1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
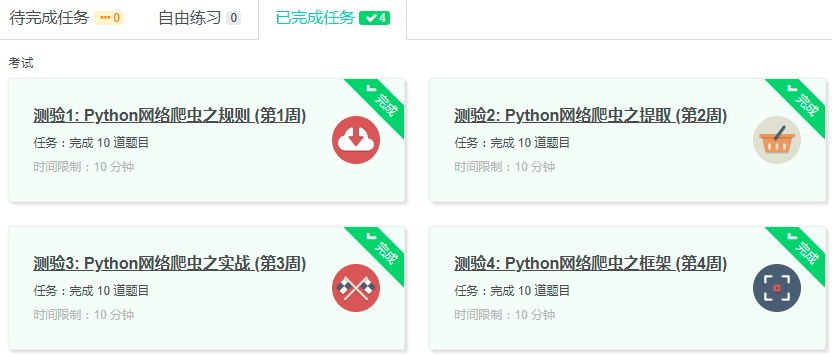
4.提供图片或网站显示的学习进度,证明学习的过程
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
第一周笔记:
Python网络爬虫与信息提取:
内容分为:
Requests:自动爬取HTML页面自动网络请求提交
Robots.txt:网络爬虫排除标准
Beautiful Soup:解析HTML页面
Projects:实战项目A/B
Re:正则表达式详解提取页面关键信息
Scrapy:网络爬虫原理介绍,专业爬虫框架介绍
用管理员身份运行cm,执行pip install requests;
Requests库的2个重要对象:request,response,response对象包含爬虫返回的内容了解及使用。
HTTP协议及Requests库方法:
Requests库的7个主要方法:
requests.request():构造一个请求,支撑以下各方法的基础方法
requests.get():获取HTML网页的主要方法,对应HTTP的GET
requests.head():获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post():向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put():向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch():向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete():向HTML页面提交删除请求,对应于HTTP的DELETE
第二周笔记:
对BeautifulSoup库进行安装,以管理员运行cmd,执行pip install beautifulsoup4.
Beautifulsoup是解析,边历,维护“标签数”的功能库,beautifulsoup类的基本元素:
Tag(标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾。任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。);
Attributes(标签的属性,字典的形式组织,格式:<tag>.attrs。一个<tag>可以有0个或多个属性,字典类型);
Name(标签的名字,<p>...</p>的名字是‘p’,格式:<tag>.name。每个<tag>都有自己的名字,通过<tag>.name获取,字符串类型);
NavigableString(标签内非属性字符串,<>...</>中字符串,格式:<tag>.string。可以跨越多个层次);
Comment(标签内字符串的注释部分,一种特殊的Comment类型);
基于bs4库的HTML内容遍历:
回顾HTML,<>...</>构成了所属关系,形成了标签的树形结构;
标签树的下行遍历:
.contents:子节点的列表,将<tag>所有儿子节点存入列表。
.children:子节点的选代类型,与.contents类似,用于循环遍历儿子节点。
.descendants:子孙节点的选代类型,包含所有子孙节点,用于循环遍历。
Beautifulsoup类型是标签树的根节点
标签树的上行遍历:
.parent:节点的父亲标签;
.parents:节点先辈标签的选代类型,用于循环遍历先辈节点;
遍历所有先辈节点,包括soup本身,所以要区别判断;
标签树的平行遍历:
.next_sibling:返回按照HTML文本顺序的下一个平行节点标签
.previous_sibling:返回按照HTML文本顺序的上一个平行节点标签
.next_siblings:选代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings:选代类型,返回按照HTML文本顺序的前续所有平行节点标签
平行遍历发生在同一个父节点下的各节点间;
第三周:
Re库:
正则表达式:是用来简洁表达一组字符串的表达式;是一种通用的字符串表达框架;进一步,正则表达式是一种针对字符串表达“简洁”和“特征”思想的工具,可以用来判断某字符串的特征归属。
对Re库的主要功能函数(search、match、findall、finditer、sub)进行了解和使用,Re库的函数式法为一次性操作,还有一种为面向对象法,通过compile生成的regex对象。
第四周:
应用Scrapy爬虫框架主要是编写配置型代码:
进入工程目录,执行scrapy genapider demo pyth
该命令作用:
(1)生成一个名称为demo的spider
(2)在spiders目录下增加代码文件demo.py(该命令仅用于生成demo.py,该文件也可以手工生成)
运行爬虫,获取网页命令:scrapy crawl demo
yield关键字的使用:
包含yield语句的函数是一个生成器,生成器每次产生一个值(yield),函数被冻结,被唤醒后再产生一个值,生成器是一个不断产生值得函数。