版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
目录
- 表的物理存储方式
- 表的创建
- 表的修改
- 表的删除
- 临时表
表管理
数据被存储在不同功能的表中,查询围绕着这些表展开。
不能抛开表设计而单独讨论查询优化。eg.一个表的数据量非常大,则可以考虑将其分割为多个表存储,或使用分区表技术,而非完全依赖升级硬件和创建索引来解决。
逻辑上,表由行和列构成,且每列具有一个系统|自定义数据类型。
物理上,表具有两种存储单位:数据页和区。
- 数据页:最基本的数据存储单位
- 区:由八个物理上连续的数据页组成(管理数据页)
1.表的物理存储方式
1.1 数据页
表中每一行最多包含8060字节。如表中包含了text | image数据,当列超过此限制时,数据库引擎将把页中最大宽度的记录列移到另一页,在原始页上保留一个24字节的指针,指向实际存储位置。如后其更新操作使记录变短,记录可能会移回原始页。---- 摘,待验证
日志文件不包含页,而是包含一系列日志记录。

1.2 区
- 大小:64KB(8个物理上连续的页,16区/MB)
- 分类
- 统一区:由单个对象拥有,所有8页只能由一个对象使用。
- 混合区:最多由8个对象拥有,每页可由不同对象使用。
- 分配
- 通常从混合区向新表或索引分配页,当表增长到8页时,变成统一区进行后续分配。
- 如对现有表创建索引,且该表包含的行足以在索引中生成8页,则该索引直接使用统一区分配。
2.创建表
表名称在数据库的某个架构3中必须是唯一的。
2.1 创建表
-- 基本表
CREATE TABLE tt1
(
id INT,
name VARCHAR(20)
)
-- 约束
CREATE TABLE tt2
(
id INT IDENTITY(1, 1) PRIMARY KEY -- 自增主键
name VARCHAR(20) NOT NULL -- 不允许空值
GUID uniqueidentifier DEFAULT NEWID() -- 全球唯一标识符NEWID() | 默认值DEFAULT
)
3.修改表
-- 增加列
ALTER TABLE tt1
ADD sex VARCHAR(10) NOT NULL
-- 修改列
-- 语法
-- changing any part of an object name could break scripts and PROC
sp_rename ’object_name‘, 'new_name', ‘object_type'
-- 列
EXEC sp_rename 'tt1.sex', 'gender', 'COLUMN'
-- 修改列的数据类型
ALTER TABLE tt1 ALTER COLUMN gender VARCHAR(15) NOT NULL -- 列的大小要合适,否则数据会被截断
ALTER TABLE tt1 ALTER COLUMN gender CHAR(10) NOT NULL
ALTER TABLE tt1 ALTER COLUMN gender CHAR(10) -- 改为可为空应考虑其它约束
注:删除列之前,必须先删除任何引用该列的约束、默认值表达式、计算列表达式或索引。
-- 删除列
-- 检查表中所有约束
EXEC sp_help tt1
-- 删除约束
ALTER TABLE tt1
DROP CONSTRAINT 约束名
-- 删除列
ALTER TABLE tt1
DROP COLUMN gender
-- 删除表内容,保留表结构
DELETE FROM tt1
TRUNCATE TABLE tt1 -- 推荐,效率更佳,资源占用更少
4.删除表
必须先删除FOREIGN KEY约束或引用表。
-- 重命名
-- changing any part of an object name could break scripts and PROC
EXEC sp_rename 'tt1', 'tt'
-- 删除表
DROP TABLE tt
5.临时表
永久表存储在它所创建的数据库中,临时表存储在tempdb数据库中。临时表支持除FERGIN KEY约束以外的所有约束定义。
应用场景:当必须对临时表显示地创建索引,或多个存储过程,或函数必须使用表值时,临时表很有用。
临时表分为本地表和全局表两种类型:
- 本地表:单个数字符号(#)打头,仅当前用户可见,当用户从服务器断开连接时被删除
- 全局表:两个数字符号(##)打头,创建后所有用户可见,当所有引用该表的用户从服务器断开时被删除。

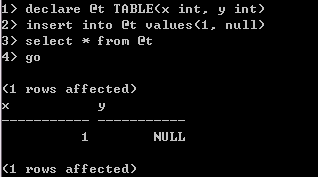
表变量也是一种临时表。同时,表变量类似于局部变量,有明确的作用域,即声明该变量的函数、存储过程或批处理。
6.问
6.1 索引和表可以分开存储么?
可以,但不建议。
如果是聚簇索引,该索引本身就是数据以某值的排序,是不能分离的.
其次,哪怕是非聚簇索引,索引本身是为了提高查询速度,只有同数据放在一起才能最大的提高查询速度,分离无论如何怎么都会大大降低效率 — ?待验证.