CornerNet背景
当前one-stage和two-stage的目标检测state-of-the-art方法都是基于anchor,弊端:(1)大量的anchor框,正负样本不均衡,减慢训练速度。(2)需要超参和设计(多少anchor,尺寸,比例)
one-stage和two-stage的区别:
| - | one-stage | two-stage |
|---|---|---|
| 主要算法 | Yolov1、Yolov2、Yolov3、SSD、RetainNet | Fast R-CNN、Faster R-CNN、DeNet |
| 检测精度 | 较低 | 较高 |
| 检测速度 | 较快 | 较慢 |


CornerNet正文部分
我们的cornrtNet的论文中,有两个部分属于我们的创新点。
- 将目标检测问题当作关键点问题来解决,也就是通过检测目标框的左上角和右下角的两个关键点得到预测框,因此在CornerNet算法中没有anchor的概念
- 整个检测网络的训练是从头开始的,并不基于预训练的分类模型,这使得用户能够自由设计特征提取网络,不用受预训练模型的限制
我们之前的大多目标检测方法都是基于anchor进行的,比如FasterR-CNN、SSD、YOLO(v2、v3)等,引入anchor后,我们地目标检测效率有了明显地提高,但是同时因为anchor的引入,会带来一些缺点:
- 这样会导致我们算法的运算量过大,因为很多的算法都是成千上万的anchor,但是我们的需要检测的目标并没有这么多,因此会造成算法过多的冗余计算。所以有了focal loss 和对负样本做欠采样等算法来来解决这个问题。
- 引入更多的超参数,比如anchor的数量、长、宽、高等,因此这篇不采用anchor却能有不错效果的CornerNet就省去了这几个额外的操作。
CornerNet的网络结构

首先,通过一个7x7的卷积层,将输入图片尺寸缩小为原来的1/4(论文中输入的是511x511大小的图片,输出的是128x128大小的),之后进入backbone network提取特征,backbone network 采用的main network是 hourglasss network,而hourglass network由两个 hourglass module。每个module都是通过一些列的下采样操作输入图像的大小,然后通过上采样再降图像恢复到原来的大小。整个hourglass network的深度是104层。
hourglasss network之后会有两个输出分支,分别表示预测左上角预测和右下角预测分支,每个分支包含一个corner poolings和三个输出:heatmap、embedding、offsets。
heatmap:是输出预测角点信息,可以用维度为H x W的feature map,其中C表示目标的类别(注意:没有背景图)这个特征图的每个channel都是一个mask,mask的范围是0~1
embeddings:embeddings的主要作用是预测corner点做group,也就是说检测检测出的左上角和右下角是否是同一目标的。
offests:用来对预测框的位置进行微调,因为点映射到feature map时会有量化误差。
在我们的CornerNet算法中还有个相对比较创新的地方是我们在这个网络中用到的池化层~~Corner Pooling。
Corner Pooling:
Corner Pooling 的计算方式大致如下:


为什么我们在CornerNet网络中不使用我们常见的最大池化(max-pooling)和平均池化(mean-pooling)呢?
这是因为我们CornerNet网络的特殊性,我们的CornerNet主要检测的是我们的需要检测目标物体的左上角和右下角,如果使用平常的池化层,我们无法判断出检测物体的left-up corner,因此我们用corner pooling,得到的左上角的右边有检测物体的关键信息,而且左上角的右下方有检测物体的关键信息,因此就有了corner pooling。
corner pooling是怎么做的(左边池化:从右往左看,上边池化:从下往上看,右边池化:从左往右看,下边池化:从上往下看)
CornerNet中的数学公式
其中我们的L_{det}代表的是我们Heatmap的损失函数,我们的L__{det}具体的形式如下:
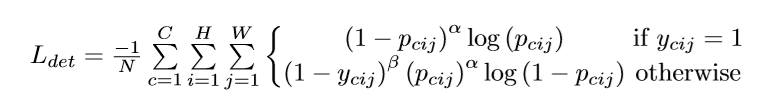
在公式中的N代表的是我们检测的物体个数,而P_{cij}是预测heatmap在第C个通道的(i,j)位置的值,而y__{cij}是我们的Gaus-sians Loss其值,其中的x和y表示以(i,j)为原点的相对位置的坐标。
L_{pull}的具体形式如下:
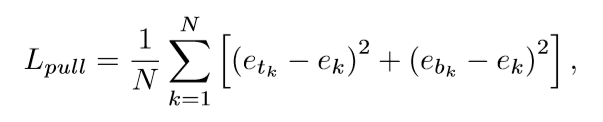
在公式中e_{tk}代表属于k类目标的左上角点的embedding vector,而e__{ek}属于k类目标的右下角点的embedding vector,而e_{k}是e_{tk}和e_{bk}的平均值。
L_{push}的具体形式如下:
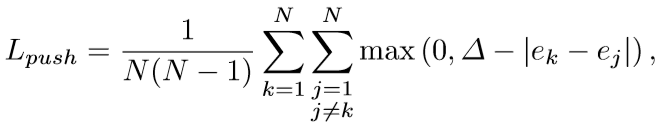
L_{push}的作用是用来扩大不属于同一目标的两角点的vector距离。
CornerNet的另一个输出的是offset,这个值和目标检测算法中预测的offset类似却完全不一样,说类似是因为都是偏置信息,说不一样是因为在目标检测算法中预测的offset是表示预测框和anchor之间的偏置,而这里的offset是表示在取整计算时丢失的精度信息,也就是公式2所表达的内容。
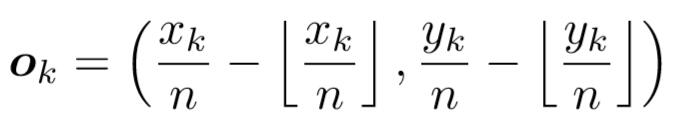
我们知道从输入图像到特征图之间会有尺寸缩小,假设缩小倍数是n,那么输入图像上的(x,y)点对应到特征图上就如下式子。
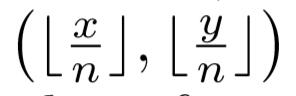
式子中的符号是向下取整,取整会带来精度丢失,这尤其影响小尺寸目标的回归,Faster RCNN中的 ROI Pooling也是有类似的精度丢失问题。所以通过公式2计算offset,然后通过公式3的smooth L1损失函数监督学习该参数,和常见的目标检测算法中的回归支路类似。
实验结果

Table1是关于conner pooling的对比实验,可以看出添加conner pooling(第二行)对效果的提升比较明显,这种提升尤其在目标尺度比较大的数据中表现明显。

Table2是关于对不同位置负样本采取不同权重的损失函数的效果。第一行是不采用这种策略的效果;第二行是采用固定半径值的效果,可以看出提升比较明显;第三行是采用基于目标计算得到的半径值的效果(这篇文章所采用的),效果得到进一步提升。
总结
我们已经介绍了CornerNet,这是一种新的目标检测方法,可以将边界框检测为成对的角点。 我们在MS COCO上对CornerNet进行评估,并展示出了有竞争力的结果。但是因为如此我们的预测的准确率也会因此下降。比如可能会把两个距离比较近的物体检测为一个物体而进行框选。如以下情况

针对此问题,又提出的了CenterNet的方法,在一定程度上减少了这种情况的发生。