这是一篇tesseract使用备忘录,其中主要论述限定要识别的文字
网址:
tesseract项目网址是:http://code.google.com/p/tesseract-ocr/
命令行的使用:
tesseract xxx.jpg result.txt -psm 7 digit
解释
tesseract 命令名
xxx.jpg 文件名,jpg,png都可以
result.txt 识别出的文字输出到文件
-psm 7 digit 参数
限定要识别的文字
例如要识别身份证号码,一般身份证号码为数字0到9还有大写的X,
加了限定以后,识别的准确率有所提升
例如识别身份证的一部分:

不加限定前,识别成1.3250
加了只能识别数字和X后,识别成:43250
具体方法:
打开tesseract安装目录,进入
tessdata/configs/
将digits复制一份,改名为:sfz,表示增加一份识别身份证规则的配置
使用文字编辑工具,打开文件sfz
在tessedit_char_whitelist 后面跟随要识别的字符
例如
tessedit_char_whitelist 0123456789X保存退出
这个就是白名单,想识别的文字或者符号就写进去
识别的时候,需要在命令里加上sfz配置,例如
tesseract xxx.jpg result -psm 7 sfzpython代码:
import pytesseract
from PIL import Image
image = Image.open("../pic/c.png")
card_no = tess.image_to_string(cardImage,config='-psm 7 sfz')
print(card_no)language的设置
此外,关于image_to_string ,还有langeuage参数设定语言
code = pytesseract.image_to_string(image,lang="chi_sim",config="-psm 6")语言叠加
还可以叠加语言包,例如你要识别的文字里,可能有中文和英文,可以这样设置:
code = pytesseract.image_to_string(image,lang="chi_sim+eng",config="-psm 6")
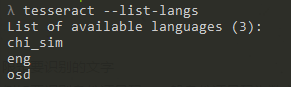
查看本地语言包
可以通过tesseract --list-langs查看本地语言包:
-psm的说明
关于config中 -psm配置项的说明可以通过tesseract --help-psm 查看psm
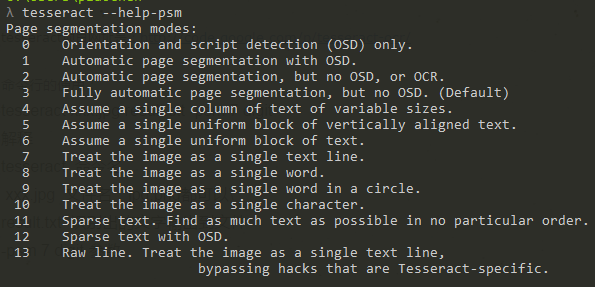
在网上找到了0-10项的中文说明(另外几项没找到...),如下:
0:定向脚本监测(OSD)
1: 使用OSD自动分页
2 :自动分页,但是不使用OSD或OCR(Optical Character Recognition,光学字符识别)
3 :全自动分页,但是没有使用OSD(默认)
4 :假设可变大小的一个文本列。
5 :假设垂直对齐文本的单个统一块。
6 :假设一个统一的文本块。
7 :将图像视为单个文本行。
8 :将图像视为单个词。
9 :将图像视为圆中的单个词。
10 :将图像视为单个字符。
本文部分参考:http://blog.csdn.net/github_33304260/article/details/79155154?from=singlemessage