3.在主activity文件中设置相关属性,像这样

当然还有其他属性,根据需要自行添加。
最后不要忘记setSupportActionBar(toolbar);这里的话容易出错,如果是方法名出错标红,很有可能是你activity继承的问题,例如

改成

如果是参数出错,很简单,看波浪线的提示,嗯没错,你导包错了,导android.support.v7.widget.Toolbar就好了
再结合searchview
1.写个menu

这里我只加了一个,如果多个item的话,会收纳成几个垂直排列的小点点,像这样,
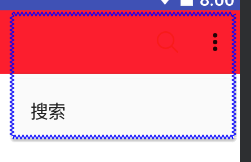 那么showadaction这些属性就要好好弄弄啦,你也可以设置这个框的相关属性,这里不做展开。
那么showadaction这些属性就要好好弄弄啦,你也可以设置这个框的相关属性,这里不做展开。
2.在onCreateOptionsMenu方法里加载
其他属性可以查询官方文档SearchView|Android开发者
参考文章Toolbar-妖久-博客园,SearchView使用详解

到这里,toolbar处加个系统自带searchview的工作就完成了。
下面是集成科大讯飞的语音识别sdk。
网上有一些参照文章,但是隐藏有一些坑,最踏实的就是老老实实按照官方文档来。诺here~讯飞开放平台
我用的是AS做语音识别,看文档。android开发文档
1.在平台上注册你自己的应用,选择想要的AI能力,获取对应sdk以及appid。
2.下载下来的包里面有一个readme.txt文档,根据需要严格执行里面说的tips。
(1)使用带UI接口时,请将assets下文件拷贝到项目中。也就是说我需要做一个可以看到对话交互界面的语音识别,就得这么做。那就拷贝吧。
(2)demo 使用时,以import module 形式导入到自己的工程。这个demo,emmmm…我没有去实际运行过,但网上用过都说是可以的,那应该没问题吧。这个时候如果你以为自己不需要使用demo,就不做这一步的话,那么下面你就会发现,那些方法什么的都标红提示找不到。嗯,所以还是导吧~
(3)在调用sdk时,请将res/layout下xml文件拷贝至工程的layout目录下。此文件为sdk内置ui所需,资源缺失会导致sdk部分功能无法使用。所以,拷贝。
(4)接下来一点是很关键的配置,在project下,把libs文件夹里面的东西复制到AS的libs,在main下面建一个jniLibs文件夹,将libs里面的文件也复制一份进去,包括各个平台的.so文件。当然也可以按官网说的,根据需要引入平台库文件.so。
3.初始化SDK。注意:这里的appid是你自己应用的id,不能用别人的。是以应用为单位,不是以设备为单位。简而言之,只要你是对同一应用进行操作就行,不管你是运行在哪台手机上。也可以用SpeechConstant.APPID +"=appid"。

4.在manifest里添加对应权限,根据需要添加。具体看文档。

5.继续看文档语音听写

还是仔细来说说。
这个部分可以实现一个InitListener接口,初始化结束时,回调此接口通知应用层,初始的状态。如果不需要获取,也可以设置为null;详细可以看InitListener

参数设置也是很关键的一part,

参数啊参数,文档也有很详细的说明。懒得说了。。。参数设置介绍【官网】
ok,再处理一下监听。最后调用.show()显示对话框。
在显示对话框后,录音自动开始,RecognizerDialog中包含了根据当前状态显示不同照片的处理,如声音的大小,错误的提示;
同时,点击对话框内任意地方,可结束录音,点击对话框外,则取消会话;
出现错误后,再点击对话框内,可启动下一次会话。应用根据回调状态,进行结果和错误的处理。
需要注意的是,若当前音频源为麦克风,则将自动开启录音;若音频源为写音频流,则应用可通过调用SpeechRecognizer.writeAudio()写入音频数据。更多详细内容可看RecognizerDialog
一般识别出来的结果有json,xml,plain三种数据格式。默认是json格式。官网提供了一个处理类来处理json格式的数据,这个可以在demo查看到,详细可以看我上传的附件。
最后将处理好的数据显示在你想显示的地方。完~