版权声明:本文为博主原创文章,遵循 CC 4.0 BY 版权协议,转载请附上原文出处链接和本声明。
爱站批量查网站权重2.0版本已经更新
爱站批量查询网址权重2.0版本
爱站批量查网站权重
相信很多人在批量刷野战的时候,会去查看网站的权重吧,然后在决定是否提交给补天还在是盒子。但是不能批量去查询,很困惑,作为我这个菜鸟也很累,一个个查询的。所以写了这个脚本。
下面是使用方法:
blog: https://blog.csdn.net/sun1318578251
如果在cmd运行中得先转脚本对应的绝对路径下运行。不然会爆文件不存在的错误。
如果在pycharm等集成环境中使用的话,将脚本文件作为一个项目打开。.
将需要查询的网站保存在相同目录下的websites.txt文本中,一行一个网站。格式:https://www.xxx.com http://www.xxx.com www.xxx.com
本脚本不能保证一次完全都能查询成功,但失败的网站会保存在Query failure.csv文件中,成功的网站会保存在webweight.csv文件中。
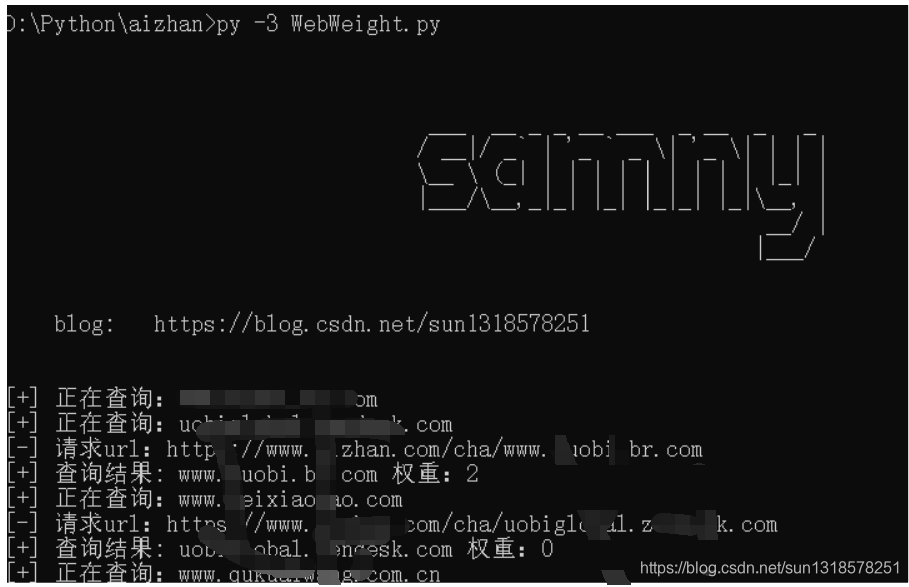
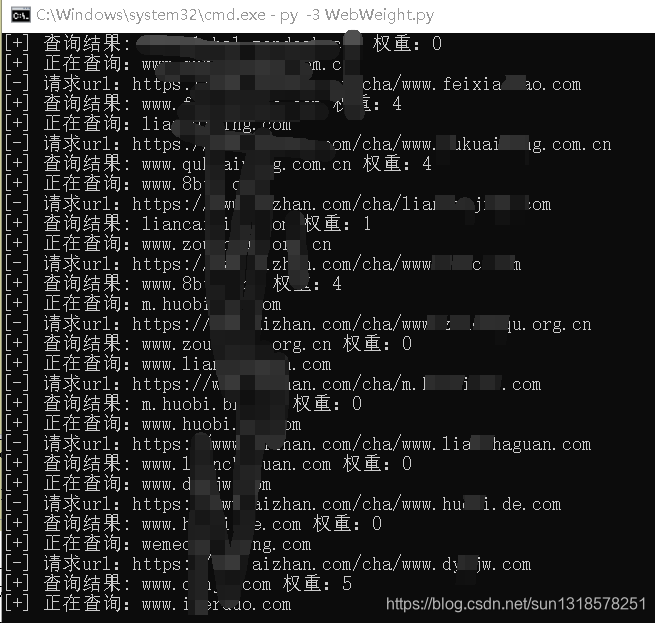
全部代码
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/8/12 13:50
# @Author : 清水
# @File : WebSiteCrawler.py
# @Software: PyCharm
# @Function : 批量查网站权重
import requests
import BeautifulRequests
from bs4 import BeautifulSoup
import csv
import threading
from queue import Queue
import time
class WebWeight(threading.Thread):
def __init__(self,queue):
threading.Thread.__init__(self)
self.queue = queue
def run(self):
while not self.queue.empty():
# 爱站的网站url
aizhanurl = 'https://www.aizhan.com/cha/'
# 获取查询的网站的url
chaxunurl = self.queue.get()
print("[+] 正在查询:"+ chaxunurl)
url = aizhanurl+chaxunurl
time.sleep(4) # 延迟4s
re = requests.get(url)
print("[-] 请求url:"+ url)
html = re.text.encode(re.encoding).decode('utf-8')
soup = BeautifulSoup(html,'lxml')
tags = soup.select("img[alt]")
# 测试
# for tag in tags:
# strtag = str(tag) # 将tag属性转换为字符串
# if 'br' in strtag:
# if 'mbr' not in strtag:
# if '0.png' in strtag:
# print(tag)
# 写入数据
# 如果使用python3就下面这个
with open("webweight.csv", "a+", encoding='utf-8', newline='')as file:
# # 如果使用python2就下面这个
#with open("webweight.csv", "a+")as file:
# 创建csv对象并传参
csvwriter = csv.writer(file)
for tag in tags:
strtag = str(tag) # 将tag属性转换为字符串
if 'br' in strtag:
if 'mbr' not in strtag:
if '0.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '0'])
print("[+] 查询结果: "+ chaxunurl+" 权重:"+ str(0))
elif '1.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '1'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(1))
elif '2.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '2'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(2))
elif '3.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '3'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(3))
elif '4.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '4'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(4))
elif '5.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '5'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(5))
elif '6.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '6'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(6))
elif '7.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '7'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(7))
elif '8,png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '8'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(8))
elif '9.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '9'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(9))
elif '10.png' in strtag:
csvwriter.writerow(['' + chaxunurl, '' + '10'])
print("[+] 查询结果: " + chaxunurl + " 权重:" + str(10))
else:
print("[\] Query failure ! ! 失败结果保存在Query failure.csv")
with open("Query failure.csv", "a+", encoding='utf-8', newline='')as file:
csvwriter = csv.writer(file)
csvwriter.writerow(['' + chaxunurl])
def main():
print('''
___ __ _ _ __ ___ _ __ _ _
/ __|/ _` | '_ ` _ \| '_ \| | | |
\__ \ (_| | | | | | | | | | |_| |
|___/\__,_|_| |_| |_|_| |_|\__, |
__/ |
|___/
blog: https://blog.csdn.net/sun1318578251
''')
with open("webweight.csv", "a", encoding='utf-8', newline='')as file:
csvwriter = csv.writer(file)
csvwriter.writerow(['weburl','weight'])
threads = [] # 线程集
# 线程数
threads_count = 2
# 队列
# 如果是使用python3就修改下面
# queue = Queue()
# queue = Queue.Queue()
queue = Queue()
with open("websites.txt", "r")as file:
file_content = file.readlines()
for i in file_content:
# 文件读取中字符串结尾会有\r\n
j = i.strip('\n').strip('\r')
k = j.lstrip('https://')
t = k.lstrip('http://')
queue.put(t)
for i in range(threads_count):
# 添加线程
threads.append(WebWeight(queue))
# 线程的开始与加入
for i in threads:
time.sleep(3) # 延迟6s
i.start()
for i in threads:
time.sleep(3) # 延迟6s
i.join()
print("Results saved in webweight.csv")
if __name__ == '__main__':
main()