scrapy_redis分布式爬虫总结
scrapy_redis:Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:reqeust去重,爬虫持久化,和轻松实现分布式
安装:
pip3 install scrapy-redis
Scrapy_redis是工作流程
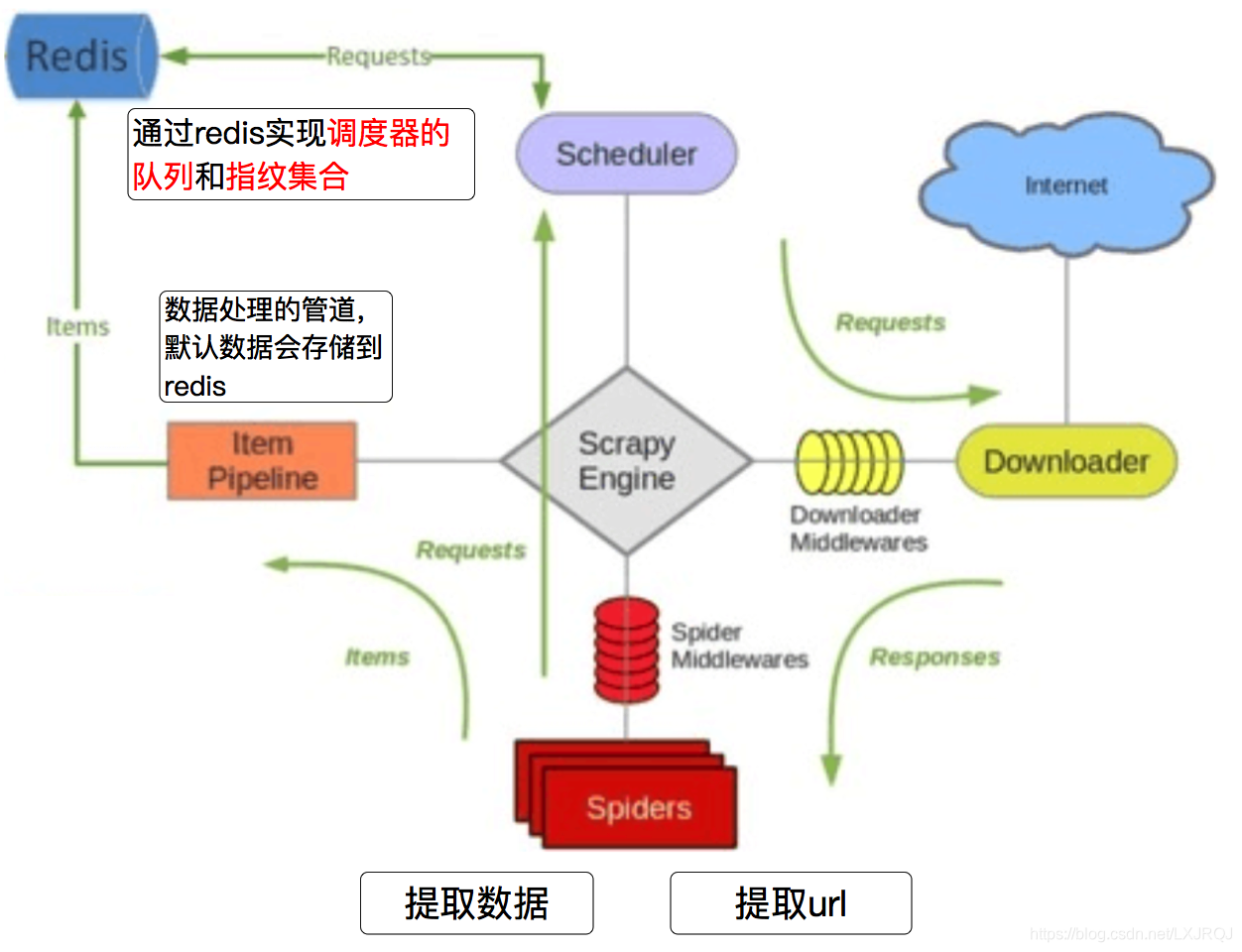
第一步: 启动Redis
首先需要把Redis启动起来。使用Mac OS/Linux的可以在终端下面输入以下命令并回车: redis-server
使用Windows的,在CMD中cd进入存放Redis的文件夹,并运行:
redis-server.exe
第二步: 修改爬虫
在前面的课程中,我们爬虫是继承自scrapy.Spider这个父类。这是Scrapy里面最基本的一个爬虫类,只能实现基本的爬虫功能。现在需要把它替换掉,从而实现更高级的功能。
请对比一下下面这段使用了Scrapy_redis的代码与前面read color网站爬虫的代码头部有什么不同:
from scrapy_redis.spiders import RedisSpider
class ReadColorSpider(RedisSpider):name ="readcolorspider"
redis_key ='readcolorspider:start_urls'
可以看出,这里爬虫的父类已经改成了RedisSpider,同时多了一个:
redis_key='readcolorspider:start_urls'
这里的redis_key实际上就是一个变量名,之后爬虫爬到的所有URL都会保存到Redis中这个名为==“readcolorspider:start_urls”==的列表下面,爬虫同时也会从这个列表中读取后续页面的URL。这个变量名可以任意修改。
除了这两点以外,在爬虫部分的其他代码都不需要做修改。
实际上,这样就已经建立了一个分布式爬虫,只不过现在只有一台电脑。
第三步: 修改设置
现在已经把三轮车换成了挖掘机,但是Scrapy还在按照指挥三轮车的方式指挥挖掘机,所以挖掘机还不能正常工作。因此修改爬虫文件还不行,Scrapy还不能认识这个新的爬虫。现在修改settings.py。
(1)Scheduler
首先是Scheduler的替换,这个东西是Scrapy中的调度员。在settings.py中添加以下代码:
Enables scheduling storing requests queue in redis.
SCHEDULER="scrapy_redis.scheduler.Scheduler"
(2)去重
Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS="scrapy_redis.dupefilter.RFPDupeFilter"
设置好上面两项以后,爬虫已经可以正常开始工作了。不过还可以多设置一些东西使爬虫更好用。
(3)不清理Redis队列
Don't cleanup redis queues, allows to pause/resume crawls.
SCHEDULER_PERSIST=True
如果这一项为True,那么在Redis中的URL不会被Scrapy_redis清理掉,这样的好处是:爬虫停止了再重新启动,它会从上次暂停的地方开始继续爬取。但是它的弊端也很明显,如果有多个爬虫都要从这里读取URL,需要另外写一段代码来防止重复爬取。
如果设置成了False,那么Scrapy_redis每一次读取了URL以后,就会把这个URL给删除。这样的好处是:多个服务器的爬虫不会拿到同一个URL,也就不会重复爬取。但弊端是:爬虫暂停以后再重新启动,它会重新开始爬。
第四步: 爬虫请求的调度算法
爬虫的请求调度算法,有三种情况可供选择:
队列
SCHEDULER_QUEUE_CLASS='scrapy_redis.queue.SpiderQueue'
如果不配置调度算法,默认就会使用这种方式。它实现了一个先入先出的队列,先放进Redis的请求会优先爬取。
栈
SCHEDULER_QUEUE_CLASS='scrapy_redis.queue.SpiderStack'
这种方式,后放入到Redis的请求会优先爬取。
优先级队列
SCHEDULER_QUEUE_CLASS='scrapy_redis.queue.SpiderPriorityQueue'
这种方式,会根据一个优先级算法来计算哪些请求先爬取,哪些请求后爬取。这个优先级算法比较复杂,会综合考虑请求的深度等各个因素。
第五步: 导出分布式爬虫redis数据库中存储的数据
数据爬回来了,但是放在Redis里没有处理。之前我们配置文件里面没有定制自己的ITEM_PIPELINES,而是使用了RedisPipeline,所以现在这些数据都被保存在redis中,所以我们需要另外做处理。
在项目目录下可以看到一个process_items.py文件,这个文件就是scrapy-redis的example提供的从redis读取item进行处理的模版。
假设我们要把redis中的items保存的数据读出来写进MongoDB或者MySQL,那么我们可以自己写一个process_profile.py文件,然后保持后台运行就可以不停地将爬回来的数据入库了。
将数据导出存储进入mongodb
import json
import redis
import pymongo
def main():
# 指定Redis数据库信息
rediscli = redis.StrictRedis(host='localhost', port=6379, db=0)
# 指定MongoDB数据库信息
mongocli = pymongo.MongoClient(host='localhost', port=27017)
# 指定数据库
db = mongocli['数据库名称']
# 指定集合
sheet = db['集合名称']
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop(“项目名:items")
data = data.decode('utf-8')
item = json.loads(data)
try:
sheet.insert(item)
print ("Processing:insert successed" % item)
except Exception as err:
print ("err procesing: %r" % item)
if __name__ == '__main__':
main()
将数据导出存入 MySQL
首先启动mysql
创建数据库和表
import json
import redis
import pymongo
def main():
# 指定redis数据库信息
rediscli = redis.StrictRedis(host='localhost', port = 6379, db = 0)
# 指定mysql数据库
mysqlcli = pymysql.connect(host='localhost', user='用户', passwd='密码', db = '数据库', port=3306, charset='utf8')
# 使用cursor()方法获取操作游标
cur = mysqlcli.cursor()
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop("redis中对应的文件夹:items")
item = json.loads(data.decode('utf-8'))
try:
# 使用execute方法执行SQL INSERT语句
cur.execute("sql语句",['数据',....])
# 提交sql事务
mysqlcli.commit() print("inserted successed")
except Exception as err:
#插入失败
print("Mysql Error",err)
mysqlcli.rollback()
if __name__ == '__main__':
main()
一、主要区别
scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。
scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,Slaver端共享Master端redis数据库里的item队列、请求队列和请求指纹集合。
二、为什么选择redis数据库,
因为redis支持主从同步,而且数据都是缓存在内存中的,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。
你用过的爬虫框架或者模块有哪些?谈谈他们的区别或者优缺点 ?
Python自带:urllib,urllib2第 三 方:requests 框 架:Scrapy 3. urllib和urllib2模块都做与请求URL相关的操作,但他们提供不同的功能。 urllib2.:urllib2.urlopen可以接受一个Request对象或者url,(在接受Request对象时候,可以设置一个URL headers), urllib.urlopen只接收一个url urllib 有urlencode,urllib2没有,因此总是urllib,urllib2常会一起使用的原因
Scrapy优缺点:
优点:
scrapy 是异步的 采取可读性更强的xpath代替正则 强大的统计和log系统 同时在不同的url上爬行 支持shell方式,方便独立调试 写middleware,方便写一些统一的过滤器 通过管道的方式存入数据库
缺点:
基于python的爬虫框架,扩展性比较差 基于twisted框架,运行中的exception是不会干掉reactor, 并且异步框架出错后是不会停掉其他任务的,数据出错后难以察觉。