目录
- 合并结果集
- 查询结果集的差异行
- 查询结果集的相同行
- 优先级(INTERSECT > UNION = EXCEPT
- 公用表表达式(CTE)
- 汇总数据(CUBE, ROLLUP, GROUPING)
联接操作无论多么复杂,都被看作一条查询语句。
对结果集的操作则是对至少两条查询语句的结果再次整合。要求:两个结果集的列数相同,列的顺序相同,且相应列的数据类型也应当相同,或能隐式转换。
喻:联接操作是对两个表进行横向结合,结果集操作是对两个表纵向结合。
1.合并结果集
一个SQL语句可以出现任意数目的UNION运算符。
保留第1个SELECT语句的结果集的列名。
-- UNION 删除重复行
-- UNION ALL 保留重复行
selete_statement UNION [ALL] select_statement
IF DB_ID('tt') IS NOT NULL
DROP DATABASE tt
GO
CREATE DATABASE tt
GO
IF OBJECT_ID('tt.dbo.T1') IS NOT NULL
DROP TABLE T1
IF OBJECT_ID('tt.dbo.T2') IS NOT NULL
DROP TABLE T2
GO
CREATE TABLE tt.dbo.T1
(
A int,
B char(5),
C char(4)
)
CREATE TABLE tt.dbo.T2
(
A char(4),
B decimal(5, 4)
)
GO
INSERT INTO tt.dbo.T1
VALUES
(1, 'ABC', 'JKL'), (2, 'DEF', 'MNO'), (3, 'GHI', 'PQR')
INSERT INTO tt.dbo.T2
VALUES
('JKL', 1.000), ('DEF', 2.000), ('MNO', 5.000)
GO
SELECT A, B FROM tt.dbo.T1
UNION
SELECT B, A FROM tt.dbo.T2
GO
-- 在UNION运算符中
-- ORDER BY 作用于第1个结果集的列名
SELECT A, B FROM tt.dbo.T1
UNION
SELECT B, A FROM tt.dbo.T2
ORDER BY A
-- 在ORDER BY中
-- 其它逻辑处理需要要ORDER BY之前
SELECT A, B FROM tt.dbo.T1
WHERE B <> 'ABC'
UNION
SELECT B, A FROM tt.dbo.T2
WHERE A <> 'DEF'
ORDER BY A
GO
-- 合并顺序
-- 一般中从左到右依次(上下),可使用圆括号'()'改变运算顺序
-- 加上括号后,先T2,T3,后T1
SELECT * FROM T1
UNION ALL
(SELECT * FROM T2
UNION
SELECT * FROM T3)
2.查询结果集的差异行
EXCEPT运算符。
返回上表中,与下表的差异行,去重。从上到下(左右)运算,返回上侧表中含有,但下侧表中没有有结果集。

- 全部差异行
❶是否存在(NULL),❷左侧查询与右侧查询中重复行的次数
+NULL,不去重
注:“三值逻辑”。
-- ROW_NUMBER() 辅助列
IF DB_ID('tt') IS NOT NULL
DROP DATABASE tt
GO
CREATE DATABASE tt
GO
IF OBJECT_ID('tt.dbo.T1') IS NOT NULL
DROP TABLE T1
IF OBJECT_ID('tt.dbo.T2') IS NOT NULL
DROP TABLE T2
GO
CREATE TABLE tt.dbo.T1
(
A int
)
CREATE TABLE tt.dbo.T2
(
A int
)
GO
INSERT INTO tt.dbo.T1
VALUES
(NULL), (NULL), (NULL), (1), (2), (3), (3), (4), (4), (4)
INSERT INTO tt.dbo.T2
VALUES
(NULL), (2), (3), (3), (4)
GO
SELECT A FROM tt.dbo.T1
SELECT A FROM tt.dbo.T2
GO
-- 除NULL,去重
SELECT A FROM tt.dbo.T1
EXCEPT
SELECT A FROM tt.dbo.T2
GO
-- +NULL,不去重
SELECT A
FROM (
SELECT ROW_NUMBER() OVER(PARTITION BY A ORDER BY A) rn
, A
FROM tt.dbo.T1
EXCEPT
SELECT ROW_NUMBER() OVER(PARTITION BY A ORDER BY A) rn
, A
FROM tt.dbo.T2
) T

3.查询结果集的相同行
INTERSECT运算符
返回左右表都存在的行,去重
SELECT A FROM tt.dbo.T1
INTERSECT
SELECT A FROM tt.dbo.T2

- 查询全部相同行
+NULL,不去重
-- 辅助行 ROW_NUMBER() OVER()
SELECT A FROM tt.dbo.T1
SELECT A FROM tt.dbo.T2
GO
-- 去重
SELECT A FROM tt.dbo.T1
INTERSECT
SELECT A FROM tt.dbo.T2
GO
-- 不去重
SELECT A
, ROW_NUMBER() OVER(PARTITION BY A ORDER BY A) rn
FROM tt.dbo.T1
INTERSECT
SELECT A
, ROW_NUMBER() OVER(PARTITION BY A ORDER BY A) rn
FROM tt.dbo.T2
GO

4.优先级
INTERSECT > UNION = EXCEPT, 如果有圆括号,先执行圆括号()内的语句
5.公用表表达式(Common Table Expression, CTE)
临时(#)结果集
可调用自身,实现递归,可以同一查询中引用多次
5.1 语法
-- CTE表达式的名称 cte_name
-- 列列表 col_name [, ...n]
-- 创建临时结果集的查询语句 cte_query_definition
WITH cte_name [ ( col_name [, ...n] ) ]
AS
( cte_query_definition )
5.2 创建
CTE后必须跟随引用部分或单条SELECT、INSERT、UPDATE或DELETE语句,CTE仅对该语句可见。
- CTE中不能再嵌套CTE
- cte_query_definition中不能使用
1.ORDER BY(当指定了TOP子名时,可以)
2.INTO
3.带查询提示的OPTION子句1
注:对于非计算列,列名称的定义可以完全省略。计算列必须在开头或查询定义部分指定别名。
5.2.1 单CTE
WITH cte_t1
AS
(
SELECT A FROM tt.dbo.T1
UNION
SELECT A FROM tt.dbo.T2
)
SELECT * FROM cte_t1
GO
CREATE TABLE tt.dbo.sale
(
id int,
name varchar(20),
dat datetime
)
insert into tt.dbo.sale
values
(1, 'H', '2019-10-10'), (2, 'S', '2019-10-22')
GO
select * from tt.dbo.sale
go
with cte_sal
as
(
select * from tt.dbo.sale
)
select * from cte_sal
go
with cte_sal1 (dd, nn)
as
(
select id, name from tt.dbo.sale
)
select * from cte_sal1
go
with cte_sal2(id, Y, C)
as
(
select id, YEAR(dat) year_, COUNT(id) cnt
from tt.dbo.sale
group by id, YEAR(dat)
)
select * from cte_sal2
5.2.2 多CTE定义和CTE多次引用
WITH子句中可同时定义多个CTE
eg.1 多CTE定义
with cte_sal2 as
(
select id, YEAR(dat) year_, COUNT(id) cnt
from tt.dbo.sale
group by id, YEAR(dat)
), -- 逗号分隔即可
cte_sal3 as
(
select year_, COUNT(cnt) Cnt
from cte_sal2
group by year_
)
select * from cte_sal3
eg.2 CTE多次引用
-- 派生表
use [Account Management]
go
SELECT Cur.Mon AS CurMon
, Prv.Mon AS PrvMon
, Cur.Spending AS CurSpending
, Cur.Spending - Prv.Spending AS Diff
FROM
(
SELECT MONTH(日期) AS Mon
, SUM(金额) AS Spending
FROM 消费
GROUP BY MONTH(日期)) AS Cur
LEFT JOIN
(
SELECT MONTH(日期) AS Mon
, SUM(金额) AS Spending
FROM 消费
GROUP BY MONTH(日期)) AS Prv
ON Cur.Mon = Prv.Mon + 1
ORDER BY CurMon
GO
-- 等价
-- CTE 多次引用
WITH cte_MonDiff AS
(
SELECT MONTH(日期) AS Mon
, SUM(金额) AS Spending
FROM 消费
GROUP BY MONTH(日期)
)
SELECT Cur.Mon AS CurMon
, Prv.Mon AS PrvMon
, Cur.Spending AS CurSpending
, Cur.Spending - Prv.Spending AS Diff
FROM cte_MonDiff Cur
LEFT JOIN cte_MonDiff Prv
ON Cur.Mon = Prv.Mon + 1
ORDER BY CurMon
GO
5.2.3 CTE间接嵌套
由于不能直接嵌套,但可以通过在视图、用户定义函数(UDF)中定义CTE的方式
(就是找个临时存储空间将数据存储起来,感觉间接嵌套实用意义不大,快消是CTE的优点,没必要补足)
-- 通过VIEW间接实现
--
use [Account Management]
go
CREATE VIEW v_Mon
AS
WITH cte_mon AS
(
SELECT MONTH(日期) AS Mon
, SUM(金额) AS Spending
FROM 消费
GROUP BY MONTH(日期)
)
SELECT * FROM cte_mon
GO
WITH cte_MOM AS
(
SELECT Cur.Mon AS CurMon
, Prv.Mon AS PrvMon
, Cur.Spending AS CurSpending
, Cur.Spending - Prv.Spending AS Diff
FROM v_Mon Cur
LEFT JOIN v_Mon Prv
ON Cur.Mon = Prv.Mon + 1
)
SELECT *
FROM cte_MOM
ORDER BY CurMon
GO
DROP VIEW v_Mon -- 删除演示数据
-- 通过UDF
--
CREATE FUNCTION dbo.fn_query(@class varchar(20))
RETURNS TABLE
AS
RETURN
WITH cte_m AS
(
SELECT MONTH(日期) AS Mon
, SUM(金额) AS Spending
FROM 消费
WHERE 类别 = @class
GROUP BY MONTH(日期)
)
SELECT * FROM cte_m
GO
select * from sysobjects where xtype not in ('S', 'IT', 'SQ', 'U', 'V', 'P', 'PK')
GO
WITH cteMonDiff AS
(
SELECT Cur.Mon AS CurMon
, Prv.Mon AS PrvMon
, Cur.Spending AS CurSpending
, Cur.Spending - Prv.Spending AS MonDiff
FROM dbo.fn_query('总点击') AS Cur
LEFT JOIN dbo.fn_query('总点击') AS Prv
ON Cur.Mon = Prv.Mon + 1
)
SELECT *
FROM cteMonDiff
ORDER BY CurMon
GO
DROP FUNCTION dbo.fn_query
GO
5.2.4 递归CTE
重复执行初始CTE返回数据子集,直到获取完整结果集的公用表表达式。
递归查询,即当查询引用递归CTE。用于返回分层数据。
了解即可
USE master
GO
IF DB_ID('tt') IS NOT NULL
DROP DATABASE tt
GO
CREATE DATABASE tt
GO
CREATE TABLE tt.dbo.Emp
(
emp_id int,
manager_id int,
emp_name varchar(50),
salary money
)
INSERT INTO tt.dbo.Emp
VALUES
(1, NULL, 'A1', 10000.00), (2, 1, 'B1', 9000.00),
(3, 1, 'B2', 9000.00), (4, 2, 'C1', 8000.00),
(5, 2, 'C2', 8000.00), (6, 3, 'C3', 8000.00)
GO
SELECT * FROM tt.dbo.Emp
GO
WITH etc_DR AS
(
-- 定位点成员 --必须,至少1个
SELECT manager_id, emp_id, emp_name, 0 AS level
FROM tt.dbo.Emp
WHERE manager_id IS NULL
UNION ALL -- 必须,连接定位点成员与递归组成员
-- 递归成员 -- 必须,只有1个
SELECT e.manager_id, e.emp_id, e.emp_name, level + 1
FROM tt.dbo.Emp AS e
INNER JOIN etc_DR AS d
ON e.manager_id = d.emp_id
)
-- 执行CTE
SELECT * FROM etc_DR
-- WHERE level < 2
-- OPTION(MAXRECURSION 3) -- 默认100,限制递归调用次数
GO
6.汇总数据
当需要统计分析的列较多时,单纯使用GROUP BY会非常繁琐。且多次聚合计算不仅增加了往返查询的次数,同时增加了系统负担。
GROUP BY增加了CUBE和ROLLUP参数。
- CUBE运算符
基于要分析的数据列建立结果集(多维数据集)
CREATE TABLE tt.dbo.voc
(
item varchar(20),
color varchar(20),
quantity int
)
INSERT INTO tt.dbo.voc
VALUES
('Chair', 'blue', 1), ('Chair', 'blue', 2),
('Chair', 'red', 3), ('yizi', 'red', 1),
('yizi', 'blue', 6)
GO
SELECT * FROM tt.dbo.voc
GO
SELECT item
, color
, SUM(quantity) AS Qt
FROM tt.dbo.voc
GROUP BY CUBE(item, color) -- CUBE 所选中列中值的所有组合的聚合
GO
select item
, color
, sum(quantity) as qtsum
from tt.dbo.voc
group by item, color -- vs
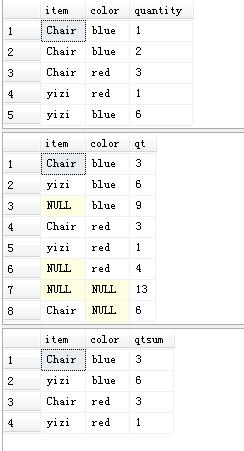
- ROLLUP运算符
返回当前粒度及其以下级别的聚合
-- 返回 item | item + color
-- 不会再有次一粒度的color
select item
, color
, SUM(quantity) as Qt_sum
from tt.dbo.voc
group by rollup(item, color)
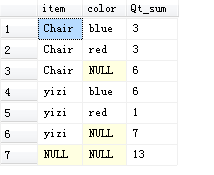
- GROUPING函数(区分空值&汇总值)
用于区分ROLLUP | CUBE | GROUPING SETS产生的空值与标准空值。如果列值来自实际数,则返回0;如果列值来自CUBE | ROLLUP | GROUPING SETS操作则生成NULL,返回1.
-- 区分事实数据产生的NULL & CUBE|ROLLUP产生的NULL
SELECT CASE
WHEN (GROUPING(item) = 1) THEN '汇总' -- CUBE|ROLLUP NULL
ELSE ISNULL(item, '未知') -- 事实数据 NULL
END AS item
, CASE
WHEN (GROUPING(color) = 1) THEN '汇总'
ELSE ISNULL(color, '未知')
END AS color
, SUM(quantity) as Qt_sum
FROM tt.dbo.voc
GROUP BY CUBE(item, color)
--HAVING item = 'Chair'
-- AND color IS NULL
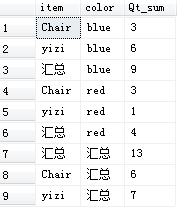
- GROUPING SETS
书中这点没讲清楚,查看官网资料补充。
GROUPING SETS选项使您能够将多个GROUP BY子句组合为一个GROUP BY子句。结果等于指定组的UNION ALL。
例如,GROUP BY ROLLUP (Country, Region)&GROUP BY GROUPING SETS ( ROLLUP (Country, Region) )返回相同的结果。
当GROUPING SETS具有两个或多个元素时,结果是元素的并集
SQL不会合并为GROUPING SETS列表生成的重复组。例如,在中GROUP BY ( (), CUBE (Country, Region) ),两个元素都返回总计的一行,并且这两行将在结果中列出。
-- 返回相同的结果
SELECT item
, color
, SUM(quantity) AS Qt_sum
FROM tt.dbo.voc
GROUP BY CUBE(item, color)
GO
SELECT item
, color
, SUM(quantity) AS Qt_sum
FROM tt.dbo.voc
GROUP BY GROUPING SETS(CUBE(item, color))
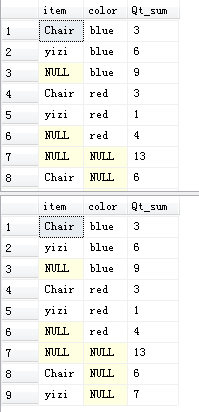
7.其它
7.1 在其它语句中使用UNION、EXCEPT、INTERSECT语句限制
- 第1个SELECT语句中可以包含一个INTO子句1,保存结果集,其它不可
- GROUP BY和HAVING子句只能在各个子句中起作用
7.2 突破结果集操作限制
通过临时表、派生表2、辅助列、公用表表达式(CTE)来过渡