目录
常见模板题(不仅仅有模板,还有一些好题,当然也有水题orz)
Tags:Oi,信息学,题解
-1.前言
这个小文章(其实也不算小了) 囊括了近一段时间以来我所做的一些具有代表性的题目,有一些很难,有一些只是简单的小板子,不管怎么着,我看着爽就完事了(洛谷的markdown不支持[toc],差评)
0.快读
这个东西应该很多人用吧,我一直都在用scanf(),但看到别人都在用read(),我也想整一个
#define ll long long
int/*(ll)*/ read()//简单的快读(使用了某种特殊stl的版本)
{
int X=0,w=0;char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) X=(X<<3) +(X<<1)+(ch^48),ch=getchar();
return w?-X:X;
}
inline int/*ll*/ read()//常见的通用版本
{
int x=0,f=1;char ch=getchar();
while (ch<48 ||ch>57) { if(ch=='-') f=-1;ch=getchar(); }
while (ch>=48 && ch<=57) {x=x*10+ch-48;ch=getchar(); }return x*f;
}1.线段树模板
1.P3372 【模板】线段树 1
//题目:洛谷-线段树-1
//date:2019-10-30
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+5;
#define lson (root<<1)//定义左儿子,编号为root*2(root<<1)
#define rson ((root<<1)|1) //定义右儿子,编号为(root*2)+1((root<<1)|1)
//使用位运算,提高运算的效率
int n,m,k,cnt;
long long a[maxn],res,lazy[4*maxn],sum[4*maxn];//lazytag懒标记
void build(int root,int l,int r)//构建线段树(递归法)
{
if(l==r){sum[root]=a[l];return;};//如果l==r,那么这就是叶子节点
int mid=(l+r)/2;
build(lson,l,mid);//构建左子树
build(rson,mid+1,r);//构建右子树
sum[root]=sum[lson]+sum[rson];//节点的权值等于左子树的权值加右子树的权值
}
void down(int root,int l,int r)//push_down,将懒标记将要执行的操作传递下去
{
if(!lazy[root]) return;
int mid=(l+r)/2;
sum[lson]+=(mid-l+1)*lazy[root];
sum[rson]+=(r-mid)*lazy[root];
lazy[lson]+=lazy[root];
lazy[rson]+=lazy[root];
lazy[root]=0; //当把操作传递给儿子节点之后,root节点的lazytag清零
}
void query(int root,int l,int r,int x,int y)//询问操作
{
if(x<=l&&y>=r) {res+=sum[root];return;}//如果查询的x,y超过了边界,就返回
down(root,l,r);
int mid=(l+r)/2;
if(x<=mid) query(lson,l,mid,x,y);
if(y>=mid+1) query(rson,mid+1,r,x,y);
//分块思想,递归查询
}
void updata(int root,int l,int r,int x,int y,int data)
{
if(x<=l&&y>=r)
{
sum[root]+=(r-l+1)*data;
lazy[root]+=data;
return;
}//如果查询超过了边界,就更新
down(root,l,r);
int mid=(l+r)/2;
if(x<=mid) updata(lson,l,mid,x,y,data);
if(y>=mid+1) updata(rson,mid+1,r,x,y,data);
sum[root]=sum[lson]+sum[rson];
}
inline void init()
{
cin>>n>>m;
for(int i=1;i<=n;++i)
{
scanf("%lld",&a[i]);
}
build(1,1,n);
for(int i=1;i<=m;++i)
{
int k,a,b,c;
scanf("%d",&k);
if(k==1)
{
scanf("%d%d%d",&a,&b,&c);
updata(1,1,n,a,b,c);
}
else
{
scanf("%d%d",&a,&b);
res=0;
query(1,1,n,a,b);
cout<<res<<endl;
}
}
}
int main()
{
init();
return 0;
}对于这道题来说,最主要的是实现了线段树的构建、区间查找和区间操作(加法)。
如果说有什么具体的思想的话,就是分块的思想。
2.P3373 【模板】线段树 2
与上面一题最主要的不同,是区间乘法
#include <iostream>
#include <cstdio>
using namespace std;
int p;
long long a[100007];
struct node{
long long v, mul, add;
}st[400007];
void bt(int root, int l, int r){
st[root].mul=1;
st[root].add=0;
if(l==r){
st[root].v=a[l];
}
else{
int m=(l+r)/2;
bt(root*2, l, m);
bt(root*2+1, m+1, r);
st[root].v=st[root*2].v+st[root*2+1].v;
}
st[root].v%=p;
return ;
}
void pushdown(int root, int l, int r){
int m=(l+r)/2;
st[root*2].v=(st[root*2].v*st[root].mul+st[root].add*(m-l+1))%p;
st[root*2+1].v=(st[root*2+1].v*st[root].mul+st[root].add*(r-m))%p;
st[root*2].mul=(st[root*2].mul*st[root].mul)%p;
st[root*2+1].mul=(st[root*2+1].mul*st[root].mul)%p;
st[root*2].add=(st[root*2].add*st[root].mul+st[root].add)%p;
st[root*2+1].add=(st[root*2+1].add*st[root].mul+st[root].add)%p;
st[root].mul=1;
st[root].add=0;
return ;
}
void ud1(int root, int stdl, int stdr, int l, int r, long long k){
if(r<stdl || stdr<l){
return ;
}
if(l<=stdl && stdr<=r){
st[root].v=(st[root].v*k)%p;
st[root].mul=(st[root].mul*k)%p;
st[root].add=(st[root].add*k)%p;
return ;
}
pushdown(root, stdl, stdr);
int m=(stdl+stdr)/2;
ud1(root*2, stdl, m, l, r, k);
ud1(root*2+1, m+1, stdr, l, r, k);
st[root].v=(st[root*2].v+st[root*2+1].v)%p;
return ;
}
void ud2(int root, int stdl, int stdr, int l, int r, long long k){
if(r<stdl || stdr<l){
return ;
}
if(l<=stdl && stdr<=r){
st[root].add=(st[root].add+k)%p;
st[root].v=(st[root].v+k*(stdr-stdl+1))%p;
return ;
}
pushdown(root, stdl, stdr);
int m=(stdl+stdr)/2;
ud2(root*2, stdl, m, l, r, k);
ud2(root*2+1, m+1, stdr, l, r, k);
st[root].v=(st[root*2].v+st[root*2+1].v)%p;
return ;
}
long long query(int root, int stdl, int stdr, int l, int r){
if(r<stdl || stdr<l){
return 0;
}
if(l<=stdl && stdr<=r){
return st[root].v;
}
pushdown(root, stdl, stdr);
int m=(stdl+stdr)/2;
return (query(root*2, stdl, m, l, r)+query(root*2+1, m+1, stdr, l, r))%p;
}
int main(){
int n, m;
scanf("%d%d%d", &n, &m, &p);
for(int i=1; i<=n; i++){
scanf("%lld", &a[i]);
}
bt(1, 1, n);
while(m--){
int chk;
scanf("%d", &chk);
int x, y;
long long k;
if(chk==1){
scanf("%d%d%lld", &x, &y, &k);
ud1(1, 1, n, x, y, k);
}
else if(chk==2){
scanf("%d%d%lld", &x, &y, &k);
ud2(1, 1, n, x, y, k);
}
else{
scanf("%d%d", &x, &y);
printf("%lld\n", query(1, 1, n, x, y));
}
}
return 0;
}
2.前缀和&差分
1.P1083 借教室
这是一道非常经典的真题、模板题
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e6+5;
#define ll long long
int n,m,x=-1;
int a[maxn],vis[maxn],c[maxn],r[maxn],l[maxn];
ll sum,got[maxn];
bool flag=true;
void init()
{
cin>>n>>m;
for(int i=1;i<=n;++i)
{
cin>>a[i];
}
for(int i=1;i<=m;++i)
{
scanf("%d%d%d",&c[i],&l[i],&r[i]);
got[l[i]]+=c[i];
got[r[i]+1]-=c[i];
}
}
int main()
{
init();
int j=m;
for(int i=1;i<=n;++i)
{
sum+=got[i];
if(sum>a[i])
{
while(sum>a[i])
{
got[l[j]]-=c[j];
got[r[j]+1]+=c[j];
if(l[j]<=i&&i<=r[j])
sum-=c[j];
j--;
}
if(flag) x=j,flag=false;
else x=min(x,j);
}
}
if(x==-1) cout<<"0";
else cout<<"-1"<<endl<<x+1;
return 0;
}这个题目的正解就是使用差分数组来维护的,不如就从新开始了解一下差分and前缀和
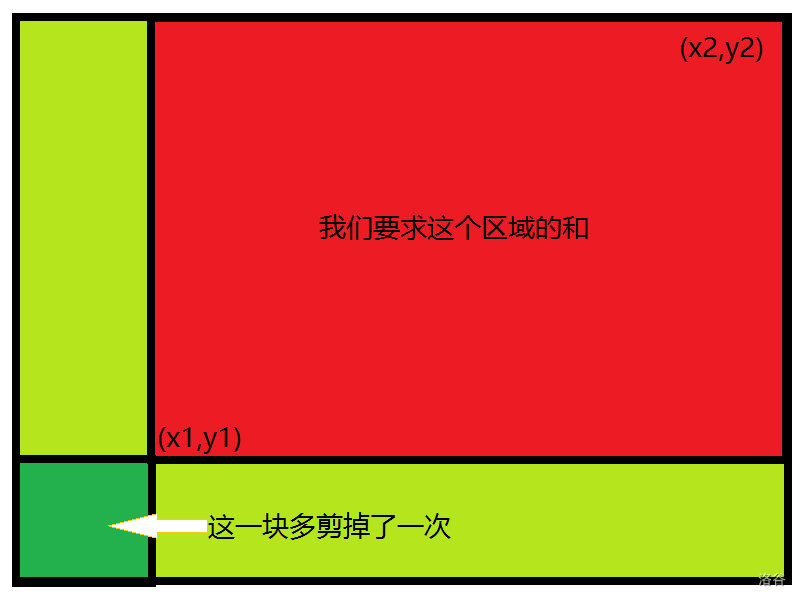
显然,如果想要取得$ans $只需要$ans=s[x_2][y_2]-s[x_1][y_2]-s[x_2][y_1]+s[x_1][y_1]$ 这就是二维前缀和的实现方法
当然,一维前缀和也是同样的道理,$ans=s[x_2]-s[x_1]$
那么对于前缀和这种高效的东西,如果直接枚举区间,不免会tle,所以我们必须找到一种同样高效的算法来维护前缀和--差分
比如,对于一个区间,执行add(l,r,k) 也就是从$a[l]-a[r]$ 所有的数+1
这时候我们就需要一个辅助数组c[maxn]用来记录某一个位置上总的改变量,只需要这样记录:
c[l]+=k;
c[r+1]-=k当所有的操作全部都记录完之后,对c求前缀和,就可以得到某一个特定位置上的操作
//下面的精彩操作来自于csdn
1 9 2 8 3 7 4 6 5
tag: 0 0 0 0 0 0 0 0 0 // 现在还没有打上标记
现在,我们将第 3 个数到第 5 个数加上 2.
那我们就发现,可以把第 3 个数开始把后面所有的数加上 2,再从第 6 个数开始把后面所有数减去 2 呢,就相当于把第 3 个数到第 5 个数加上 2 了。
然后这么标记:
a[i]: 1 9 2 8 3 7 4 6 5
tag : 0 0 2 0 0 -2 0 0 0 // 打上标记*1
请注意,如果我们还是一个一个打上标记,这个算法就会退化。
所以,我们将第一个数打上标记,末尾打上相反标记,然后最后用前缀和处理。
然后,我们再将第 4 个数到第 8 个数减去 1.
按照上面的想法,我们可以从第 4 个数开始把后面所有的数减去 1,在从第 9 个数开始把后面所有的数加上 1.
a[i]: 1 9 2 8 3 7 4 6 5
tag : 0 0 2 -1 0 -2 0 0 1 // 打上标记*2
假设指令执行结束,那么我们这样求和:
用一个 sum 数组记录,sumi 代表前 i 个数所带的 tag 的和。(即前缀和)
a[i] : 1 9 2 8 3 7 4 6 5
tag : 0 0 2 -1 0 -2 0 0 1
sum[i] : 0 0 2 1 1 -1 -1 -1 0
最后,我们把 ai 加上对应的 sumi,就是答案了。
时间复杂度 O(n).其实在这种做法最巧妙的(我自己感觉),就是对于辅助数组c求前缀和,并且在c[l]和c[r+1]上采取+-操作,这种算法并不难懂,但完整严谨的数学证明咱也知不道,咱也不敢问嗷
数据结构篇
1.树形数据结构
1.P1030 求先序排列
题目描述
给出一棵二叉树的中序与后序排列。求出它的先序排列。(约定树结点用不同的大写字母表示,长度≤8)。
输入格式
2行,均为大写字母组成的字符串,表示一棵二叉树的中序与后序排列。
输出格式
1行,表示一棵二叉树的先序。
首先要知道的是后根遍历(后序)就是优先输出树的根,中根遍历(后序)就是优先输出根节点
//也就是说我们只要根据这两点重构整个树,然后输出就完事了(其实这种说法不见得正确)
从树的性质我们可以知道后序遍历的最后一个节点肯定是根节点
然后对于中序遍历,前半部分是一颗子树,后半部分也是一棵子树
然后就是简单的搜索(bushi
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+5;
int len=0;
char a[1001],b[1001];
/*void find_tree(int x,int y)//被注释掉的代码不知道为什么莫名其妙的过不了样例,应该是if(c)的问题
{
int f,c=0;
if(x>y) return;
for(int i=strlen(a)-1;i>0;i--)
{
for(int j=x;j<=y;++j)
{
if(a[j]==b[i])
{
c=j;
break;
}
if(c) break;
}
}
cout<<a[c];
find_tree(x,c-1);
find_tree(c+1,y);
}*/
inline int find(char ch)
{
for(int i=0;i<len;++i)
{
if(a[i]==ch) return i;
}
}
void dfs(int l,int r,int x,int y)
{
int m=find(b[y]);
cout<<b[y];
if(m>l)/*有左子树,继续向下推进*/dfs(l,m-1,x,y-r+m-1);//r-m就是左子树的节点数
if(m<r)/*有右子树*/dfs(m+1,r,x+m-l,y-1);//m-l就是右子树的节点数
}
int main()
{
scanf("%s",a);
scanf("%s",b);
//find_tree(0,strlen(a)-1);
len=strlen(a);
dfs(0,len-1,0,len-1);
return 0;
}1.后序遍历中,最后一个节点一定是根节点(对于每一颗子树也成立);
2.既然这题要求先序遍历,那么我们只需一次输出访问的父节点即可;
这样的话,我们只要递归将一棵大树分成两颗子树,让后找他们的父节点,不断递归输出;
3.那么难点就在这了,如何通过一个中序和后序遍历中找出两段子树的后序遍历序列(后序,因为只有后序我们才方便找到父节点)呢?
自己可以拿几个样例做一做,耐性点就会发现它的套路,我这里简单说一下:
在中序遍历中找到当前父节点后,我们可以分别求出他的左子树节点数和右子树节点数,因为中序遍历访问的顺序是左子树,父节点,右子树,所以可以直接计算出;
然后,由于我们对结点的访问一定是先访问一颗子树,在访问另一颗,所以在我们的原后序遍历串右边界中减掉右子树节点个数再减一即为新的左子树右边界,在原后序遍历串左边界加上左子树节点个数即为新的右子树左边界;
当然右子树右边界和左子树左边界这个非常好确定,就不在多说,自己看代码吧
疯狂的搜索篇
1.简单(并不)的dfs们
1.P1074 靶形数独
小城和小华都是热爱数学的好学生,最近,他们不约而同地迷上了数独游戏,好胜的他们想用数独来一比高低。但普通的数独对他们来说都过于简单了,于是他们向 Z 博士请教,Z 博士拿出了他最近发明的“靶形数独”,作为这两个孩子比试的题目。
靶形数独的方格同普通数独一样,在 9 格宽×9 格高的大九宫格中有9 个 3 格宽×3 格高的小九宫格(用粗黑色线隔开的)。在这个大九宫格中,有一些数字是已知的,根据这些数字,利用逻辑推理,在其他的空格上填入 1 到 9的数字。每个数字在每个小九宫格内不能重复出现,每个数字在每行、每列也不能重复出现。但靶形数独有一点和普通数独不同,即每一个方格都有一个分值,而且如同一个靶子一样,离中心越近则分值越高。(如图)
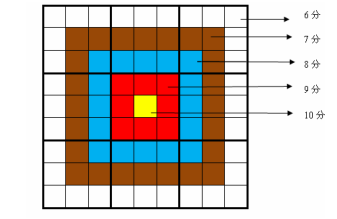
上图具体的分值分布是:最里面一格(黄色区域)为 10 分,黄色区域外面的一圈(红色区域)每个格子为9分,再外面一圈(蓝色区域)每个格子为8 分,蓝色区域外面一圈(棕色区域)每个格子为7分,最外面一圈(白色区域)每个格子为6分,如上图所示。比赛的要求是:每个人必须完成一个给定的数独(每个给定数独可能有不同的填法),而且要争取更高的总分数。而这个总分数即每个方格上的分值和完成这个数独时填在相应格上的数字的乘积的总和
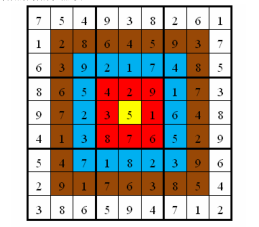
总分数即每个方格上的分值和完成这个数独时填在相应格上的数字的乘积的总和。如图,在以下的这个已经填完数字的靶形数独游戏中,总分数为 2829。游戏规定,将以总分数的高低决出胜负。
由于求胜心切,小城找到了善于编程的你,让你帮他求出,对于给定的靶形数独,能够得到的最高分数。
一共 9 行。每行9个整数(每个数都在 0−9 的范围内),表示一个尚未填满的数独方格,未填的空格用“0”表示。每两个数字之间用一个空格隔开。
其实不用想都知道这个题可以爆搜
这个题曾经是我的一个梦魇,在某一场模拟赛中我调了1h30min结果爆零,然后心态爆炸,今天把他拾起来重新看一看
#include<bits/stdc++.h>
using namespace std;
struct NEED{int row,cnt;}need[10];
int ans=-1,chess[10][10],have,em[100][10],tot;
bool row[10][10],lis[10][10],check[10][10]; //行、列、宫格
int point(int,int);
int askch(int,int);
void dfs(int,int);
bool cmp(NEED,NEED);
int main(){
register int i,j;
for(i=1;i<=9;++i)
for(j=1;j<=9;++j){
cin>>chess[i][j];
row[i][chess[i][j]] = lis[j][chess[i][j]] = check[askch(i,j)][chess[i][j]]=1;
if(!chess[i][j]) need[i].row=i,++need[i].cnt;//非零就不存储到搜索数组s中,但将这个点的值在其所在行、列、宫中标记 ,计算加分
else have+=point(i,j)*chess[i][j];
}
sort(need+1,need+10,cmp);//排序一下
for(i=1;i<=9;++i)
for(j=1;j<=9;++j)
if(!chess[need[i].row][j])
em[++tot][0]=need[i].row,em[tot][1]=j,em[tot][2]=askch(need[i].row,j),em[tot][3]=point(need[i].row,j);
dfs(1,have);
cout<<ans;
return 0;
}
void dfs(int step,int score){
if(step==tot+1){
ans=ans<score ? score : ans;
return;
}
for(int i=1;i<=9;++i)
if(!row[em[step][0]][i] && !lis[em[step][1]][i] && !check[em[step][2]][i])/*判断能不能把i填入*/{
row[em[step][0]][i]=lis[em[step][1]][i]=check[em[step][2]][i]=1;//如果能搞,就标记一下
dfs(step+1,score+i*em[step][3]);//下一层递归
row[em[step][0]][i]=lis[em[step][1]][i]=check[em[step][2]][i]=0;//回溯
}
}
int askch(int i,int j){
if(i>=1 && i<=3){
if(j>=1 && j<=3) return 1;
if(j>=4 && j<=6) return 2;
return 3;
}
if(i>=4 && i<=6){
if(j>=1 && j<=3) return 4;
if(j>=4 && j<=6) return 5;
return 6;
}
if(j>=1 && j<=3) return 7;
if(j>=4 && j<=6) return 8;
return 9;
}
int point(int i,int j){
if(j==1 || j==9 || i==1 || i==9) return 6;
if(i==2 || i==8 || j==2 || j==8) return 7;
if(i==3 || i==7 || j==3 || j==7) return 8;
if(i==4 || i==6 || j==6 || j==4) return 9;
if(i==5 || j==5) return 10;
}
bool cmp(NEED x,NEED y){return x.cnt<y.cnt;}//重载算符2.P1433 吃奶酪
房间里放着n块奶酪。一只小老鼠要把它们都吃掉,问至少要跑多少距离?老鼠一开始在(0,0)点处。
第一行一个数n (n<=15)
接下来每行2个实数,表示第i块奶酪的坐标。
两点之间的距离公式=sqrt((x1-x2)+(y1-y2))
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define rep(i,j) for(int i=1;i<=j;++i)
const int maxn=1e5+5;
int n,pos[50][50],vis[50];
double ans=1234567890.0,len[50][50];
struct node
{
double x,y;
}e[maxn];
inline void init()
{
cin>>n;
for(int i=1;i<=n;++i)
{
double x,y;
scanf("%lf%lf",&x,&y);
e[i].x=x;
e[i].y=y;
}
for(int i=0;i<=n;++i)
{
for(int j=0;j<=n;++j)
{
if(i==j) len[i][j]=0;
else
{
len[i][j]=sqrt((e[i].x-e[j].x)*(e[i].x-e[j].x)+(e[i].y-e[j].y)*(e[i].y-e[j].y));//预处理各个节点之间的距离
}
}
}
}
void dfs(int point,int step,double lenth)
{
if(lenth>ans) return;//没有继续下去的必要了
if(step==n)//刚好读完
{
ans=min(ans,lenth);//ans取最小(也相当于是一个最后一步的特判
return;
}
for(int i=1;i<=n;++i)
{
if(!vis[i])
{
vis[i]=1;//标记走过
dfs(i,step+1,lenth+len[point][i]);//从这个节点继续往下搜
vis[i]=0;//回溯
}
}
}
int main()
{
init();
dfs(0,0,0.0);//从坐标系的原点(0,0)开始搜,初始距离是0
printf("%.2lf",ans);//结果保留到小数点后两位
return 0;
}
这个题还用想蛮?一个普及-,直接爆搜就行了,详情看代码和注释
2.大搜索,小模拟
P1312 Mayan游戏
Mayan puzzle是最近流行起来的一个游戏。游戏界面是一个7 行×5列的棋盘,上面堆放着一些方块,方块不能悬空堆放,即方块必须放在最下面一行,或者放在其他方块之上。游戏通关是指在规定的步数内消除所有的方块,消除方块的规则如下:
1 、每步移动可以且仅可以沿横向(即向左或向右)拖动某一方块一格:当拖动这一方块时,如果拖动后到达的位置(以下称目标位置)也有方块,那么这两个方块将交换位置(参见输入输出样例说明中的图6到图7 );如果目标位置上没有方块,那么被拖动的方块将从原来的竖列中抽出,并从目标位置上掉落(直到不悬空,参见下面图1 和图2);

2 、任一时刻,如果在一横行或者竖列上有连续三个或者三个以上相同颜色的方块,则它们将立即被消除(参见图1 到图3)。
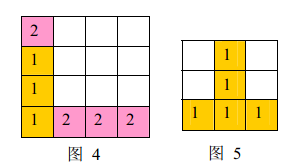
注意:
a) 如果同时有多组方块满足消除条件,几组方块会同时被消除(例如下面图4 ,三个颜色为1 的方块和三个颜色为 22 的方块会同时被消除,最后剩下一个颜色为2的方块)。
b) 当出现行和列都满足消除条件且行列共享某个方块时,行和列上满足消除条件的所有方块会被同时消除(例如下面图5 所示的情形,5 个方块会同时被消除)。
3 、方块消除之后,消除位置之上的方块将掉落,掉落后可能会引起新的方块消除。注意:掉落的过程中将不会有方块的消除。
上面图1 到图 3 给出了在棋盘上移动一块方块之后棋盘的变化。棋盘的左下角方块的坐标为(0, 0 ),将位于(3, 3 )的方块向左移动之后,游戏界面从图 1 变成图 2 所示的状态,此时在一竖列上有连续三块颜色为4 的方块,满足消除条件,消除连续3 块颜色为4 的方块后,上方的颜色为3 的方块掉落,形成图 3 所示的局面。
对于这道题,不得不承认,他很难,但我也知道,这确实是个搜索
#include<bits/stdc++.h>
using namespace std;
namespace wpp_jkw//命名空间,可以再比赛中有效防止ce
{
const int maxn=1e4+5;
int n,pos[8][8],ans[15][15],last[15][15][15],del[15][15];
int read()
{
int X=0,w=0;char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) X=(X<<3) +(X<<1)+(ch^48),ch=getchar();
return w?-X:X;
}
bool remove()
{
int flag=0;
for(int i=1;i<=5;++i)
{
for(int j=1;j<=7;++j)
{
if(i-1>=1&&i+1<=5&&pos[i][j]==pos[i-1][j]&&pos[i][j]==pos[i+1][j]&&pos[i][j])
{
del[i-1][j]=1;
del[i][j]=1;
del[i+1][j]=1;
flag=1;
}
if(j-1>=1&&j+1<=7&&pos[i][j]==pos[i][j+1]&&pos[i][j]==pos[i][j-1]&&pos[i][j])
{
del[i][j]=1;
del[i][j+1]=1;
del[i][j-1]=1;
flag=1;
}
}
}
if(!flag) return 0;
for(int i=1;i<=5;++i)
{
for(int j=1;j<=7;++j)
{
if(del[i][j])
{
del[i][j]=0;
pos[i][j]=0;
}
}
}
return 1;
}
bool check()
{
for(int i=1;i<=5;++i)
{
if(pos[i][1]) return 0;
}
return 1;
}
void copy(int x)//回溯时有大用处
{
int qaq=0;
for(int i=1;i<=5;++i)
{
for(int j=1;j<=7;++j)
{
last[x][i][j]=pos[i][j];
}
}
}
void updata()
{
for(int i=1;i<=5;++i)
{
int qaq=0;
for(int j=1;j<=7;++j)
{
if(!pos[i][j]) qaq++;
else
{
if(!qaq) continue;
pos[i][j-qaq]=pos[i][j];
pos[i][j]=0;
}
}
}
}
void move(int i,int j,int x)
{
int tmp=pos[i][j];
pos[i][j]=pos[i+x][j];
pos[i+x][j]=tmp;
updata();
while(remove()) updata();
}
void dfs(int x)
{
if(check())
{
for(int i=1;i<=n;++i)
{
if(i!=1) printf("\n");
for(int j=1;j<=3;++j)
{
printf("%d ",ans[i][j]);
}
}
exit(0);
}
if(x==n+1) return;
copy(x);
for(int i=1;i<=5;++i)
{
for(int j=1;j<=7;++j)
{
if(pos[i][j])
{
if(i+1<=5&&pos[i][j]!=pos[i+1][j])
{
move(i,j,1);
ans[x][1]=i-1;
ans[x][2]=j-1;
ans[x][3]=1;
dfs(x+1);
for(int i=1;i<=5;++i)
{
for(int j=1;j<=7;++j)
{
pos[i][j]=last[x][i][j];
}
}
ans[x][1]=-1;ans[x][2]=-1;ans[x][3]=-1;
}
if(i-1>=1&&pos[i-1][j]==0)
{
move(i,j,-1);
ans[x][1]=i-1;
ans[x][2]=j-1;
ans[x][3]=-1;
dfs(x+1);
for(int i=1;i<=5;++i)
{
for(int j=1;j<=7;++j)
{
pos[i][j]=last[x][i][j];
}
}
ans[x][1]=-1;
ans[x][2]=-1;
ans[x][3]=-1;
}
}
}
}
}
void just_do_it()
{
n=read();
for(int i=1;i<=5;++i)
{
for(int j=1;j<=8;++j)
{
int x=read();
if(x==0) break;
pos[i][j]=x;
}
}
memset(ans,-1,sizeof(ans));
dfs(1);
puts("-1");
}
}
int main()
{
wpp_jkw::just_do_it();
return 0;
}
3.递推/递推+贪心
(众所周知,bfs也算递推)
1. P1315 观光公交

#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+5;
#define ll long long
#define rep(i,j,k) for(int i=j;i<=k;++i)
namespace wpp_jkw
{
ll n,m,k,dis[maxn],d[maxn],ans=0;
struct node{ll start,end;}e[maxn];
struct station{ll arrive,off,lastest;}sta[maxn];
ll read()//简单的快读
{
ll X=0,w=0;char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) X=(X<<3) +(X<<1)+(ch^48),ch=getchar();
return w?-X:X;
}
void init()
{
n=read();m=read();k=read();
rep(i,1,n-1) dis[i]=read();
ll t;
rep(i,1,m)
{
e[i].start=read();t=read();e[i].end=read();
sta[t].lastest=max(sta[t].lastest,e[i].start);
sta[e[i].end].off++;
}
}
ll time=0;
void work()
{
rep(i,1,n)
{
sta[i].arrive=time;
time=max(sta[i].lastest,time);
time+=dis[i];
}
int max_n,max_pos,temp;
while(k--)
{
max_n=0;
rep(i,2,n)
{
if(!dis[i-1]) continue;
temp=0;
for(int j=i;j<=n;++j)
{
temp+=sta[j].off;
if(sta[j].arrive<=sta[j].lastest) break;
}
if(temp>max_n)
{
max_n=temp;
max_pos=i;
}
}
dis[max_pos-1]--;
rep(i,max_pos,n)
{
sta[i].arrive--;
if(sta[i].arrive<sta[i].lastest) break;
}
}
rep(i,1,m)
{
ans+=sta[e[i].end].arrive-e[i].start;
}
}
void wpp_main()
{
init();
work();
cout<<ans;
}
}
int main()
{
wpp_jkw::wpp_main();
return 0;
} 简单模拟
1.P1328 生活大爆炸版石头剪刀布
石头剪刀布是常见的猜拳游戏:石头胜剪刀,剪刀胜布,布胜石头。如果两个人出拳一 样,则不分胜负。在《生活大爆炸》第二季第8集中出现了一种石头剪刀布的升级版游戏。
升级版游戏在传统的石头剪刀布游戏的基础上,增加了两个新手势:
斯波克:《星际迷航》主角之一。
蜥蜴人:《星际迷航》中的反面角色。
这五种手势的胜负关系如表一所示,表中列出的是甲对乙的游戏结果。
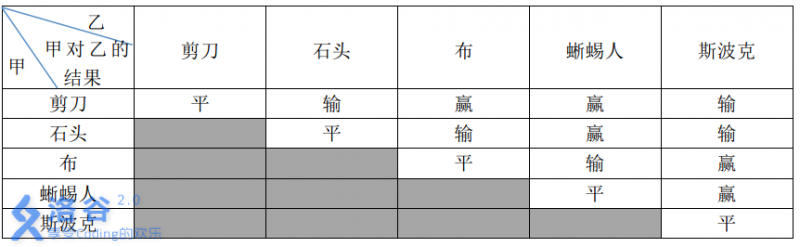
现在,小 A和小 B尝试玩这种升级版的猜拳游戏。已知他们的出拳都是有周期性规律的,但周期长度不一定相等。例如:如果小A以“石头-布-石头-剪刀-蜥蜴人-斯波克”长度为 66 的周期出拳,那么他的出拳序列就是“石头-布-石头-剪刀-蜥蜴人-斯波克-石头-布-石头-剪刀-蜥蜴人-斯波克-......”,而如果小B以“剪刀-石头-布-斯波克-蜥蜴人”长度为 5 的周期出拳,那么他出拳的序列就是“剪刀-石头-布-斯波克-蜥蜴人-剪刀-石头-布-斯波克-蜥蜴人-......”
已知小 A和小 B 一共进行 N 次猜拳。每一次赢的人得 1 分,输的得 0 分;平局两人都得 0 分。现请你统计 N 次猜拳结束之后两人的得分。
第一行包含三个整数:$N,N_A,N_B$,分别表示共进行 N 次猜拳、小 A出拳的周期长度,小 B 出拳的周期长度。数与数之间以一个空格分隔。
第二行包含 $N_A$ 个整数,表示小 A出拳的规律,第三行包含 $N_B$ 个整数,表示小 B 出拳的规律。其中,0 表示“剪刀”,1 表示“石头”,2 表示“布”,3 表示“蜥蜴人”,4表示“斯波克”。数与数之间以一个空格分隔。
输出一行,包含两个整数,以一个空格分隔,分别表示小 A、小 B的得分。
真的就是简单的模拟,不信你看代码(雾
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define rep(i,j) for(int i=1;i<=j;++i)
const int maxn=1e4;
int n,na,nb,sca=0,scb=0;
int xa[maxn],xb[maxn];
inline void init()
{
cin>>n>>na>>nb;
for(int i=1;i<=na;++i)
{
cin>>xa[i];
}
for(int i=1;i<=nb;++i)
{
cin>>xb[i];
}
}
void work()
{
int i=0,j=0;
for(int k=1;k<=n;++k)
{
i++,j++;
if(i>na) i=1;//当超过循环边界后,让他再滚回来
if(j>nb) j=1;
if(xa[i]==0&&xb[j]==1)scb++;//真的就是大模拟嗷
if(xa[i]==0&&xb[j]==2)sca++;
if(xa[i]==0&&xb[j]==3)sca++;
if(xa[i]==0&&xb[j]==4)scb++;
if(xa[i]==1&&xb[j]==0)sca++;
if(xa[i]==1&&xb[j]==2)scb++;
if(xa[i]==1&&xb[j]==3)sca++;
if(xa[i]==1&&xb[j]==4)scb++;
if(xa[i]==2&&xb[j]==0)scb++;
if(xa[i]==2&&xb[j]==1)sca++;
if(xa[i]==2&&xb[j]==3)scb++;
if(xa[i]==2&&xb[j]==4)sca++;
if(xa[i]==3&&xb[j]==0)scb++;
if(xa[i]==3&&xb[j]==1)scb++;
if(xa[i]==3&&xb[j]==2)sca++;
if(xa[i]==3&&xb[j]==4)sca++;
if(xa[i]==4&&xb[j]==0)sca++;
if(xa[i]==4&&xb[j]==1)sca++;
if(xa[i]==4&&xb[j]==2)scb++;
if(xa[i]==4&&xb[j]==3)scb++;
}
}
int main()
{
init();
work();
cout<<sca<<" "<<scb;//输出得分
return 0;
}想不到这个题居然是普及boss站的题目
2.P1498 南蛮图腾
(其实这道题正解是分治)
模拟就完事了,其实也算是变相的打标,每一次都把上一层的向下向左复制一下
然后再小推一下转移方程
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define rep(i,j,k) for(int i=j;i<=k;++i)
namespace wpp_
{
int n;
int h,l;
char c[3005][3005];
void copy_r()
{
for(int i=1;i<=h;++i)
{
for(int j=1;j<=l;++j)
{
c[i][l+j]=c[i][j];
}
}
}
void copy_d()
{
for(int i=1;i<=h;++i)
{
for(int j=1;j<=l;++j)
{
c[h+i][(l/2)+j]=c[i][j];
}
}
}
void wpp_main()
{
for(int i=1;i<=3000;++i)
{
for(int j=1;j<=3000;++j)
{
c[i][j]=' ';
}
}
cin>>n;
c[1][2]=c[1][3]='_';
c[1][1]=c[2][2]='\\';
c[1][4]=c[2][3]='/';
h=2;l=4;
for(int i=2;i<=n;++i)
{
copy_r();
copy_d();
h*=2;
l*=2;
}
for(int i=h;i>=1;i--)
{
for(int j=l;j>=1;j--)
{
if(c[i][j]==' ') cout<<" ";
if(c[i][j]=='\\') cout<<"\\";
if(c[i][j]=='/') cout<<"/";
if(c[i][j]=='_') cout<<"_";
}
puts("");
}
}
}
int main()
{
wpp_::wpp_main();
return 0;
}离散化
所谓离散化,就是把无限区间内的有限元素映射到有限的区间内,这样方便操作,且不会爆空间
1.P1908 逆序对
猫猫TOM和小老鼠JERRY最近又较量上了,但是毕竟都是成年人,他们已经不喜欢再玩那种你追我赶的游戏,现在他们喜欢玩统计。最近,TOM老猫查阅到一个人类称之为“逆序对”的东西,这东西是这样定义的:对于给定的一段正整数序列,逆序对就是序列中ai>aj且i<j的有序对。知道这概念后,他们就比赛谁先算出给定的一段正整数序列中逆序对的数目。
第一行,一个数n,表示序列中有n个数。
第二行n个数,表示给定的序列。序列中每个数字不超过$10^9$
输出 给定序列中逆序对的数目。
这个题有两种做法,一种是归并排序,另一种时树状数组,详情看代码注释
归并排序:
#include <bits/stdc++.h>
using namespace std;
const int maxn=5e5+5;
#define ll long long
#define rep(i,j) for(int i=1;i<=j;++i)
namespace wpp_jkw
{
ll n,a[maxn],r[maxn],ans;
int read()//简单的快读
{
int X=0,w=0;char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) X=(X<<3) +(X<<1)+(ch^48),ch=getchar();
return w?-X:X;
}
void init()
{
n=read();
rep(i,n)
{
ll k;
k=read();
a[i]=k;
}
}
void guibing_sort(int x,int y)
{
if(x==y) return;
int mid=(x+y)/2;
guibing_sort(x,mid);guibing_sort(mid+1,y);
int i=x,j=mid+1,k=x;
while(i<=mid&&j<=y)
{
if(a[i]<=a[j]) r[k++]=a[i++];
else r[k++]=a[j++],ans+=(ll)mid-i+1;//求在这个数之前的比他小的数,也就是把他移动之后逆序对减少的个数
}
while(i<=mid) r[k]=a[i],k++,i++;
while(j<=y) r[k]=a[j],k++,j++;
for(int i=x;i<=y;++i)
{
a[i]=r[i];//把暂存数组r[ ]中的元素重新归位
}
}
void do_it()
{
init();
guibing_sort(1,n);
cout<<ans<<endl;
}
}
int main()
{
wpp_jkw::do_it();
return 0;
}
树状数组:
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define rep(i,j,k) for(int i=k;i<=j;++i)
const int maxn=5e5+5;
namespace wpp_jkw
{
struct node{ll id,data,rank;}e[maxn];
bool cmp1(node a,node b){return a.data<b.data;}
bool cmp2(node a,node b){return a.id<b.id;}
ll lowbit(ll x){return x&(-x);}
ll n,a[maxn],r[maxn],ans=0,cnt=0;
ll read()//简单的快读
{
int X=0,w=0;char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) X=(X<<3) +(X<<1)+(ch^48),ch=getchar();
return w?-X:X;
}
inline void init()
{
n=read();
rep(i,n,1)
{
int k;
k=read();
e[i].data=k;
e[i].id=i;
}
}
void update(int x,int y)
{
for(int i=x;i<=maxn;i+=lowbit(i))
{
r[i]+=y;
}
}
ll query(ll x)
{
ll ans=0;
for(ll i=x;i>=1;i-=lowbit(i))
{
ans+=r[i];
}
return ans;
}
void wpp_main()
{
init();
sort(e+1,e+1+n,cmp1);
rep(i,n,1)
{
if(e[i].data!=e[i-1].data)
{
e[i].rank=++cnt;
}
else e[i].rank=cnt;
}
sort(e+1,e+1+n,cmp2);
for(int i=n;i>=1;i--)
{
int val=e[i].rank;
update(val,1);
ans+=query(val-1);
}
cout<<ans;
}
}
int main()
{
wpp_jkw::wpp_main();
return 0;
}2.P1966 火柴排队
这个题其实与上一个题的大体思路和做法是一样的,只不过这个题需要比较两个子串,但离散化后只需要在每一个$pos[ ]$上比较就行了
归并排序:
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+5;
const int p=99999997;
#define ll long long
#define rep(i,j,k) for(int i=k;i<=j;++i)
namespace wpp_jkw
{
ll n,r[maxn],ans,ha[maxn],hb[maxn];
struct node{ll pos,height;}h1[maxn],h2[maxn];
bool operator < (const node &x,const node &y) { return x.height <y.height; }//重载算符
ll read()//简单的快读
{
int X=0,w=0;char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) X=(X<<3) +(X<<1)+(ch^48),ch=getchar();
return w?-X:X;
}
inline void init()
{
n=read();
rep(i,n,1) h1[i].height=read(),h1[i].pos=i;
rep(i,n,1) h2[i].height=read(),h2[i].pos=i;
sort(h1+1,h1+1+n);
sort(h2+1,h2+1+n);
}
void guibing_sort(ll x,ll y)//归并排序
{
if(x==y) return;
ll mid=(x+y)/2;
guibing_sort(x,mid);guibing_sort(mid+1,y);
int i=x,j=mid+1,cnt=x;
while(i<=mid&&j<=y)
{
if(ha[hb[i]]<=ha[hb[j]]) r[cnt++]=hb[i++];
else
{
ans+=mid-i+1;
ans%=p;
r[cnt++]=hb[j++];
}
}
while(i<=mid) r[cnt++]=hb[i++];
while(j<=y) r[cnt++]=hb[j++];
for(int i=x;i<=y;++i) hb[i]=r[i];
}
void wpp_main()
{
init();
rep(i,n,1)
{
hb[h1[i].pos]=i;
ha[i]=h2[i].pos;
}
guibing_sort(1,n);
cout<<ans;
}
}
int main()
{
wpp_jkw::wpp_main();
return 0;
}树状数组:
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define rep(i,j,k) for(int i=j;i<=k;++i)
const int maxn=1e5+5;
const int p=99999998;
namespace wpp_jkw
{
ll read()//简单的快读
{
int X=0,w=0;char ch=0;
while(!isdigit(ch)) {w|=ch=='-';ch=getchar();}
while(isdigit(ch)) X=(X<<3) +(X<<1)+(ch^48),ch=getchar();
return w?-X:X;
}
ll lowbit(ll x) {return x&(-x);}//树状数组需要用到的lowbit优化
struct node{ll data,pos;}a[maxn],b[maxn];
bool cmp(node a,node b){return a.data<b.data;}
ll e[maxn],n,c[maxn],ans;
void add(int x,int t)
{
while(x<=n)
{
e[x]+=t;
e[x]%=p;
x+=lowbit(x);
}
}
int sum(int x)
{
int s=0;
while(x)
{
s+=e[x];
s%=p;
x-=lowbit(x);
}
}
void wpp_main()
{
n=read();
rep(i,1,n)
{
a[i].data=read();
a[i].pos=i;
}
rep(i,1,n)
{
b[i].data=read();
b[i].pos=i;
}
sort(a+1,a+1+n,cmp);
sort(b+1,b+1+n,cmp);
rep(i,1,n)
{
c[a[i].pos]=b[i].pos;//离散化的精髓
}
rep(i,1,n)
{
add(c[i],1);//离散化后pos就是大小,因此不用管数据本身
ans+=i-sum(c[i]);//当前位置减去比他大的数,就是逆序对的个数
ans%=p;
}
cout<<ans<<endl;
}
}
int main()
{
wpp_jkw::wpp_main();
return 0;
}
数论
1.gcd欧几里得算法
欧几里得算法,也叫做辗转相除法
下面展示一种递归的做法
int gcd(int x,int y)
{
if(y==0) return x;
return gcd(y,x%y);
}又或者是循环做法
int gcd(int x,int y)
{
int res=0;
while(y>0)
{
res=x%y;
x=y;
y=res;
}
return x;
}甚至还有我不会用的三目运算符递归
int gcd(int x,int y)
{
return x%y==0:gcd(y,x%y);
}并且,我们还可以知道的是最大公约数和最小公倍数的成乘积就是原来两个数的乘积,根据这个推论,我们可以完成一道题目
P1029 最大公约数和最小公倍数问题
输入$2$个正整数$x_0,y_0(2 \le x_0<100000,2 \le y_0<=1000000)$,求出满足下列条件的$P,Q$的个数
条件:
- $P,Q$是正整数
- 要求$P,Q$以$x_0$为最大公约数,以$y_0$为最小公倍数.
试求:满足条件的所有可能的$2$个正整数的个数.
#include<bits/stdc++.h>
using namespace std;
int p,q,a,b,n,m;
int gcd(int x,int y)
{
if(y==0) return x;
return gcd(y,x%y);
}
int main()
{
cin>>n>>m;
for(int i=1;i<=sqrt(a*b);++i)
{
if((n*m)%i==0&&gcd(i,(n*m)/i)==n) a++;
}
cout<<a*2<<endl;
return 0;
}