依赖关系
rdd ==> transformation s ==> action
就是rdd经过一系列的转换 最后触发action
eg:
textFile(path) ==> map ==> filter ==> ... ==> collect
每一步转换都会形成一个rdd
RDDA RDDB RDDC
eg:
一个rdd 三个分区 经过一个map之后 分区不会发生变化的 再filter 分区也是三个
注意:
1.你对rdd做一个map操作 其实是对rdd内部的所有数据做map操作 ----RDD篇
2.窄依赖操作 默认不会造成分区的个数发生变化
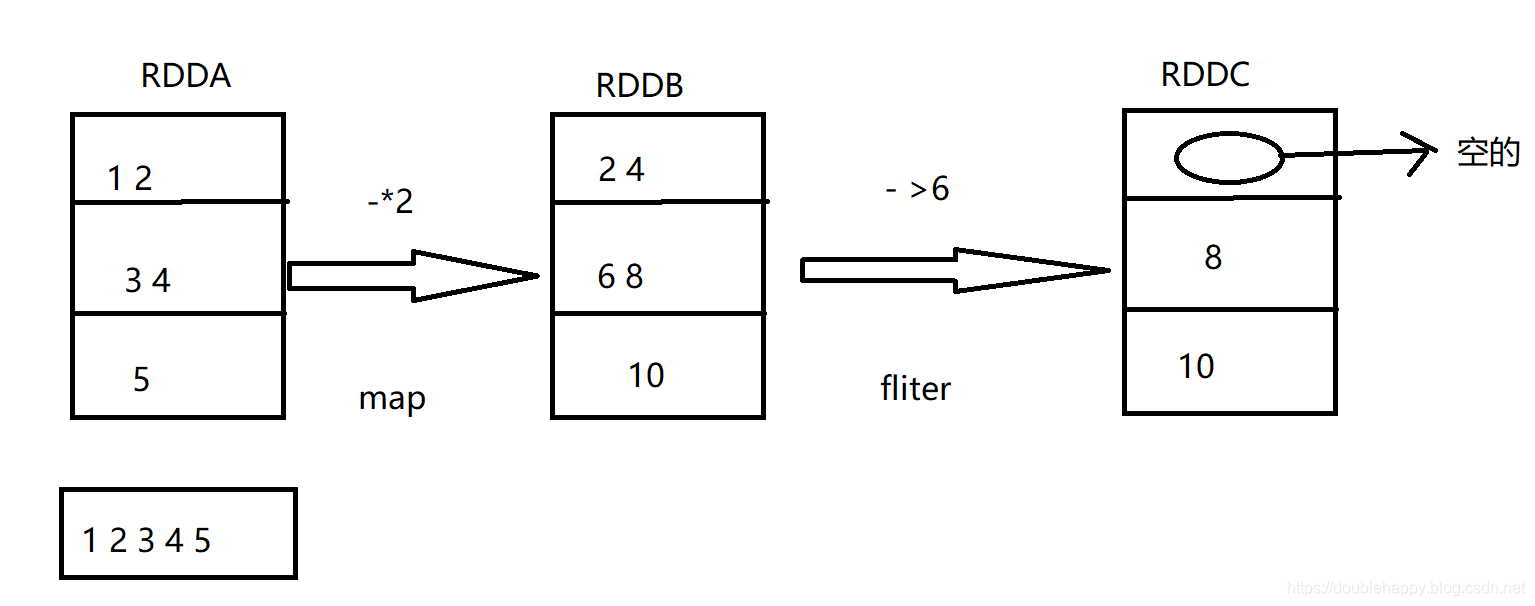
对于这个场景他们之间是有一个依赖关系的
注意:
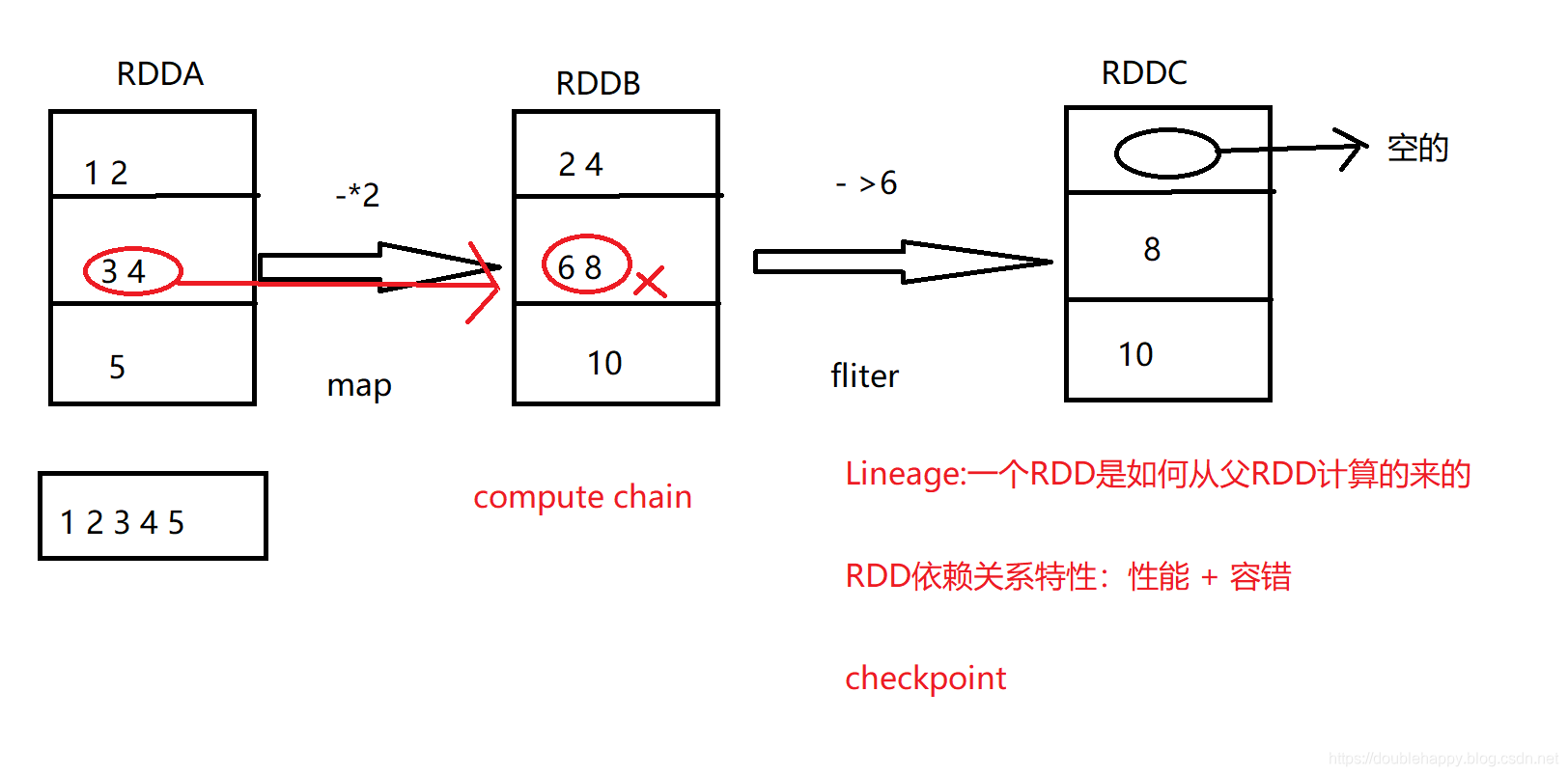
1.假如说 RDDB 分区里 6,8 这元素在计算的时候挂了
那么spark再重新计算的时候 它只需要重新计算这一个分区就可以了
2.这个分区里的数据怎么来的呢?
直接从上一个rddA分区 里拿过来 计算就可以 其他分区不会做处理 所以这里面存在依赖关系的
3.6和8这个元素的这个分区 到底从RDDA的哪一个分区过来的
这个是必然知道的 再spark里叫Lineage
4.Lineage : 一个rdd 是如何从父RDD计算的来的
5.RDD里的五大特性的其中一个特性 是可以得到依赖关系的
eg:因为你每次transformation的时候会把这个依赖关系记录下来的 这样就知道父rdd是谁
就是自己数据坏了 去爸爸那计算恢复 总有源头可以计算恢复
这个机制
就是Spark性能高的一个非常重要的原因
6. 性能 + 容错 (容错也体现在 数据坏了 重新算一下就ok)
7. 整个过程就是一个计算链
8. 如果转换非常多
eg:
这一个链路 100个转换 算到第99个数据坏了 ,如果要重头算 也是挺麻烦的一件事
core里面 提供 checkpoint(根本用不到 了解即可)
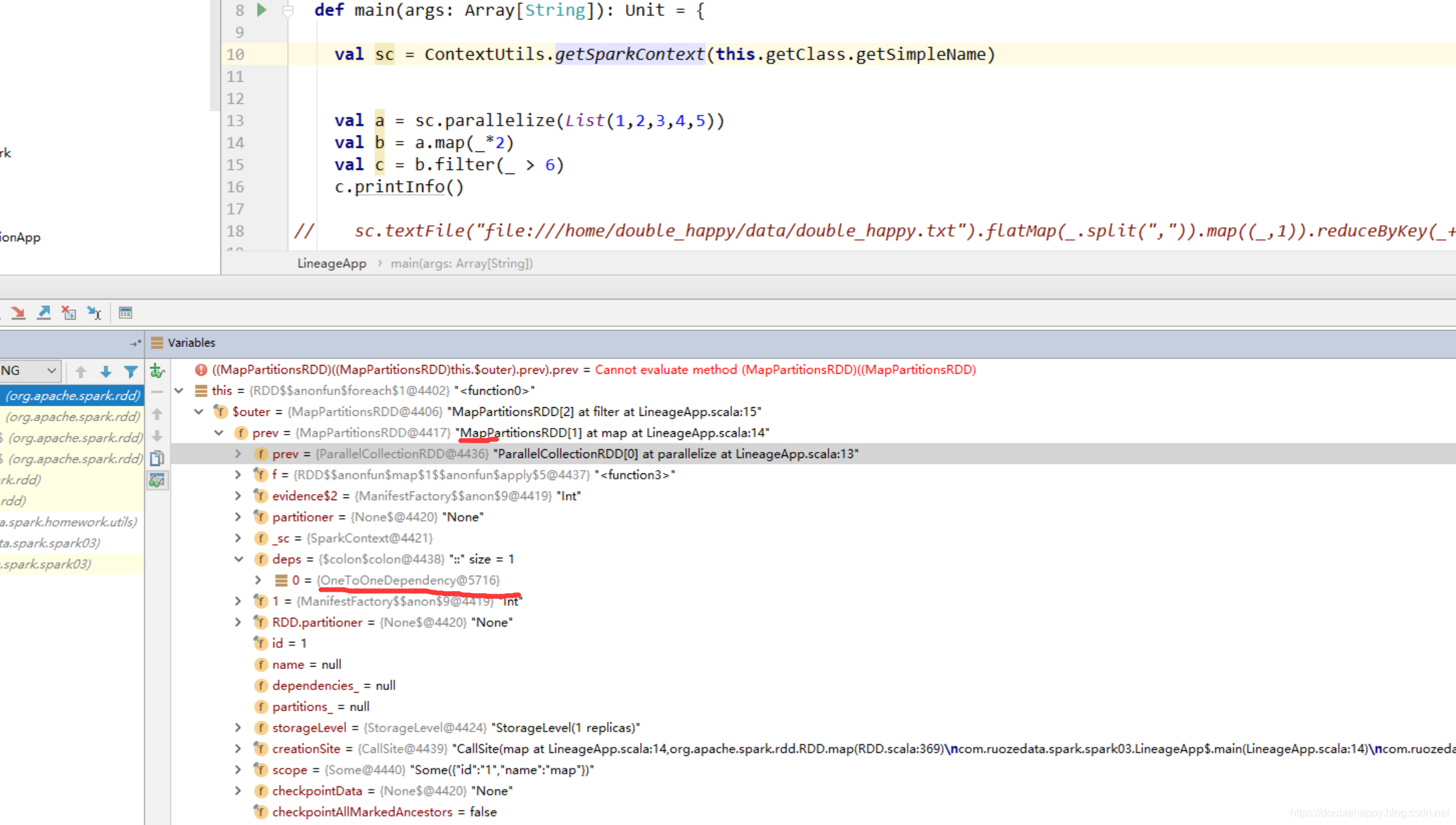
(1)idea中debug是可以看到依赖关系的
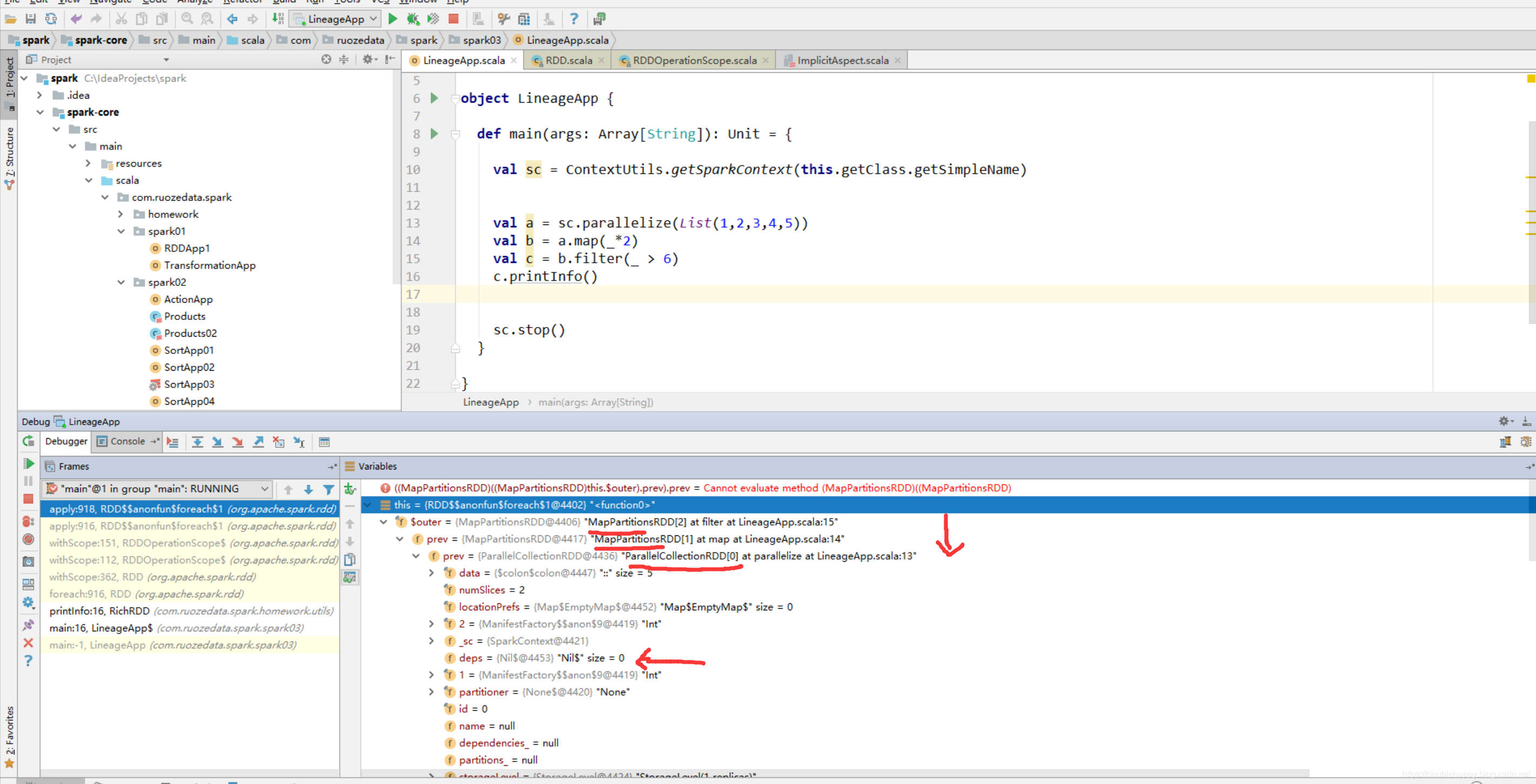
所以整个过程中 你的RDD是怎么来的 spark是知道的
(2) spark-shell中
scala> val a = sc.parallelize(List(1,2,3,4,5))
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val b = a.map(_*2)
b: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:25
scala> val c = b.filter(_ > 6)
c: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at filter at <console>:25
scala> c.collect
res0: Array[Int] = Array(8, 10)
scala>
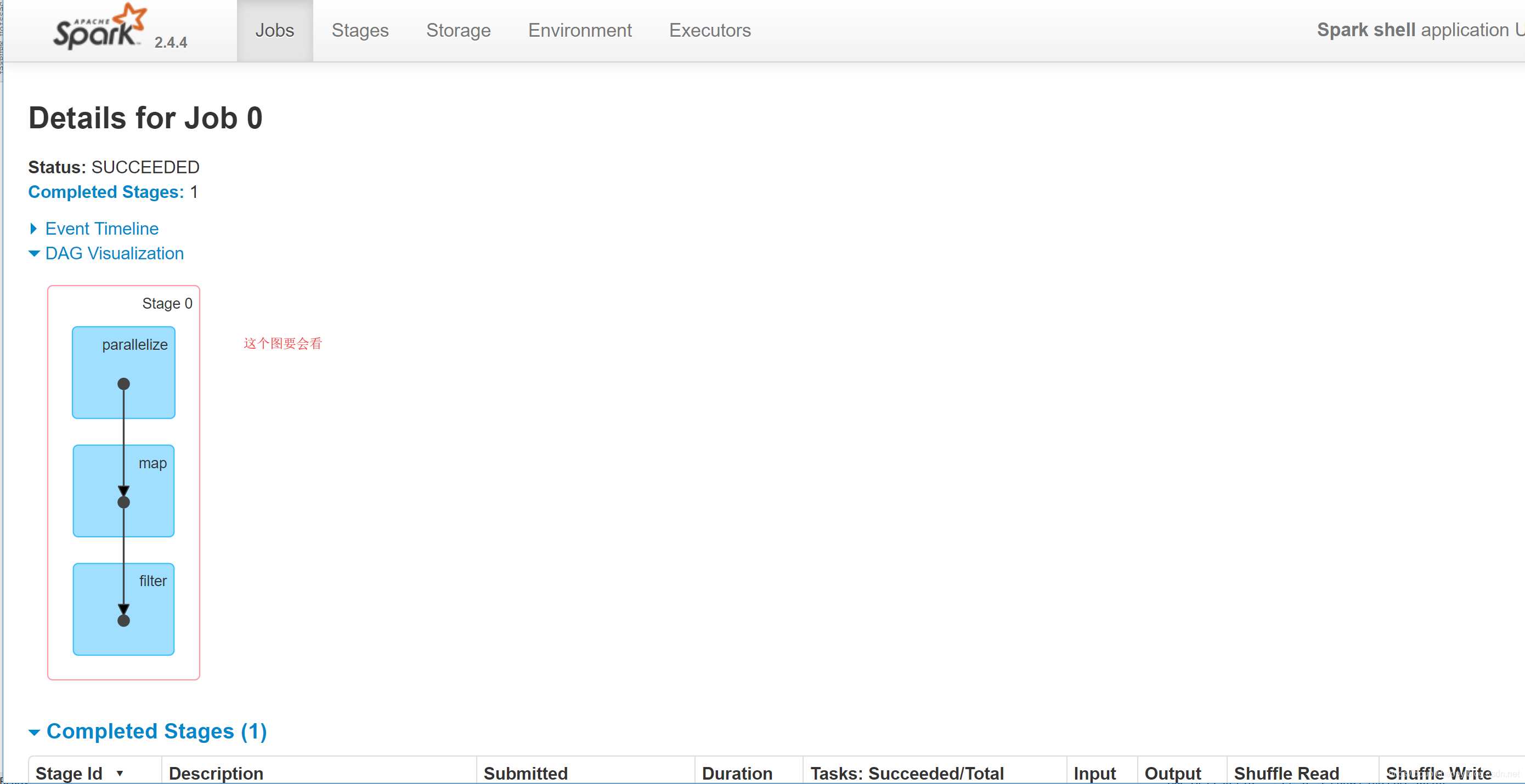
那么这个过程中到底产生多少个RDD呢?
scala> c.collect
res0: Array[Int] = Array(8, 10)
scala> c.toDebugString
res1: String =
(2) MapPartitionsRDD[2] at filter at <console>:25 []
| MapPartitionsRDD[1] at map at <console>:25 []
| ParallelCollectionRDD[0] at parallelize at <console>:24 []
注意:
parallelize --》ParallelCollectionRDD
map --》MapPartitionsRDD
filter ---》MapPartitionsRDD
那么这几个东西哪里来的呢?看源码
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
parallelize 返回的是一个RDD 而真正的类型是 ParallelCollectionRDD 其他同理
textFile
sc.textFile() 这一个过程产生多少个RDD呢?
scala> sc.textFile("file:///home/double_happy/data/double_happy.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).collect()
res2: Array[(String, Int)] = Array((xx,2), (aa,1), (flink,1), (jj,1), (rr,1), (spark,1), (flume,1), (ruozedata,1), (nihao,1))
scala>
结果出来了 到页面上看一下。
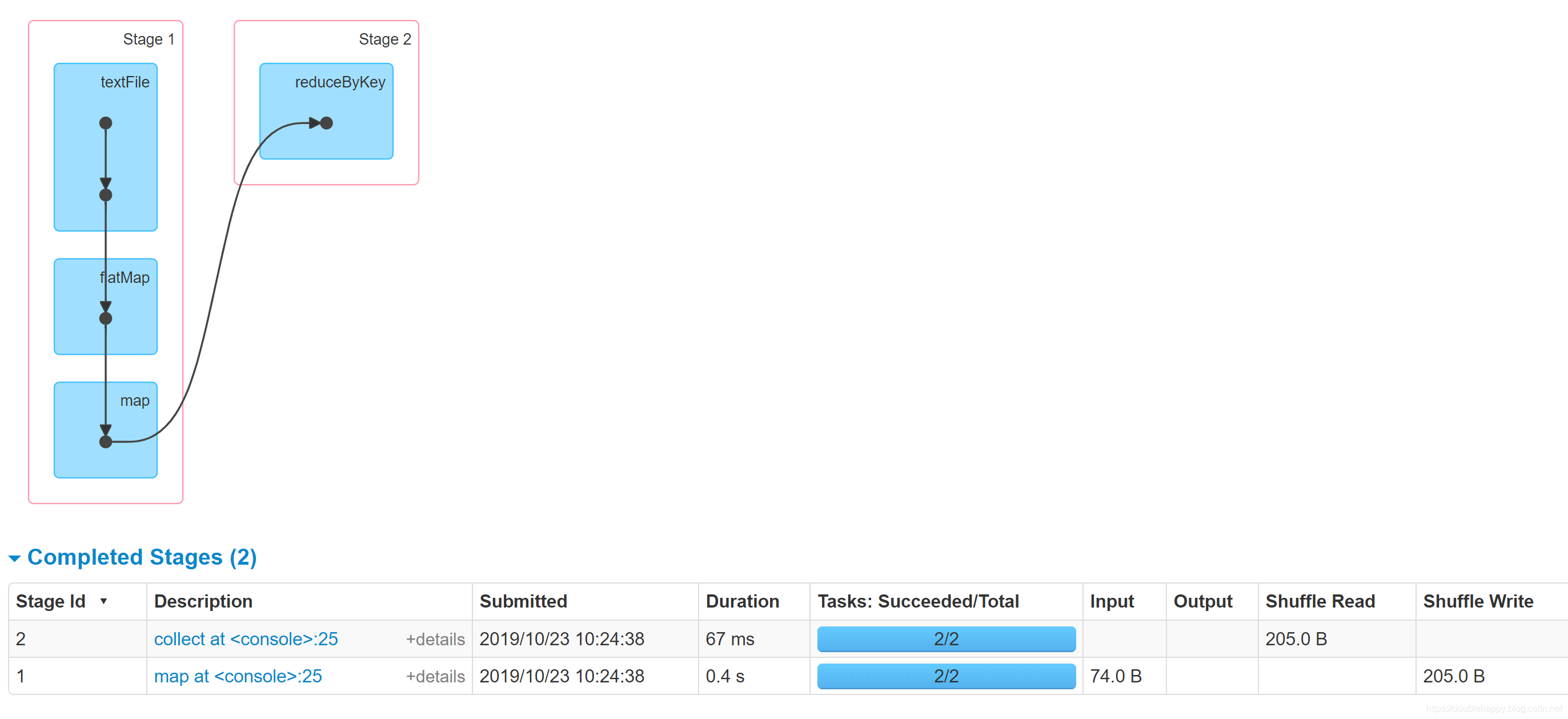
这个过程产生了多少rdd呢?
scala> sc.textFile("file:///home/double_happy/data/double_happy.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).toDebugString
res3: String =
(2) ShuffledRDD[12] at reduceByKey at <console>:25 []
+-(2) MapPartitionsRDD[11] at map at <console>:25 []
| MapPartitionsRDD[10] at flatMap at <console>:25 []
| file:///home/double_happy/data/double_happy.txt MapPartitionsRDD[9] at textFile at <console>:25 []
| file:///home/double_happy/data/double_happy.txt HadoopRDD[8] at textFile at <console>:25 []
scala>
注意:
textFile : HadoopRDD + MapPartitionsRDD
flatMap : MapPartitionsRDD
map : MapPartitionsRDD
reduceByKey : ShuffledRDD
textFile 过程:
1.textFile
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
2.hadoopFile
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)]
hadoopFile 我没用拷贝全 但是足够了 返回值是一个 kv类型的 真正的返回的是HadoopRDD
3.hadoopFile 就是 mapreduce里的 读取文本文件的mapper过程
通过:mapper
TextInputFormat
mapper: LongWritable(每行数据的偏移量) Text(每行数据的内容)
那么 RDD[(K, V) 就是 (偏移量,Text)
4.
hadoopFile(path, classOf[TextInputFormat],
classOf[LongWritable], classOf[Text],
minPartitions)
.map(pair => pair._2.toString).setName(path)
这个HadoopRDD 之后的map操作 所以会产生MapPartitionsRDD
map(pair => pair._2.toString).setName(path)
就是把读取的内容拿出来
注意:
rdd里的分区数据对应hdfs上一个文件有多少个block
所以HadoopRDD底层实现可以去看一下
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
// add the credentials here as this can be called before SparkContext initialized
SparkHadoopUtil.get.addCredentials(jobConf)
val inputFormat = getInputFormat(jobConf)
val inputSplits = inputFormat.getSplits(jobConf, minPartitions)
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) {
array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
}
getInputFormat(jobConf).getSplits(jobConf, minPartitions) 明白了吗
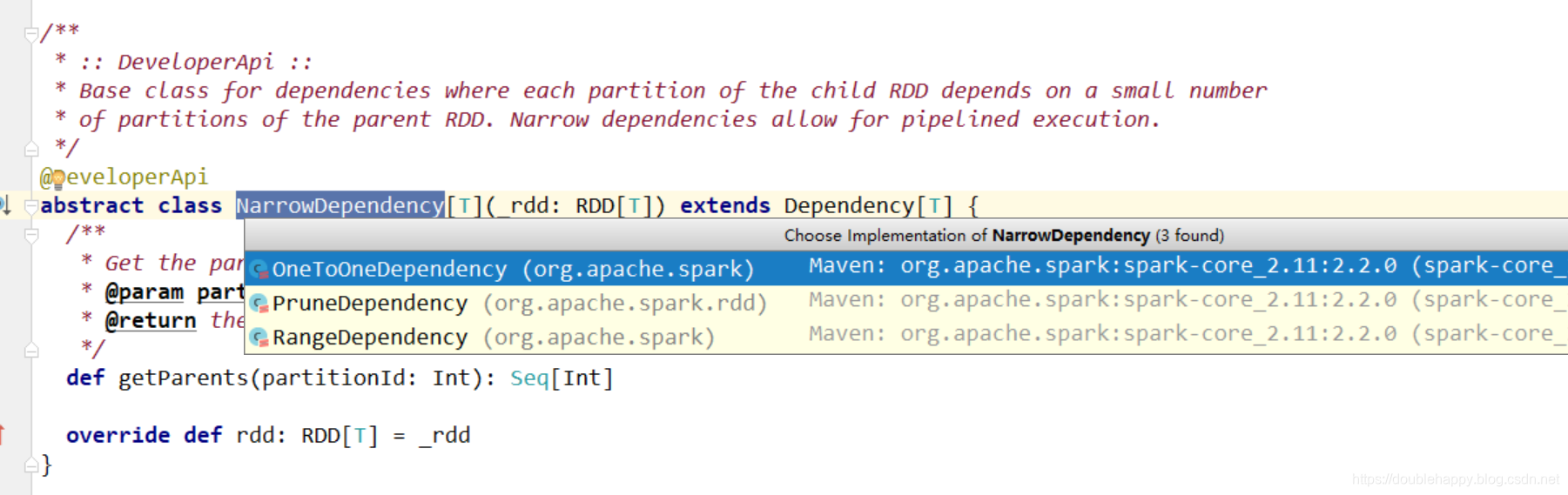
Dependency
窄依赖
一个父RDD的partition至多被子RDD的partition使用一次
OneToOneDependency
都在一个stage中完成
宽依赖 <= 会产生shuffle 会有新的stage
一个父RDD的partition会被子RDD的partition使用多次
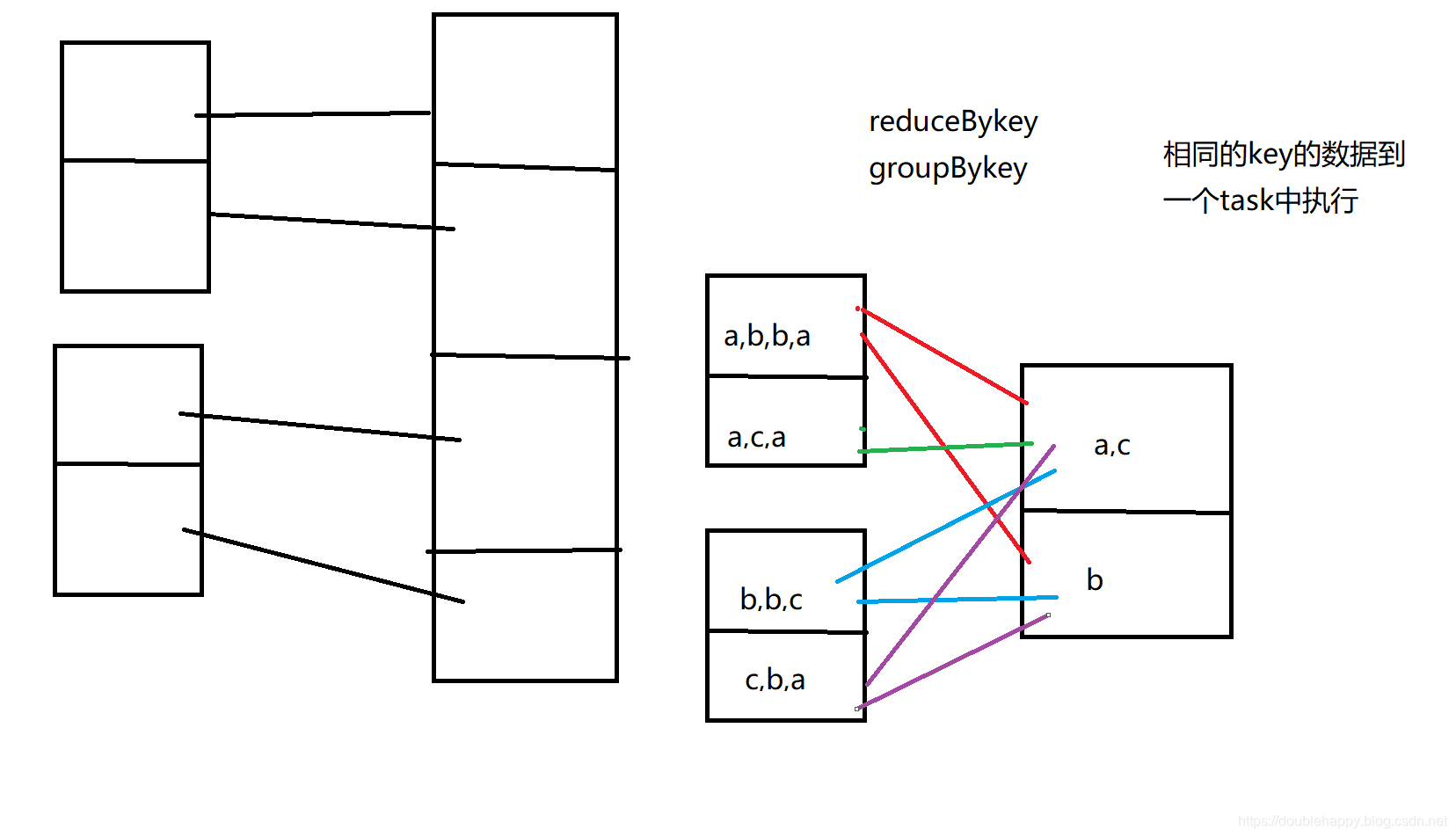
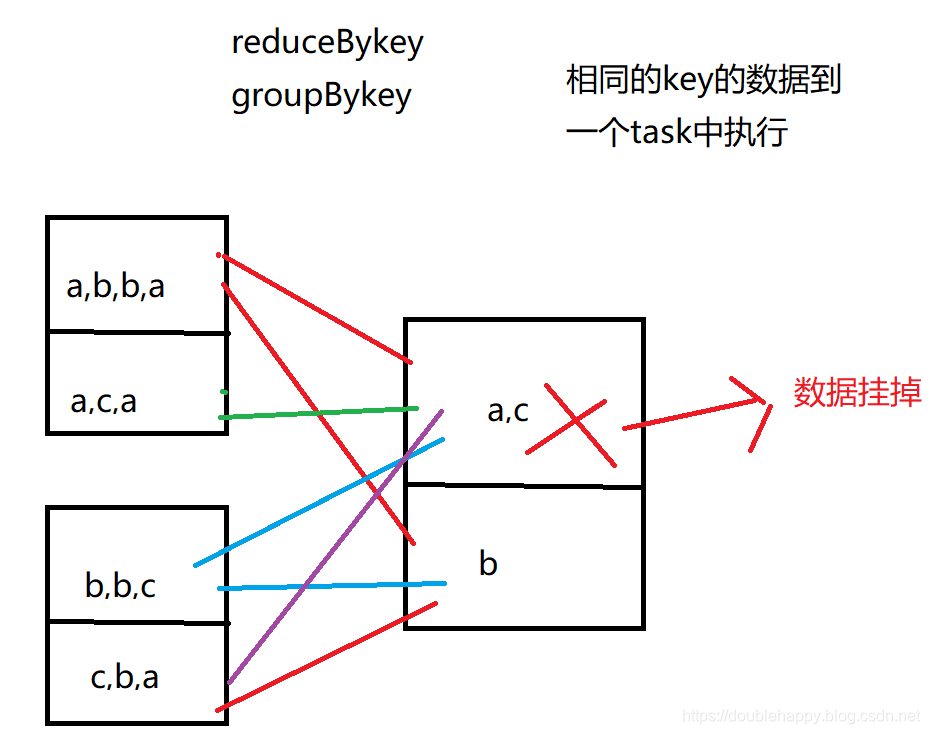
如果经过宽依赖之后的RDD的某一个分区数据挂掉
需要去父RDD重新计算 会把父亲所有分区都会算一下才行
注意:
1.所有分区都要重算
从容错的角度来说,在开发过程,能使用窄依赖就使用窄依赖 emm这就话 不全对
在某些情况下 会把窄依赖改成宽依赖 来实现。
解析wc过程
val lines = sc.textFile("file:///home/double_happy/data/double_happy.txt")
val words = lines.flatMap(_.split(","))
val pair = words.map((_,1))
val result = pair.reduceByKey(_+_)
result.collect()
为什么会多一个conbine操作呢?
reduceBykey算子底层封装好的
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
combineByKeyWithClassTag中的 mapSideCombine: Boolean = true
map端输出 设置Combine为true
reduceBykey这个算子有Combine,那么groupBykey算子有么?
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
mapSideCombine = false
注意:
reduceByKey
有map端输出预聚合功能的
groupBykey
全数据shuffle的 ,没有预聚合
shuffle operations
The shuffle is Spark’s mechanism for re-distributing data so that it’s grouped differently across partitions. This typically involves copying data across executors and machines, making the shuffle a complex and costly operation.
re-distributing data:
数据重新分区 --就是shuffle过程 我画的wc那个图
Operations which can cause a shuffle include repartition operations like repartition and coalesce, ‘ByKey operations (except for counting) like groupByKey and reduceByKey, and join operations like cogroup and join.
上面这句话是不严谨的 之后测试证实。
The Shuffle is an expensive operation since it involves disk I/O, data serialization, and network I/O.
这块官网好好读读
缓存
val lines = sc.textFile("file:///home/double_happy/data/double_happy.txt")
val words = lines.flatMap(_.split(","))
val pair = words.map((_,1))
val result2 = pair.groupByKey()
val result1 = pair.reduceByKey(_+_)
假设pair之后还有其他的业务逻辑
这里是:
groupByKey
reduceByKey
到pair为止 大家都是公用的 这块就有必要使用cache机制
如果不做这个操作和做了 有什么区别呢?
(1)没有做cache测试
scala> val re = sc.textFile("file:///home/double_happy/data/double_happy.txt").flatMap(_.split(",")).map((_,1))
re: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[16] at map at <console>:24
scala> re.collect
res4: Array[(String, Int)] = Array((spark,1), (flink,1), (flume,1), (nihao,1), (ruozedata,1), (xx,1), (xx,1), (jj,1), (rr,1), (aa,1))
scala>
查看4040页面
再执行一遍 re.collect 页面还是这样的
(2)做cache
scala> val re = sc.textFile("file:///home/double_happy/data/double_happy.txt").flatMap(_.split(",")).map((_,1))
re: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:24
scala> re.collect
res0: Array[(String, Int)] = Array((spark,1), (flink,1), (flume,1), (nihao,1), (ruozedata,1), (xx,1), (xx,1), (jj,1), (rr,1), (aa,1))
scala> re.collect
res1: Array[(String, Int)] = Array((spark,1), (flink,1), (flume,1), (nihao,1), (ruozedata,1), (xx,1), (xx,1), (jj,1), (rr,1), (aa,1))
scala> re.cache
res2: re.type = MapPartitionsRDD[3] at map at <console>:24
scala> re.reduceByKey(_+_).collect
res3: Array[(String, Int)] = Array((xx,2), (aa,1), (flink,1), (jj,1), (rr,1), (spark,1), (flume,1), (ruozedata,1), (nihao,1))
scala>
查看页面
再执行一边
scala> re.reduceByKey(_+_).collect
res3: Array[(String, Int)] = Array((xx,2), (aa,1), (flink,1), (jj,1), (rr,1), (spark,1), (flume,1), (ruozedata,1), (nihao,1))
scala> re.reduceByKey(_+_).collect
res4: Array[(String, Int)] = Array((xx,2), (aa,1), (flink,1), (jj,1), (rr,1), (spark,1), (flume,1), (ruozedata,1), (nihao,1))
scala>
会发现执行了两次 就根本不是一个东西了 ,做了cache已经把我们的东西持久化到默认的存储级别里去了,下次就会去缓存里读取数据了
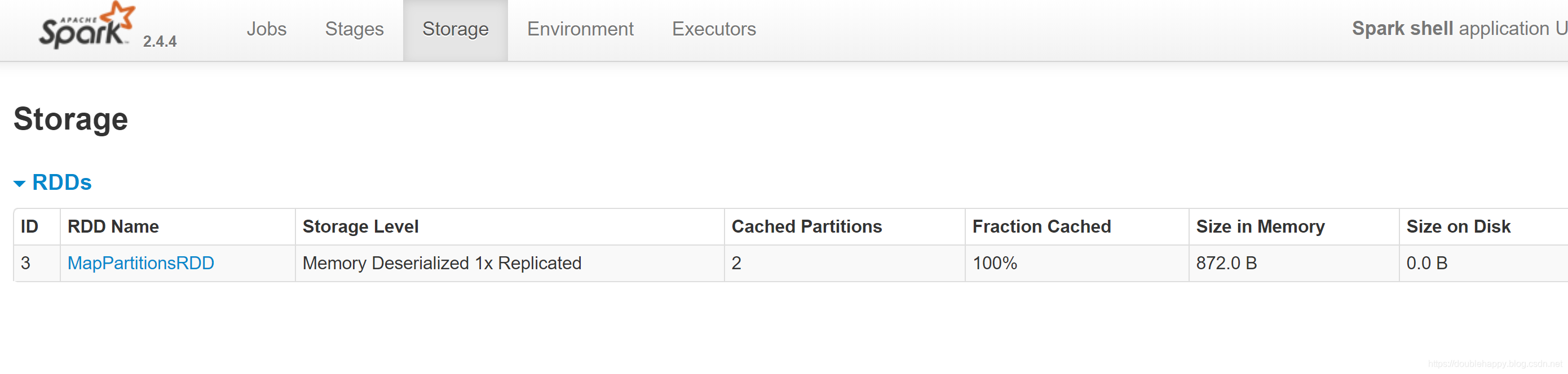
1.不做cache 如果你对同一个操作执行多次 下一次会从头开始执行
2.如果做了cache (lazy 的操作并不会触发)
3.cache后 默认的存储级别后 为什么数据量会变大了呢?
之后再说。
persist和cache的区别
You can mark an RDD to be persisted using the persist() or cache() methods on it. The first time it is computed in an action, it will be kept in memory on the nodes. Spark’s cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it.
If you would like to manually remove an RDD instead of waiting for it to fall out of the cache, use the RDD.unpersist() method.
The first time it is computed in an action
就是说 sparkcore里的
persist、cache 执行是在遇到action算子 才触发
在迭代次数比较多的场景下 使用
scala> val re = sc.textFile("file:///home/double_happy/data/double_happy.txt").flatMap(_.split(",")).map((_,1))
re: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:24
scala> re.collect
res0: Array[(String, Int)] = Array((spark,1), (flink,1), (flume,1), (nihao,1), (ruozedata,1), (xx,1), (xx,1), (jj,1), (rr,1), (aa,1))
scala> re.collect
res1: Array[(String, Int)] = Array((spark,1), (flink,1), (flume,1), (nihao,1), (ruozedata,1), (xx,1), (xx,1), (jj,1), (rr,1), (aa,1))
scala> re.cache
res2: re.type = MapPartitionsRDD[3] at map at <console>:24
scala> re.reduceByKey(_+_).collect
res3: Array[(String, Int)] = Array((xx,2), (aa,1), (flink,1), (jj,1), (rr,1), (spark,1), (flume,1), (ruozedata,1), (nihao,1))
scala> re.reduceByKey(_+_).collect
res4: Array[(String, Int)] = Array((xx,2), (aa,1), (flink,1), (jj,1), (rr,1), (spark,1), (flume,1), (ruozedata,1), (nihao,1))
scala> re.unpersist()
res5: re.type = MapPartitionsRDD[3] at map at <console>:24
scala>
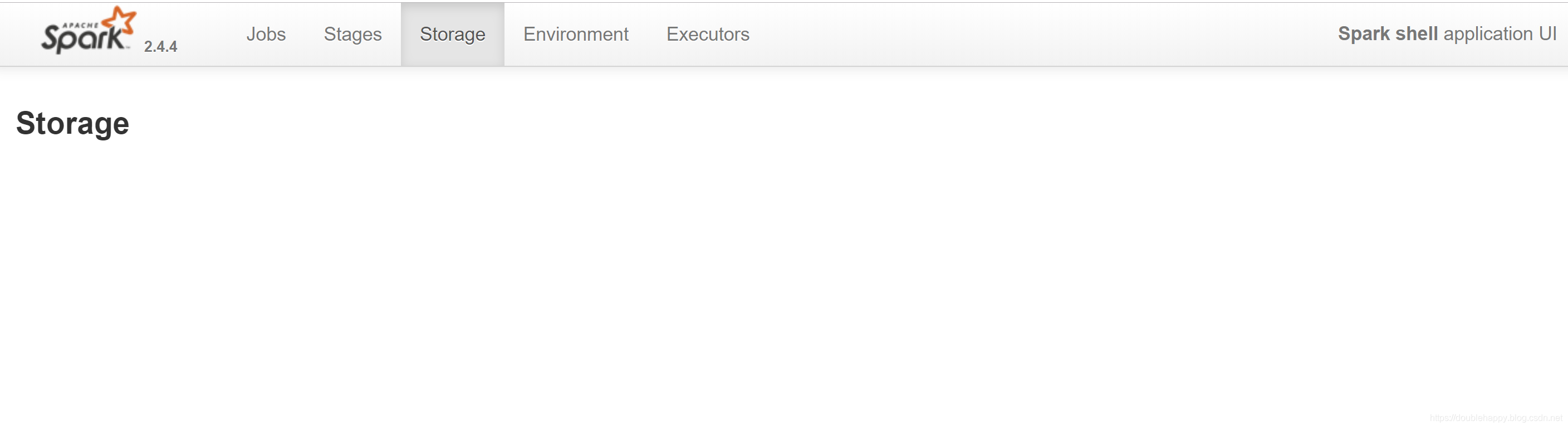
1.cache 、 persist 是 lazy的
2.unpersist 是 eager的
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean, // _deserialized 不序列化
private var _replication: Int = 1)
extends Externalizable
1.cache
==> persist
==> persist(MEMORY_ONLY)
2.cache、persist 默认都走的是MEMORY_ONLY

换一种存储级别
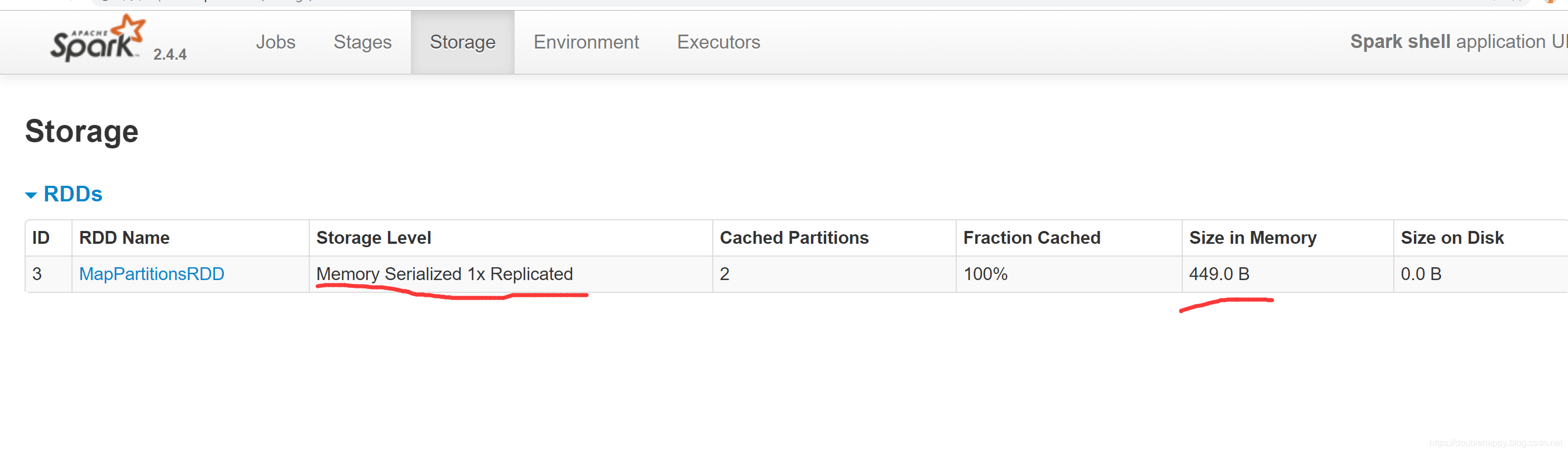
数据是不是小了 序列化的会节省空间
scala> re.collect
res7: Array[(String, Int)] = Array((spark,1), (flink,1), (flume,1), (nihao,1), (ruozedata,1), (xx,1), (xx,1), (jj,1), (rr,1), (aa,1))
scala> re.unpersist()
res8: re.type = MapPartitionsRDD[3] at map at <console>:24
scala> import org.apache.spark.storage.StorageLevel
import org.apache.spark.storage.StorageLevel
scala> re.persist(StorageLevel.MEMORY_ONLY_SER)
res9: re.type = MapPartitionsRDD[3] at map at <console>:24
scala> re.collect
res10: Array[(String, Int)] = Array((spark,1), (flink,1), (flume,1), (nihao,1), (ruozedata,1), (xx,1), (xx,1), (jj,1), (rr,1), (aa,1))
scala>
Which Storage Level to Choose?
Which Storage Level to Choose?
一定要做序列化么?这和压缩是一个道理
Spark’s storage levels are meant to provide different trade-offs between memory usage and CPU efficiency.
coalesce和repartition
repartition
/**
* Return a new RDD that has exactly numPartitions partitions.
*
* Can increase or decrease the level of parallelism in this RDD. Internally, this uses
* a shuffle to redistribute data.
*
* If you are decreasing the number of partitions in this RDD, consider using `coalesce`,
* which can avoid performing a shuffle.
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
注意:
Can increase or decrease the level of parallelism in this RDD
shuffle = true
就是
repartition 无论增大还是减少 分区数 它都走shuffle
增大分区数 我们使用repartition
repartition 底层调用coalesce
package com.ruozedata.spark.spark03
import com.ruozedata.spark.homework.utils.ContextUtils
import com.ruozedata.spark.homework.utils.ImplicitAspect._
object CoalesceAndRepartitionApp {
def main(args: Array[String]): Unit = {
val sc = ContextUtils.getSparkContext(this.getClass.getSimpleName)
val data = sc.parallelize(List(1 to 9: _*),3)
data.mapPartitionsWithIndex((index,partition) => {
partition.map(x=>s"分区是$index,元素是$x")
}).printInfo()
val repartitionRDD = data.repartition(4)
repartitionRDD.mapPartitionsWithIndex((index,partition) => {
partition.map(x=>s"分区是$index,元素是$x")
}).printInfo()
sc.stop()
}
}
结果:
分区是1,元素是4
分区是0,元素是1
分区是1,元素是5
分区是1,元素是6
分区是0,元素是2
分区是0,元素是3
分区是2,元素是7
分区是2,元素是8
分区是2,元素是9
-------------------------
分区是1,元素是3
分区是0,元素是2
分区是1,元素是6
分区是0,元素是5
分区是1,元素是9
分区是0,元素是8
分区是3,元素是1
分区是3,元素是4
分区是3,元素是7
-------------------------
scala> val data = sc.parallelize(List(1 to 9: _*),3)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:25
scala> data.repartition(4)
res11: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[10] at repartition at <console>:27
scala> data.repartition(4).collect
res12: Array[Int] = Array(2, 7, 3, 4, 8, 5, 9, 1, 6)
scala>
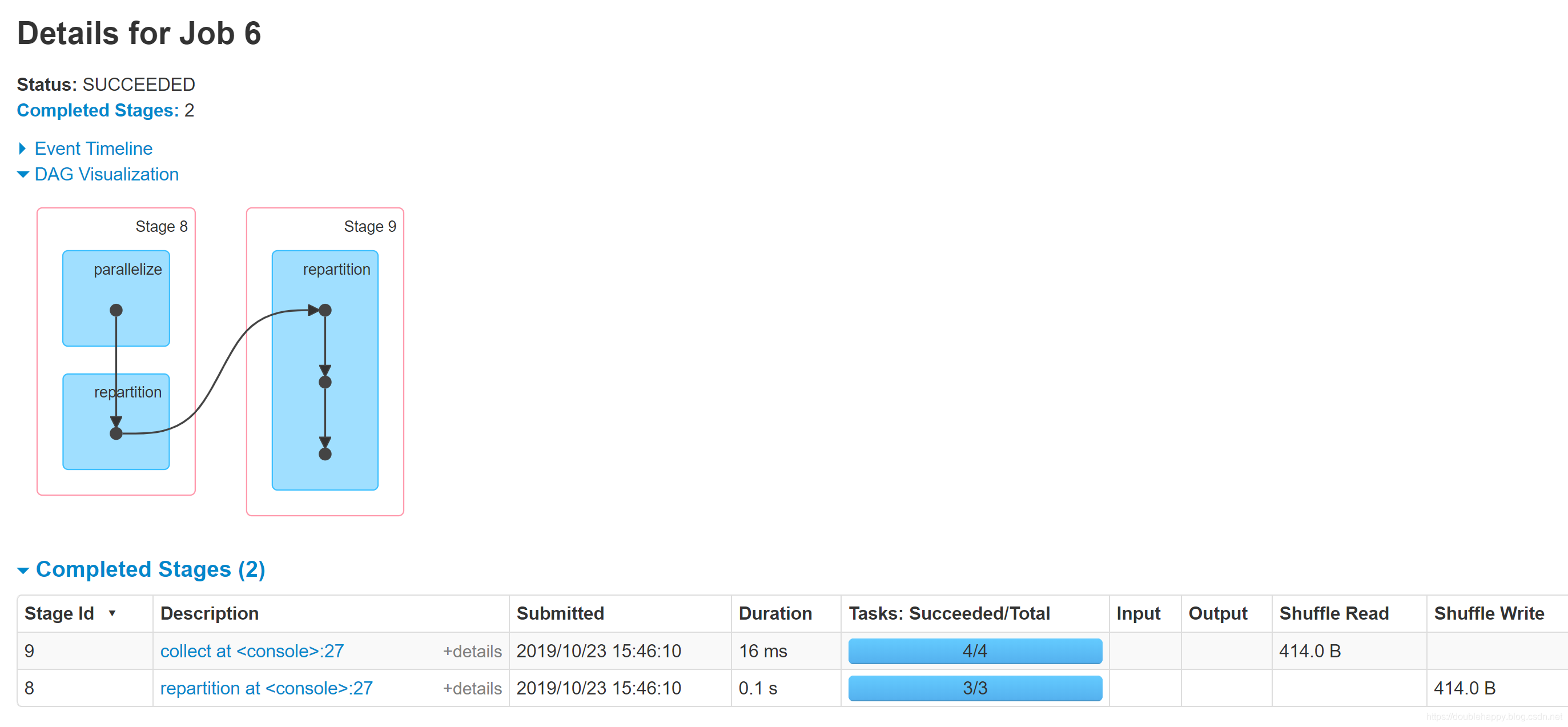
1.能够说明 repartition是走shuffle的
coalesce
/**
* Return a new RDD that is reduced into `numPartitions` partitions.
*
* This results in a narrow dependency, e.g. if you go from 1000 partitions
* to 100 partitions, there will not be a shuffle, instead each of the 100
* new partitions will claim 10 of the current partitions. If a larger number
* of partitions is requested, it will stay at the current number of partitions.
*
* However, if you're doing a drastic coalesce, e.g. to numPartitions = 1,
* this may result in your computation taking place on fewer nodes than
* you like (e.g. one node in the case of numPartitions = 1). To avoid this,
* you can pass shuffle = true. This will add a shuffle step, but means the
* current upstream partitions will be executed in parallel (per whatever
* the current partitioning is).
*
* @note With shuffle = true, you can actually coalesce to a larger number
* of partitions. This is useful if you have a small number of partitions,
* say 100, potentially with a few partitions being abnormally large. Calling
* coalesce(1000, shuffle = true) will result in 1000 partitions with the
* data distributed using a hash partitioner. The optional partition coalescer
* passed in must be serializable.
*/
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = (new Random(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),
new HashPartitioner(numPartitions)),
numPartitions,
partitionCoalescer).values
} else {
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}
注意:
Return a new RDD that is reduced into `numPartitions` partitions.
1.coalesce 用来 reduced numPartitions
shuffle: Boolean = false,
2。coalesce 默认是不走shuffle的
scala> data.partitions.size
res15: Int = 3
scala> data.coalesce(4).partitions.size
res16: Int = 3
scala> data.coalesce(2).partitions.size
res17: Int = 2
scala>data.coalesce(4,true).partitions.size //这样就走shuffle啦
res18: Int = 4
repartition调用的是coalesce算子,shuffle默认为true 会产生新的 stage
coalesce shuffle默认为false 传shuffle为true,就和repartition一样
Operations which can cause a shuffle include repartition operations like repartition and coalesce,
所以这句话 coalesce 默认是不会产生shuffle的 官网这话不严谨。