首先,如果是从http://lucene.apache.org/solr/下载的solr,基本都是自带集成的jetty服务,不需要单独搭建tomcat环境,但是要注意jdk版本,直接解压通过cmd命令调用bin目录下的solr.cmd -start 来启动
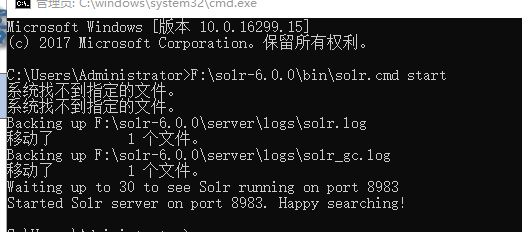
就可以直接通过浏览器访问,默认端口是8983,地址:http://localhost:8983/solr
如果需要集成中文分词器
直接在实例目录下新建lib文件夹,将中文分词器jar复制进去,再修改scahm.xml文件的filetype节点类型就可以。
如:我新建的solr实例名叫new_core,那么就在solr-6.0.0\server\solr\new_core的路径下新建lib文件夹,并把中文分词器的jar复制进去
扫描二维码关注公众号,回复:
7767518 查看本文章

备注:分词器自己根据业务需要选择,常见的ik,hanlp,jcseg等
然后修改managed-schema配置文件的filetype,当然也可以新增(其实可以理解为新增了一种solr字段类型,至于要在那个字段引用,在filed字段节点上配置type为当前类型即可)
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/> <analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/> </fieldType> <fieldType name="text_hp" class="solr.TextField"> <analyzer type="index"> <tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/> </analyzer> <analyzer type="query"> <tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/> </analyzer> </fieldType>
注:class就是分词器jar解压的src下的路径。
更改完成后,可以重启solr服务,然后进入主页访问查看分词效果,当然前提是你要有自己的solr实例(即solr库)

第二种方式是tomcat下自定义部署solr,需要将solr包中的webapps部分复制到tomcat环境中,进行配置,详情可以自己网上找一下,不赘述,分词器配置也是一样的。
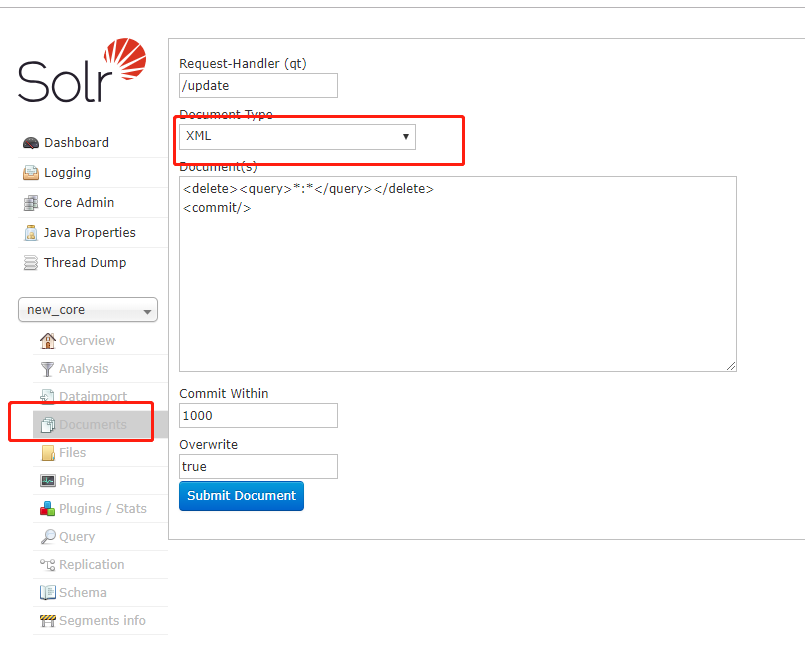
另外提一下solr删除全部索引数据的方法,在documents中,type选择xml,写上如下内容,点击提交,即可ok:
<delete><query>*:*</query></delete> <commit/>
至于查询方法,新增方法,查询排序,加权重,加匹配度等,自己查,懒得写了