基于Mysql 5.7
10.30:环境配置,介绍,特性,事务,重点是事务中的隔离性,锁,索’引
10.31:建立 索引、还原备份,
内容安排:
Mysql背景案例分析
Mysql介绍
Mysql特性
Mysql性能调优
Mysql运行监控
Mysql备份与恢复
Mysql主从复制与读写分离
Mysql分库分表之MyCAT
Mysql背景案例分析
数据库在大促高并发场景下的作用
大促高并发场景下数据库面临哪些考验?
数据库优化方向?
1.去IOE
2.28原则,8读,2写。2读有效数据,8读无效数据。
Mysql介绍
关系型数据库,其他关系型数据库Oracle,sqlServer,非关系型Redis,一些国产数据库,如达梦等。半结构化数据库。MariaDB?
在数据库中,每个数据库有三个文件:一个样式(描述文件)、一个数据文件、一个索引文件。样式文件以.fmr为后缀,描述表的结构(列、列类型、索引等)。.ISD(ISAM)或.MYD(MyISAM),包含数据文件上的所有索引的索引树。.ISM(ISAM)或.MYI(MyIsam)该文件依赖于表是否有索引而存在。
show warnings;
存储引擎
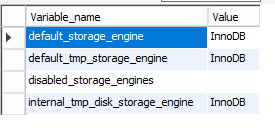
存储引擎就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。有Myiasm,InnoDB,Merge等,Mysql8去除了Myisam引擎,主要保留了InnoDB。
MyIsam:默认引擎(5.1之前),表级锁定,适用于大量的读操作的表、文件存储结构,串行的读写方式。
InnoDB:默认行级锁,也支持表级锁,支持外键、事务处理,适用于大量的写操作的表,并行的读写方式。
通过以下代码可以看到数据库的引擎:
show variables like '%engine%';
上面是通过Navicat For Mysql的方式输入命令,也可通过C:\Program Files\MySQL\MySQL Server 5.7\bin>mysql -u root -p 即可进入命令行的形式。
事务
通过begin开启事务,commit或者rollback结束事务。
BEGIN;//开启事务 insert into classtypes VALUES('t4','学英语'); COMMIT;//提交事务
Mysql可通过 set autocommit=1; 修改是否自动提交,1表示自动提交,0表示不自动提交。Mysql的AutoCommit(自动提交)默认是开启,所以不开启事务的情况下,会自动提交sql。自动提交对Mysql的性能有一定影响,举个例子来说,如果你插入了1000条数据,Mysql会commit1000次的,如果我们把AutoCommit关闭掉,通过程序来控制,只要一次commit就可以了。
ACID https://blog.csdn.net/dengjili/article/details/82468576
查看事务隔离级别。
show VARIABLES like '%iso%';
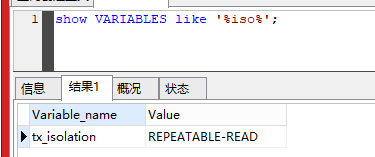
若A表开启事务,B开启事务,A中插入数据,AB均不能查到数据。A提交事务,A能查到数据,B不能查到数据(Oracle此时能查到数据(默认读已提交),这是事务的I属性,隔离性,读未提交、读已提交可读取到,可重复读,串行化不可读到),B关闭事务,能查到数据。
修改事务隔离级别。
set TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
修改成功。
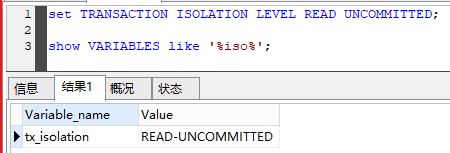
在Navicat里通过set修改数据库隔离级别后, show VARIABLES like '%iso%'; 还是以前的隔离级别,需重启Mysql服务。
锁机制
MyISAM,表级锁,对整个表文件进行锁定。开销小,加锁快,不会出现死锁。
InnoDB,默认行级锁,也支持表级锁,对表文件中局部数据进行锁定,开销大,加锁慢,会出现死锁。哪种情况会出现死锁?
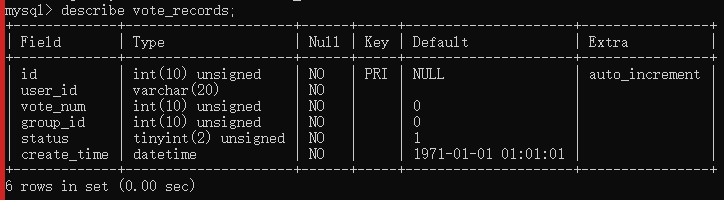
查看表结构。
show CREATE TABLE classtypes;
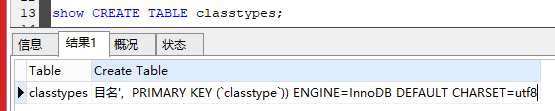
表的结构数据如下:

MDL=meta data lock,元数据锁,在事务开启期间,不能更改数据库结构,发生阻塞。如alert TABLE classtypes add num TINYINT(1); http://blog.itpub.net/29896444/viewspace-2101567/
我们修改同一行数据classtype='t1',发生阻塞,提示错误。
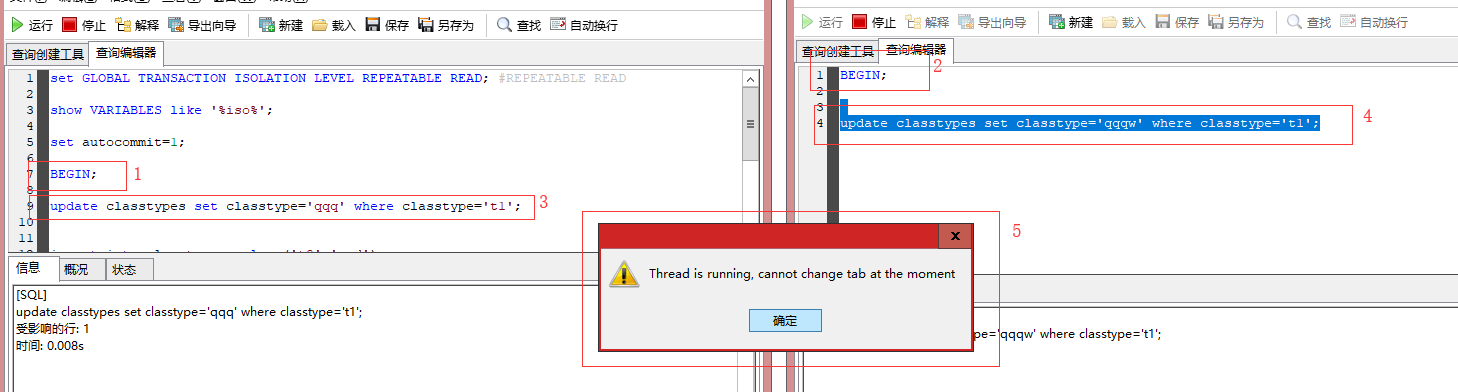
然后我们修改classname,还是出错,把这两行都锁住了,这是因为classname不是索引。
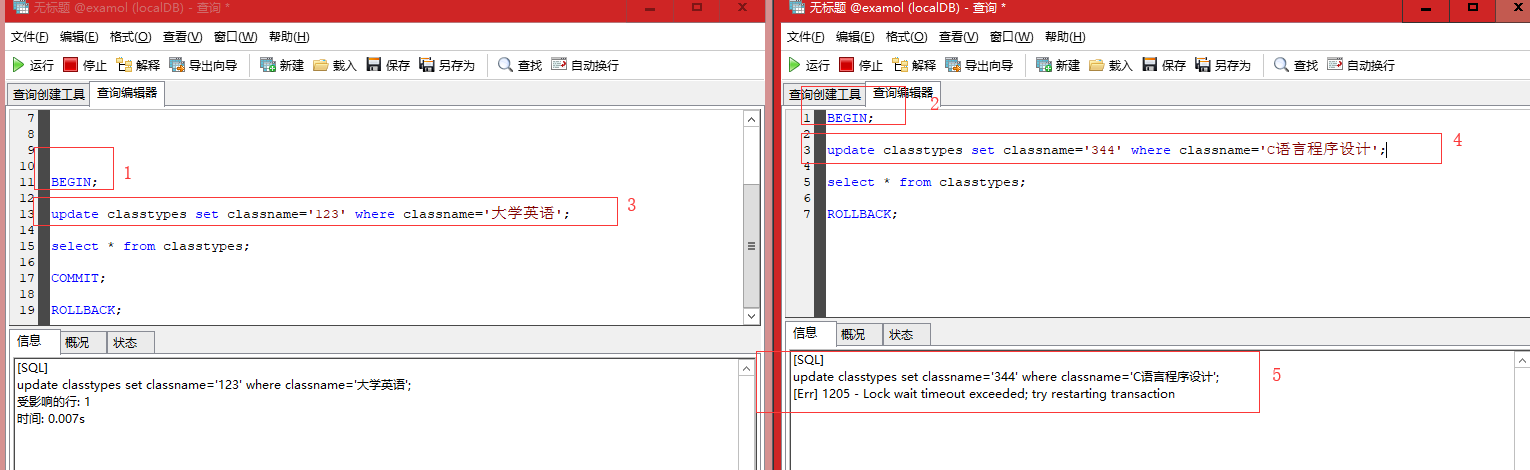
间隙锁。
sql+ lock in SHARE mode
字段类型
数值:tinyint,smallint,mediumint,int(默认长度11),bigint,decimal
字符:varchar,char,text,blog
时间:datetime,8位,1000-01-01 00:00:00 ——9999-12-31-23:59:59
timestamp,4位,1970-01-01 00:00:01——2038
date,3位,1000-01-01——9999-12-31
一个表的字段有id,age,长度都是int(5),那么age最大长度是多少?

如果,插入以下数据,9999超过了2^6-1,会不会出错。最大值int*5???
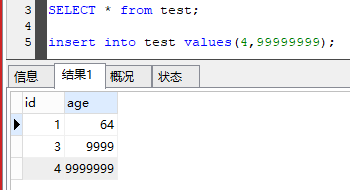
枚举:enum,只能选择其一,如性别,一个enum字段有'M','F'两个,那么只能插入这两个中的其中一个。
索引
目的:加快检索查询。
分类:普通索引,唯一索引,主键索引,全文索引等。唯一索引可以为NULL,主键索引不能为NULL。建索引条件=区分度高,是查询条件
先提出几个问题,为什么要加主键,加索引为什么会变快,为什么要给两个字段都加索引,为什么加了索引删除修改操作变慢?
平时建表都会给表加一个主键,这个主键有什么用呢?事实上, 一个加了主键的表,并不能被称之为表。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我们认知中的数据很接近。如果给表上了主键,那么表在磁盘上的存储结构就由【整齐排列的结构】转变成了【树状结构】,也就是上面说的【平衡树结构】,换句话说,就是整个表就变成了一个索引。也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把表的数据格式转换成【索引】的格式放置。
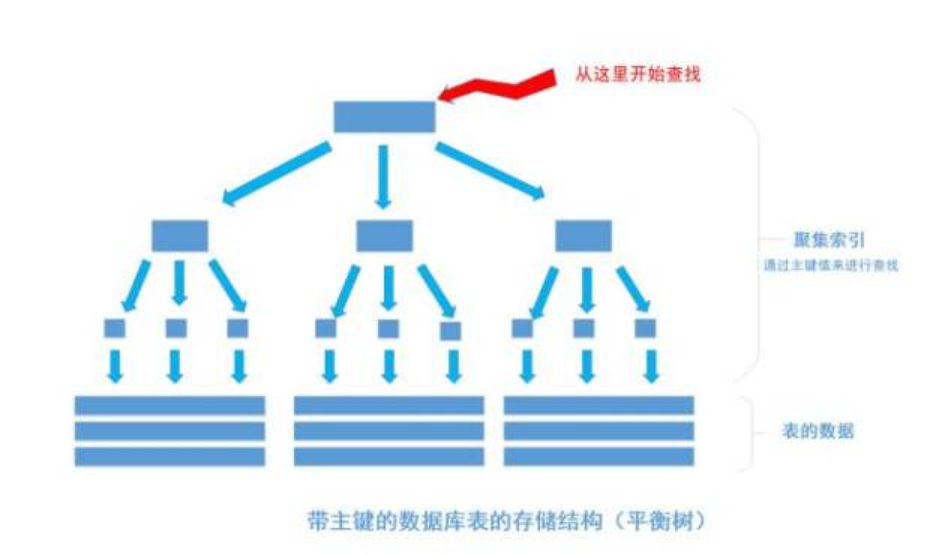
其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节(节点处采用二分法), 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图:
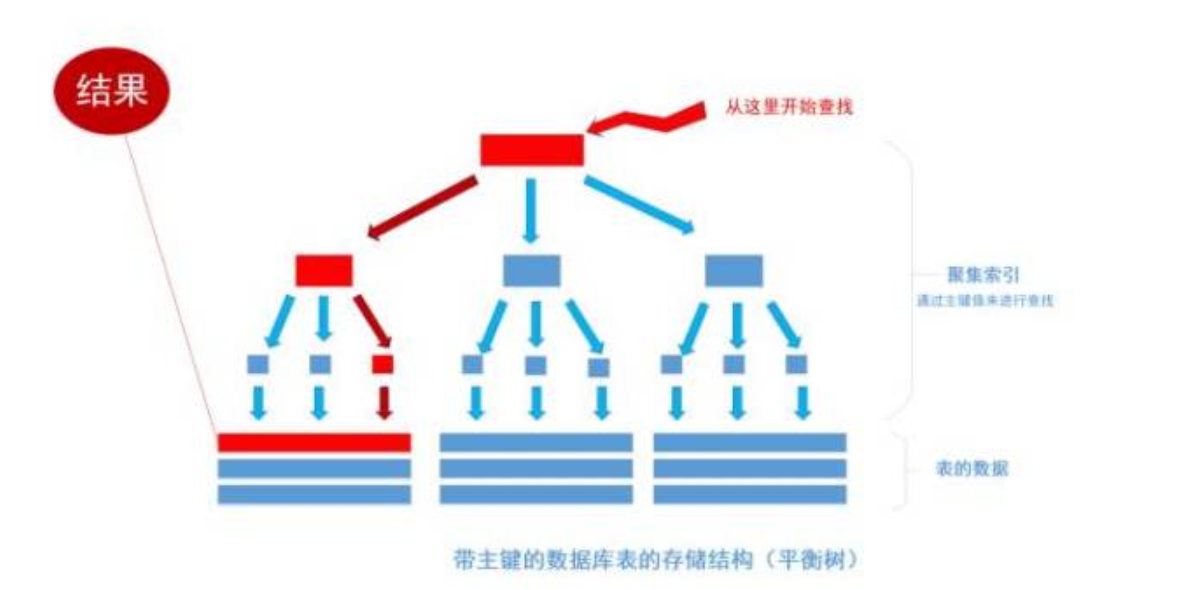
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是

用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。
然而, 事物都是有两面的, 索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
建立索引:CREATE INDEX id on vote_records(id); \G 纵向排列。
查看索引:

%,左边索引不生效,右边生效。检索数据超过30%不走索引。



解决办法,reverse,覆盖索引(不需要回查,即通过查到的key再次查询得到数据)
复合索引,如一个索引为 A,B,那么 where A 会走索引, where A,B走索引, where B不走索引
lock锁表:
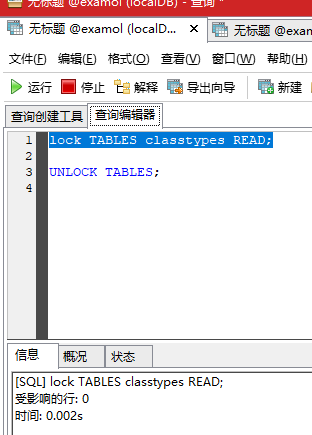
插入数据会被阻塞:
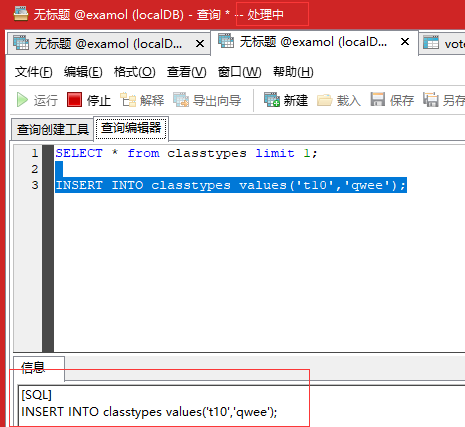
执行UNLOCK TABLES;后解锁,插入成功:

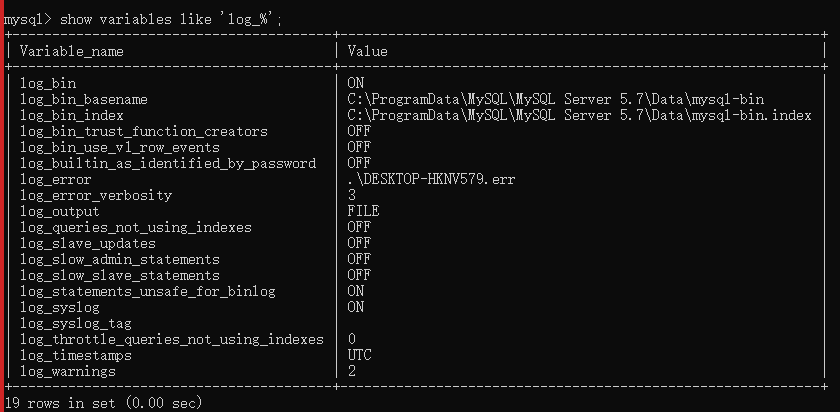
查看日志是否开启:
mysql> show variables like 'log_%';
OFF是关闭,ON是开启。在C:\ProgramData\MySQL\MySQL Server 5.7下的my.ini中设置。


重启服务后,可以看到log-bin成功开启了:
secure_file_priv:
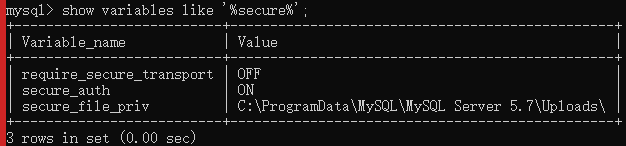

select * into outfile 'E:/test.sql' fields terminated by ',';
CRUD truncate和delete的区别。
有一个表user(id,age),有三条数据(id=1,age=18),(id=1,age=18),(id=1,age=18),执行delete from user后可rollback,插入第四条,id=4
执行truncate,不可rollback,插入第四条,id=1
show processlist;
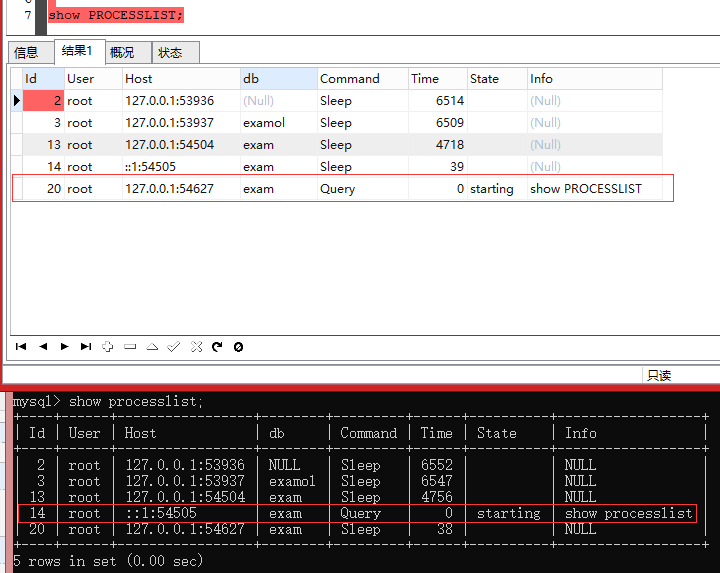
C:\ProgramData\MySQL\MySQL Server 5.7\Data下的ib_logfile0是全do日志,包括select.宕机用这个。主从用mysql-bin-00262日志。
show VARIABLES like '%innodb_flush_log%';
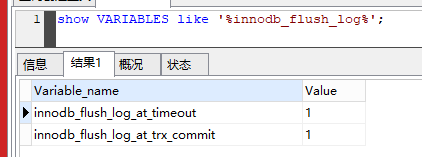
为什么只读模式,5.7比5.6快3倍?怎么优化的?
集群(Cluster):
多个mysql服务器,减轻数据库负担。主从分离,读写分离。master用来写,slave用来读
查询是否开启告诉查询缓存,
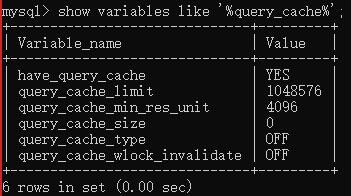
tuning-primer.sh
常用函数
预防死锁:
开发规范:
优化:
开发同学和DBA都需要了解业务情况:
区分SQL的执行环境,是前台还是后台?
评估SQL的执行频率,每天千万次查询和前次查询是不一样的。
评估SQL返回的数据量,关心每条数据还是只关心前100条?关心所有字段,还是真正对用户有意义的字段?
评估表的数据量和增量,从而评估SQL的执行效率。
开发同学写SQL时要注意:
尽量避免查询的结果超过正常的需求,很少有人关心10W页后的数据。
尽量减少表之间的关联,多表之间的关联要使用表的别名来引用表的字段。
不要使用select * ,具体到字段。
尽量减少使用distinct,like,group by,oder by等。
尽量减少子查询,也不要写成inner join格式。
一定要使用绑定变量。
状态查看:
show global status like '%variables%';
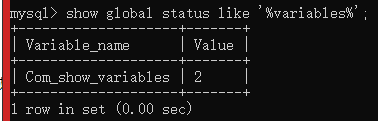
show full processlist;
show engine innodb mutex;

show engine innodb status;
show profile;

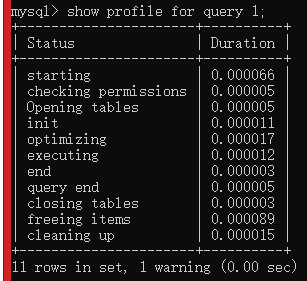
show warnings;
mysql show query;
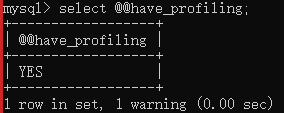
查看profile是否开启:
select @@have_profiling;
show status like '%perf%';
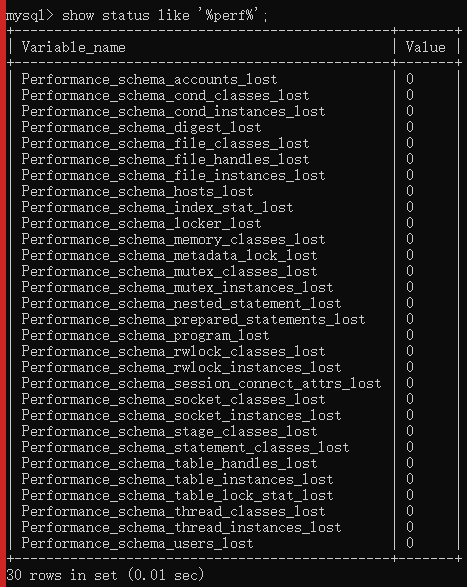
show engine performance_schema status;


select THREAD_ID,NAME,TYPE,INSTRUMENTD from threads;
查询读写top5的等待:
select EVENT_NAME,COUNT_READ 'read',COUNT_WRITE 'write',COUNT_MISC 'misc',(COUNT_MISC+COUNT_WRITE+COUNT_READ) as SUM_IO from file_summary_by_event_name order by 5desc limit 5;
查询读写top5的file
统计在表上锁的top5
统计发生table lock消耗时间最高的表
Mysql特性
开源、免费、跨平台、安全性、成本低、支持各种开发语言、支持强大的内置函数、数据存储量大?
Mysql性能调优
分区:把一个表的数据分成N多个区块,分区后还是一张表,需要一个分区键,不是分区键会扫描所有分区
作用:提升数据库的访问性能
适用:平时访问量不是特别大,表结构变更也不多,而且历史数据访问量低下,可能会做成分区表,这样平时基本上只要访问最近的分区段,还有利于老数据的清理。
分区类型
range分区:基于一个给定的连续区间范围(区间要求连续并且不能重叠),把数据分配到不同的分区
list分区:类似于range分区,区别在于list分区是居于枚举出的值列表分区,range是基于给定的连续区间范围分区
hash分区:基于给定的分区个数,把数据分配到不同的分区
key分区:类似于hash分区
注意:无论哪种分区,要么你分区表上没有主键/唯一键,要么分区表的主键/唯一键都必须包含分区键,也就是说不能使用主键/唯一键字段之外的其它字段分区。
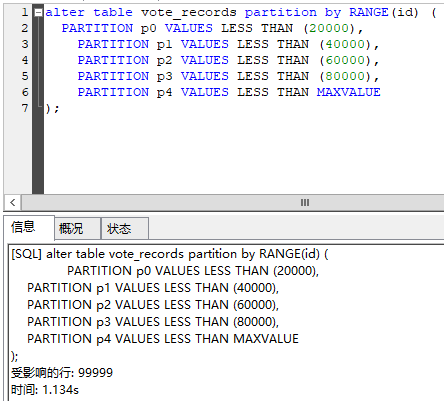
创建表时创建分区:
-- 创建分区表
CREATE TABLE `tbl_user_part` (
`id` int(11) NOT NULL ,
`username` varchar(255) DEFAULT NULL,
`email` varchar(20) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`type` int(11) DEFAULT NULL, `create_time` datetime DEFAULT CURRENT_TIMESTAMP -- PRIMARY KEY (`id`,`age`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 PARTITION BY RANGE (age) ( PARTITION p0 VALUES LESS THAN (20), PARTITION p1 VALUES LESS THAN (40), PARTITION p2 VALUES LESS THAN (60), PARTITION p3 VALUES LESS THAN (80), PARTITION p4 VALUES LESS THAN MAXVALUE );
表结构:
创建表后创建分区:


https://blog.csdn.net/vbirdbest/article/details/82461109
分表:把一张表分成多个表。
作用:提升数据库的访问性能。
适用:数据量非常大,而且访问上没有绝对的热点,基本上所有数据都会被访问到。
分库:把一个数据库分成多个数据库
作用:提升数据库的访问性能。
Mysql运行监控
Mysql备份与恢复
备份1
Mysql导入、导出。导出 mysqldump,
mysqldump -uroot -p examol vote_records>D:/vote_records.sql 一定不能加分号!!!要在bin下面执行, 不是Mysql里!!!

导入 source,先 use database; 选择导入的数据库,
source D:/Program Files/feiq/Recv Files/vote_records/vote_records.sql; 导入数据。
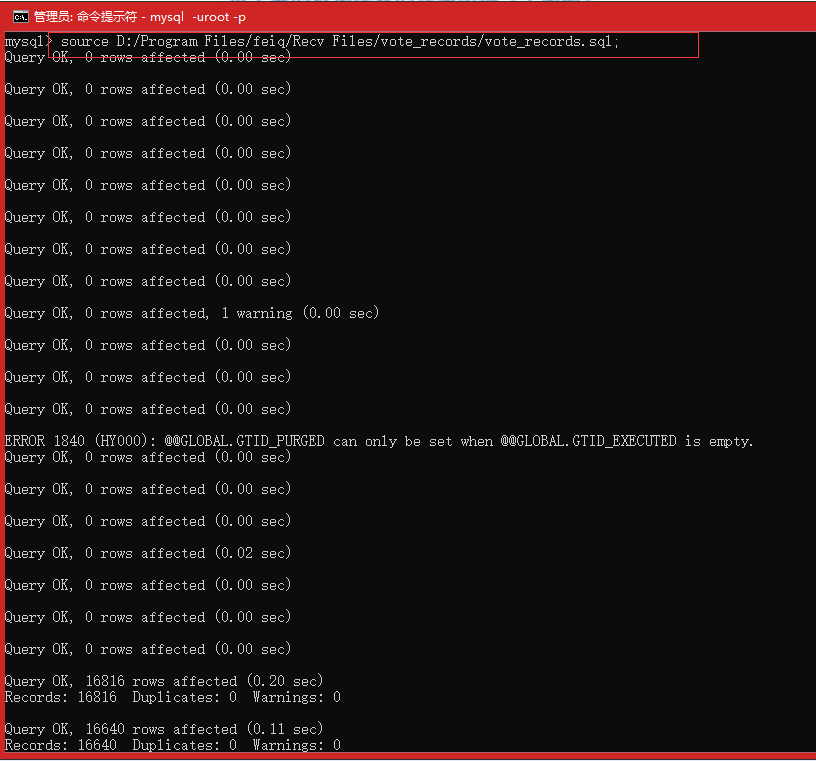
还原:

https://www.cnblogs.com/tonnytangy/p/7779164.html

Mysql主从复制与读写分离
要求:
1.主库、版本一致
2.主库中的日志备份,从库日志还原增量
3.主库产生增量日志,从库同步增量日志
步骤:
1.p34=