原文链接:https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Background-Machine-Learning.md
背景:机器学习
鉴于许多ML-Agents的用户可能没有正式的机器学习背景,本页提供了一个概述来帮助理解ML-Agents。当然,我们不会在这里提供机器学习的所有信息,因为网上有绝佳的资源。
机器学习是人工智能的一个分支,侧重于从数据中学习模式。机器学习算法的三大类包括:无监督学习,监督学习和强化学习。每类算法都从不同类型的数据中学习。以下段落提供了这些机器学习类别的概述,
以及相关例子。
无监督学习
无监督学习的目标是对数据集中的相似项目进行分组或归类。例如,考虑游戏的玩家。我们可能希望根据玩家对游戏的参与程度对玩家进行分组。这将使我们能够定位不同的群体(例如,对于高参与的玩家,我们可能邀请他们成为新功能的beta测试人员,
,而对于未参与的玩家,我们可能会向他们发送有用的教程)。假设我们希望将我们的玩家分成两组。我们首先定义玩家的基本属性,例如玩过的小时数,在应用程序内购买的花费总额以及完成的等级数。
然后,我们可以将这个数据集(每个玩家的三个属性)提供给一个无监督的学习算法,其中我们将组的数量指定为两个。该算法随后将玩家的数据集分成两组,其中每组中的玩家将彼此相似。鉴于我们提供用来描述每个玩家的属性,
在这种情况下,最后的输出将是所有玩家被分成两组,其中一组将代表参与的玩家,并且第二组将代表未参与的玩家。
对于无监督学习,我们没有提供具体的例子,哪些球员被认为是参与的,哪些被认为是未参与的。我们只是定义了适当的属性,并依靠算法自行揭示这两个组。因为缺少直接标签,这类数据集通常称为无标签数据集。所以,
无监督学习可能对标签难以定义的情况有所帮助。在下一段中,我们概述了除属性外还接受输入标签的有监督学习算法。
监督学习
在有监督的学习中,我们不想仅仅分组类似的项目,而是直接学习每个项目与它所属的组(或类别)的映射。回到我们先前归类玩家的例子,假设我们现在希望预测哪些玩家即将流失(即在未来30天内停止玩游戏)。
我们可以查看我们的历史记录,并创建一个包含我们玩家属性的数据集,以及一个表明他们是否流失的标签。请注意,我们用于此流失预测任务的玩家属性可能与我们之前的归类任务中使用的玩家属性不同。
我们可以将这个数据集(每个玩家的属性和标签)反馈到一个监督式学习算法中,该算法可以学习从玩家属性到表示该玩家是否会流失的标签的映射。
直观上说监督式学习算法将会了解这些属性的哪些值通常对应于已经流失和没有流失的玩家(例如,它可能学习到花费很少并且玩非常短的时间的玩家很可能会流失)。现在有了这个学习模型,
我们可以为其提供新玩家(刚开始玩游戏的玩家)的属性,而它会输出该玩家的预测标签。这个预测是通过算法得到玩家是否会流失的结果。
我们现在可以使用这些预测来针对那些预计会流失的玩家,并吸引他们继续玩游戏。
正如您可能已经注意到的,对于有监督和无监督学习,需要执行两个任务:属性选择和模型选择。
属性选择(也称为特征选择)涉及对我们如何表现对事物的兴趣的选择,在这个例子里,指的是玩家。另一方面,模型选择涉及选择能够很好地执行任务的算法(及其参数)。这两项任务都是机器学习研究的活跃领域,
在实践中,需要多次迭代才能获得良好的性能。
我们现在转向强化学习,这是第三类机器学习算法,可以说是ML-Agents最相关的一个。
强化学习
强化学习可以被看作是一种顺序决策制定的学习形式,通常与控制机器人相关(但事实上,更普遍)。假设一个自动消防机器人,负责导航到一个地区,发现火灾并将其灭掉。在任何特定时刻,
机器人通过其传感器(例如照相机,热传感,触摸)感知环境,处理这些信息并产生动作(例如向左移动,旋转水管,打开水)。换句话说,鉴于其对世界的观察(传感器输入)和任务(即灭火),它正在不断地决定如何在这个环境中进行交互。
训练一个机器人成为成功的消防机器人正是强化学习的目的。
更具体地说,强化学习的目标是学习一项策略,其实质上是从观察到行动的映射。
观察是指机器人可以从其环境(在这种情况下,其所有传感器输入)中测量的结果和行动,其最原始形式,是对机器人状态的改变(例如其本身的位置,其水管位置以及水管是打开还是关闭)。
强化学习任务的最后一块是奖励信号。当训练一个机器人成为一个消防机器人,我们给它提供奖励(正面和负面),表明它在完成任务时的表现。请注意,机器人在训练之前不知道如何扑灭火灾。
它学习任务,因为它在扑灭火焰时收到很大的正面报酬,而每过一秒就收到一小笔负面报酬。事实上奖励会稀少(即不能在每一步都提供,而只有当机器人到达成功或失败的情况下),
这是强化学习的决定性特征,也正是为什么学习好的策略对于复杂环境可能很困难(和/或耗时)的原因。
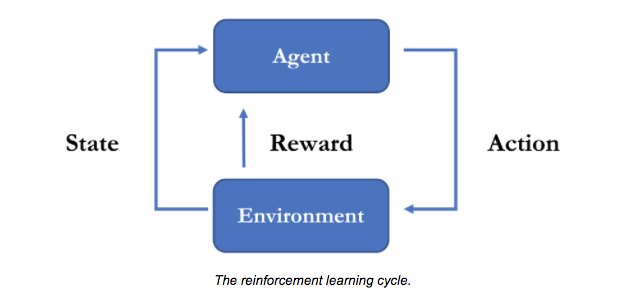
学习策略通常需要许多试验和对策略不断迭代更新。更具体地说,机器人处于几种火灾情况下,随着时间的推移,学习了一个最佳策略,使它能够更有效地扑灭我们的火灾。显然,我们不能指望在现实世界中反复训练机器人,尤其是在涉及火灾时。
这就是为什么使用Unity作为模拟器作为学习此类行为的理想训练场所。虽然我们关于强化学习的讨论集中在机器人上,但机器人和角色之间在游戏中有很强的相似之处。事实上,从很多方面来看,
不可玩角色(NPC)作为一个虚拟机器人,具有自己对环境的观察,自己的一套行为和一个特定的目标。因此,探索如何使用强化学习来训练Unity中的行为是很自然的。这也正是ML-Agents所提供的。
下面链接的视频包括强化学习演示,展示使用ML-Agents的训练角色行为。
类似于无监督学习和监督学习,强化学习也涉及两个任务:属性选择和模型选择。属性选择定义了机器人的一组观察数据,最有助于完成其目标,
而模型选择则定义了策略的形式(从观察到行动的映射)及其参数。在实践中,训练行为是一个迭代过程,可能需要改变属性和模型选择。
训练和推断
机器学习全部三个分支的一个共同方面是它们都涉及训练阶段和推理阶段。虽然训练和推断阶段的细节在三个层次中都各不相同,但在高层次上,训练阶段涉及使用提供的数据构建模型,
而推理阶段涉及将此模型应用于以前未曾见过的新数据。进一步来说:
-
对于我们的无监督学习示例,训练阶段根据描述现有球员的数据来学习最优的两个球队,而推理阶段将新球员分配给这两个球队中的一个。
-
对于我们的监督式学习示例,训练阶段会学习从玩家属性到玩家标签的映射(无论它们是否流失),并且推理阶段基于学习的映射预测新玩家是否会流失。
- 对于我们强化学习的例子,训练阶段通过指导性试验来学习最优策略,并且在推理阶段,Agent使用其学习策略观察和行动。
简要总结:除了属性和模型选择之外,所有三类算法都涉及训练和推理阶段。最终将它们分开的是可供学习的数据类型。在无监督学习中,我们的数据集是属性的集合,在监督学习中,我们的数据集是属性-标签对的集合,最后,在强化学习中,我们的数据集合是观察-行为-奖励的集合。
深度学习
深度学习是一系列算法,可用于解决上述任何问题。更具体地说,它们可以用来处理属性和模型选择任务。由于其在几项具有挑战性的机器学习任务方面的出色表现,近年来深度学习越来越受欢迎。 AlphaGo就是一个例子,
一个电脑围棋程序,利用深度学习,它能够击败李世杰(一个去世界冠军)。
深度学习算法的一个关键特征是它们能够从大量的训练数据中学习非常复杂的功能。
这使得当有大量数据生成时,它们成为强化学习任务的自然而然的一个选择,例如通过使用仿真器或引擎(如Unity)。通过在Unity中生成数十万个模拟环境,
我们可以学习非常复杂的环境策略(复杂的环境是指一个Agent感知的观察次数和他们可以采取的行动数量都很大的环境)。我们在ML-Agents中提供的许多算法都使用某种形式的深度学习,它建立在开源库TensorFlow之上。