课程链接:阿里云大学_分布式系统开发-调度技术
海量数据如何并发处理?
这就是分布式任务调度所要解决的问题
举个栗子:
如何快速的做出大量的热狗?
如果将每一个一个热狗按流程做的话,可见工作量会十分巨大而且效率低下
MapReduce实例
Google的传奇大神Jeff Dean借鉴函数式编程的思想,提出了MapReduce解决方案,其核心思想其实很简单:
- 对任务按需求切分成多个子任务
- 对每一个子任务做mapping映射操作,得到一个中间态结果
- 再对所有的中间态结果进行reduce合并,得到最终结果
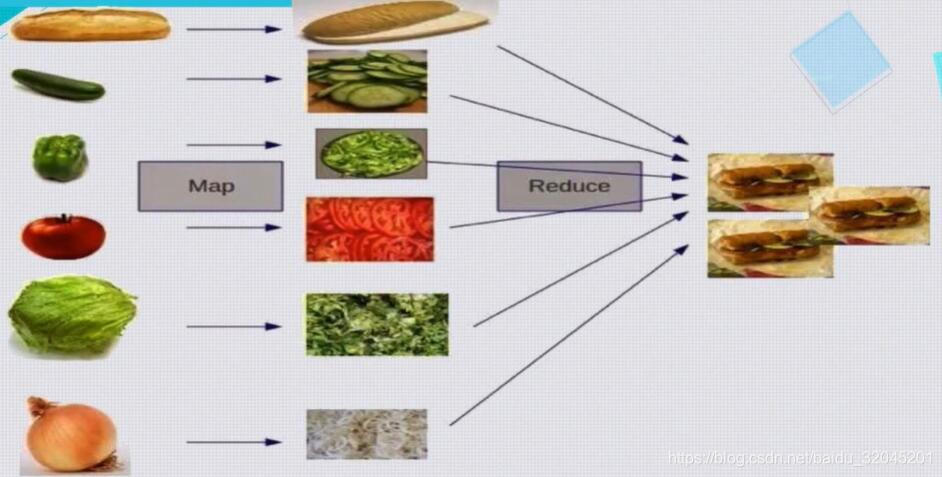
我们换个角度理解MapReduce操作:
- 做热狗时,会有多个厨师分别把不同的原材料切好,这一步叫mapping操作,至于切成什么样可不是随便的,这要由问题的解空间决定,比如要做热狗,就要把面包切两半,而不是碾成面包糠,要把黄瓜切成片,而不是切成块
- 还会有一些厨师,按照一定的比例,将处理好的原材料组装成最终的热狗,这一步叫做reducing操作
关于MapReduce,有一个非常经典的案例就是Word Count,接下来通过一张图了解Word Count的流程:
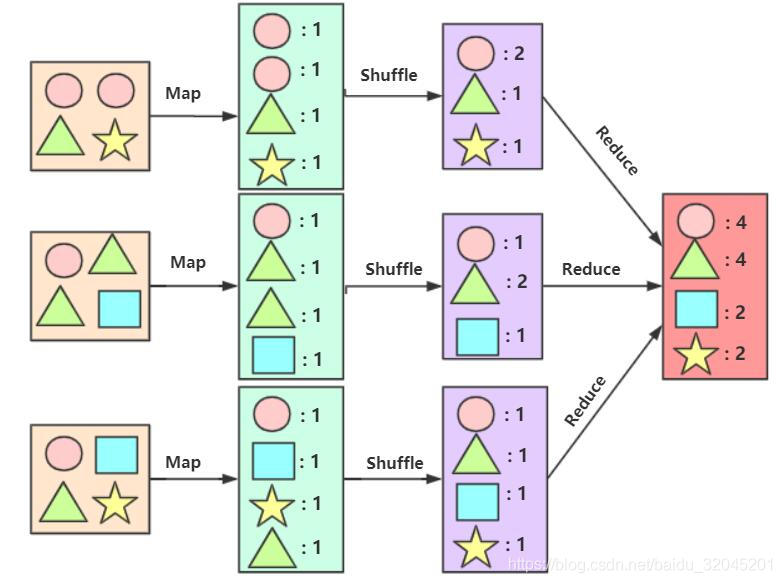
其中Shuffle阶段是在mapping操作结束后,reducing操作开始前进行,它可以将mapping操作的结果进行一个小范围的聚合,可以减轻reduce拉取时的消耗
阿里飞天任务调度系统
飞天系统中,参与任务调度的主要有App Master和App Worker
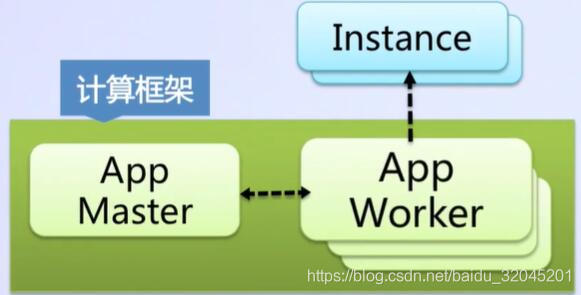
App Master
- 向Fuxi Master发起资源请求
- 将资源分配结果下发给对应的集群节点上,拉起App Worker进程
- 负责监控Instance运行期间,如果发生故障,如何进行重试
App Worker
- 响应App Master发来的请求
- 进行运算,并将结果写到输出文件上
任务调度系统的技术要点
数据Locality
Instance运行时是要读取数据的,那么最好是让Instance在本地读取数据,因为如果远程读取数据的话,会涉及网络IO,这样会使性能下降,因此我们希望Instance能够多的在本地读取数据。下面举一个栗子
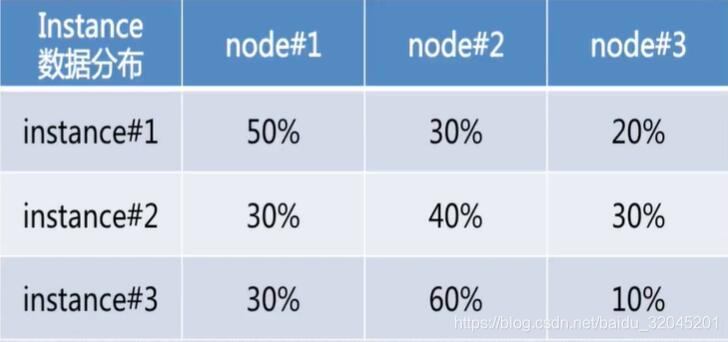
表中是每一个Instance在不同节点上的数据分布情况。为了使Instance尽可能多的在本地读取数据,我们可以这样分配Instance的存储节点
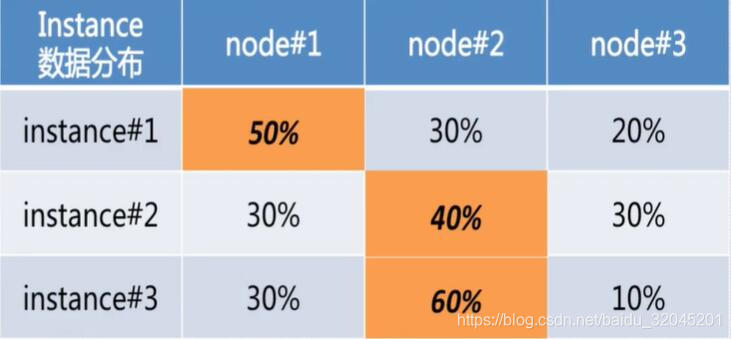
但是,这样还是存在问题,就是node3是空闲的,而node2非常繁忙
那么为了最大化的利用资源,究竟怎么重新分配Instance2和Instance3呢?
一种方法是这样:
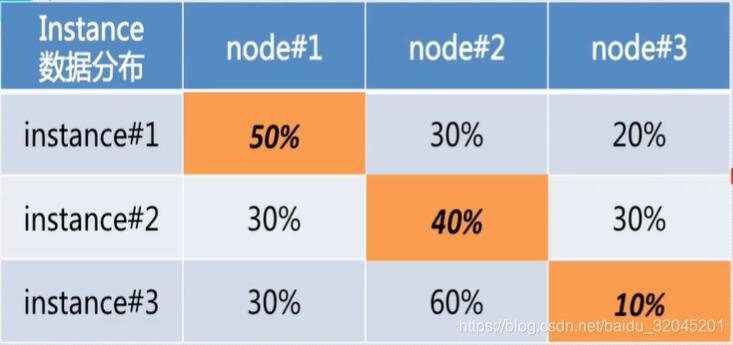
这样一来,虽然每个节点都分配了Instance,但是可以发现,Instance3将会多出50%的远程数据读取消耗
如果我们这样分配:
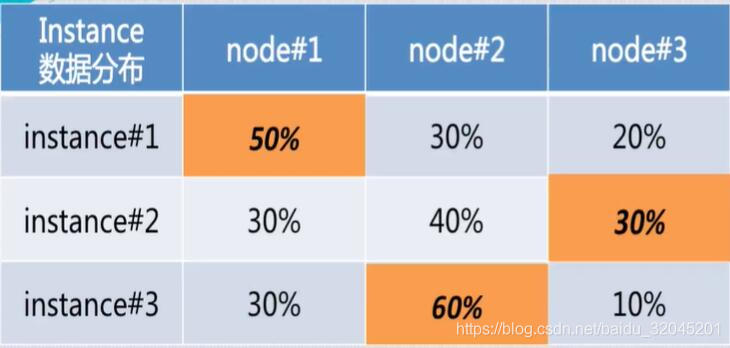
那么,只需要牺牲10%的远程数据读取消耗就可以最大化的利用资源,同时提高效率
因此,不是一味地追求数据的本地化,而要全盘考虑资源的负载是否均衡
数据Shuffle
数据的Shuffle主要就是负责Map和Reduce之间的数据传递,其主要有这样几种模式:
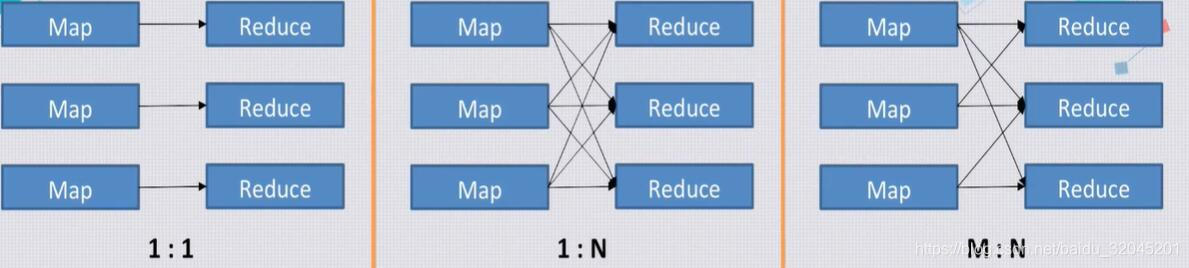
通常,Map的结果需要写入分布式存储系统中去,然后Reduce再从分布式存储系统中拉取数据,因此这其中就涉及到了数据的格式问题,而现有的服务器系统会将数据的格式化封装到Streamline包中,用户只需要根据接口定义数据类型即可

Instance重跑和Backup Instance
错误在分布式系统中是十分常见的,对于不同的错误要有不同的处理方法
例如,当某一个作业进程崩溃,或是某一台机器宕机,那么任务调度系统,会立即将任务切换到另一台机器运行
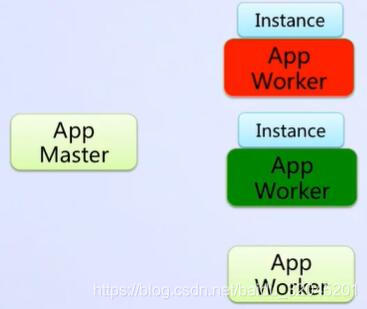
还有一种情况是,运行并没有问题,但是由于机器硬件的性能退化,导致运行缓慢,那么这样的问题如何处理呢?
阿里云服务器系统提供了一种Backup Instance方法,当遇到这样的问题,App Master会将Instance再发送给另一台机器,两台机器同时运行Instance,谁先运行完毕就取谁的结果
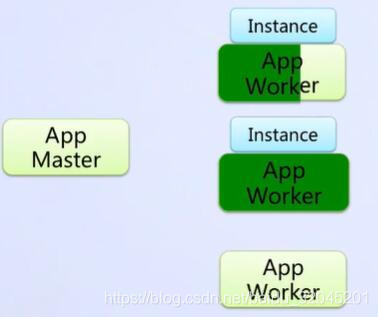
但是这个机制的触发,需要以下条件:
- 运行时间超过其他Instance的平均运行时间
- 数据处理速度低于其他Instance的平均值
- 已完成的Instance比例