文章目录
SSD框架:
1.在几个不同feature map的scales的每个位置上,用卷积的方式评估一些不同aspect ratios的默认框。
2.对每个默认框,预测box外形的偏移和全部类别的置信度。
3.在训练的时候,首先将gt-box和默认框匹配,匹配上的是正样本,其他的是负样本,然后对负难例进行挖掘。
3.模型的loss是每个回归loss和置信度loss的和。(回归是Smooth L1,置信度是Softmax)
网络结构图

1. Model
方法概括:SSD方法基于前向传播网络,生成一些固定大小的边界框集合,然后评估在这些框里的物体的置信度并且调整框。
流程
基础网络:
网络的前面基础部分是一个用来为高质量图像分类提供特征的网络(VGG16),叫做base network。
生成多尺度特征图:
在base network之后加上size逐渐减小的多尺度的特征层,用来检测目标的每个卷积模型在每个特征层都不一样(每个特征层尺度不同,要检测的大小也不同,所以卷积模型不同很合理)。

对多尺度特征图进行卷积:
对于
维度的feature map(在base network后添加的层),我们使用
的过滤器,就可以生成一些固定维度的检测预测。
这个过滤器既可以生成置信度分数,也可以生成边界框偏移(相对于feature map的每个cell的anchor的偏移),在
的每个cell上都会产生一个输出。(yolo使用的是全连接层,而不是卷积过滤器)
设置默认框:
对feature map中的每个cell预测偏移框(4个值)和分类分数(c个类,c个值),假如每个cell有k个框,那么过滤器的数量就是
,整个feature map提取之后就是
个参数。默认框的概念和Faster RCNN的anchor boxes类似。
训练的时候只预测正样本的anchor,而推理的时候全部都预测
2. Training
SSD的不同之处在于,真实边界框需要被分配给特定的检测的输出。
一旦上述分配被固定,loss和反向传播被端到端应用。
训练还涉及到选择一些默认框,检测尺度,负难例挖掘,数据增强策略。
1.数据增强
为了让模型对多种输入图片的尺寸和形状更加鲁棒,每个image都挑选下面一种方法进行处理:
- 使用全部原始图片
- 采样一小块,让和目标的最小jaccard 重叠部分是0.1,0.3,0.5,0.7,或0.9
- 随即采样一小块
每一小块的尺寸是原始尺寸的[0.1,1],长宽比是[0.5,2],如果ground truth box的中心在采样patch中,我们就保留它的重叠部分。
在上述采样之后,每个被采样的部分都被resize成固定的大小,并以50%的概率水平反转。
2.选择默认框的长宽比和比例
对于每个特征图来说,SSD引入初始框的概念,也就是说在每个特征图的单元格的中心设置一系列尺度和大小不同的初始框,这些初始框都会反向映射到原图的某一个位置,如果某个初始框的位置正好和真实目标框的位置重叠度很高,那么就通过损失函数预测这个初始框的类别,同时对这些初始框的形状进行微调,以使其符合我们标记的真实目标框。

通过利用来自几个不同的特征层的特征,也能达到用不同的size处理图片然后将前向传播的结果组合在一起的效果,而且还有共享参数的效果。使用底层卷积可以更好地获得输入图片的细节。
通过[Looking wider to see better]中,添加全局环境池化能对平滑和分割结果产生帮助,引发了作者的,即使用低层的特征也使用高层的特征来进行检测。(idea)
一个网络中不同的层级的感受野不同,然而在SSD中,默认框不需要对应每一层的实际的感受野。作者让默认框平铺(像瓷砖一样),然后用一个公式来计算默认框在每个特征图上的缩放:

其中, 是检测特征图的个数, 是最低层的缩放, 是最高层的缩放,所有的层在这两个之间都存在有规则的间隔,每个特征图上的默认框尺度如下图:
| index | Feature map | Feature map size | Default box Scale (in original image) | true size |
|---|---|---|---|---|
| 1 | conv4_3 | 38 | 0.2 | 60 |
| 2 | conv7 | 19 | 0.34 | 102 |
| 3 | conv8_2 | 10 | 0.48 | 144 |
| 4 | conv9_2 | 5 | 0.62 | 186 |
| 5 | conv10_2 | 3 | 0.76 | 228 |
| 6 | conv11_2 | 1 | 0.9 | 270 |
特征图就如同人的视野的大小,在低层特征图中,每个格子的感受野很小,更为关注图像的细节,此时,默认框的大小也很小,是整个图片的0.2倍(300 x 0.2 = 60);随着层数的加深,每个格子的感受野越来越大,更为关注图像的抽象信息,就像人的视野越来越小一样,这时候默认框的大小就变大了,约等于整个图片(300 x 0.9 = 270)
相应的属性如下:
- 长宽比
- 宽:
- 高:
- 中心: ( , ), 是第 个特征块的尺寸,
对于比例为1的初始框,特别设置为
在使用的时候还可以根据特定的检测调整平铺框的位置。
3.默认框和真实框匹配
在训练的时候我们需要知道哪个默认框对应着哪个ground truth检测,然后以此来训练网络。
对于每个ground truth框,我们选择的之前生成的默认框。
我们首先将每个ground truth框与具有最高IoU的默认框匹配(一个),然后将默认框和任何有着大于0.5 IoU的ground truth匹配(一个)。
所以,一个默认框可能对应多个真实框,而一个真实框只对应一个默认框?还是说先使用0.5的策略,如果找不到就找IoU最大的,所以每个ground truth box只对应一个?
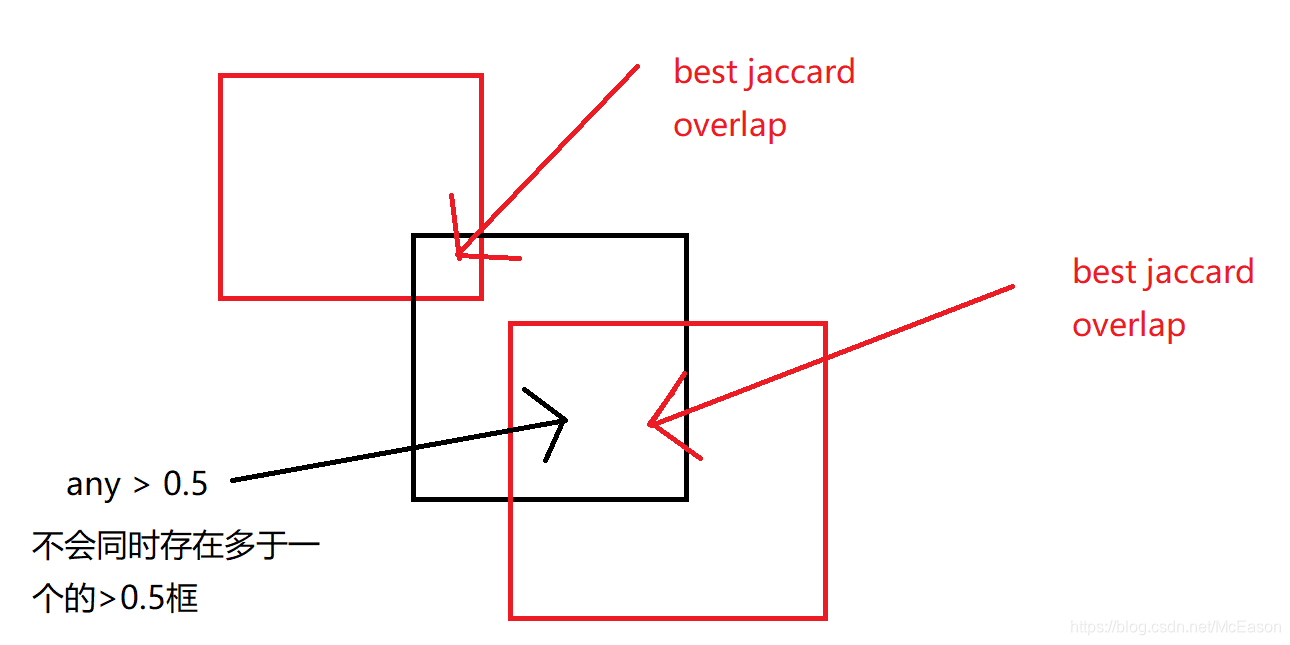
这样就能预测多个重叠框的高分。
4.负难例挖掘
原因:在一张图片中目标的个数一般不会太多,而在上述训练过程中,会产生8000多个初始框,所以能和真实目标框匹配的初始框非常少,这样导致正样本的个数远远小于负样本的个数,导致训练收敛困难。
方法:在匹配完之后,使用最高的置信度损失来对每个默认框进行排序,然后挑选其中的前几个负样本,让正负样本比例接近1:3.
5.计算损失函数
用
来表示,第
个默认框和第
个
类真实框的匹配指数。(如果该默认框可以和真实框进行匹配,那么就=1)
我们能得到
,损失函数是定位和置信度的损失和,如下:

是被匹配的默认框的数量,如果
,那么loss也是0。
用的是Smooth L1 loss,其中
是预测框的参数,
是真实框的参数。回归的是中心框相对于中心
的偏移还有他的宽和高
。

置信度损失是覆盖多个类的置信度(
)的softmax loss:

通过交叉验证被设为1。
作者Idea来源:
通过[Looking wider to see better]中,添加全局环境池化能对平滑和分割结果产生帮助,引发了作者的,即使用低层的特征也使用高层的特征来进行检测。
参考文章:
其他:
Atrous Convolution:使用的是VGG-16-atrous
jaccard
比较:
和Faster RCNN相比:
- SSD是多尺度的,在多个大小的特征图上进行检测,而Faster RCNN只用了一个,只有在anchor的设置上有多尺度概念。